day07.HDFS学习大数据教程
Posted Java帮帮
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了day07.HDFS学习大数据教程相关的知识,希望对你有一定的参考价值。
day07.HDFS学习【大数据教程】
******HDFS基本概念篇******
1. HDFS前言
设计思想
分而治之:将大文件、大批量文件,分布式存放在大量服务器上,以便于采取分而治之的方式对海量数据进行运算分析;
在大数据系统中作用:
为各类分布式运算框架(如:mapreduce,spark,tez,……)提供数据存储服务
重点概念:文件切块,副本存放,元数据
2. HDFS的概念和特性
首先,它是一个文件系统,用于存储文件,通过统一的命名空间——目录树来定位文件
其次,它是分布式的,由很多服务器联合起来实现其功能,集群中的服务器有各自的角色;
重要特性如下:
(1)HDFS中的文件在物理上是分块存储(block),块的大小可以通过配置参数( dfs.blocksize)来规定,默认大小在hadoop2.x版本中是128M,老版本中是64M
(2)HDFS文件系统会给客户端提供一个统一的抽象目录树,客户端通过路径来访问文件,形如:hdfs://namenode:port/dir-a/dir-b/dir-c/file.data
(3)目录结构及文件分块信息(元数据)的管理由namenode节点承担
——namenode是HDFS集群主节点,负责维护整个hdfs文件系统的目录树,以及每一个路径(文件)所对应的block块信息(block的id,及所在的datanode服务器)
(4)文件的各个block的存储管理由datanode节点承担
---- datanode是HDFS集群从节点,每一个block都可以在多个datanode上存储多个副本(副本数量也可以通过参数设置dfs.replication)
(5)HDFS是设计成适应一次写入,多次读出的场景,且不支持文件的修改
(注:适合用来做数据分析,并不适合用来做网盘应用,因为,不便修改,延迟大,网络开销大,成本太高)
******HDFS基本操作篇******
3. HDFS的shell(命令行客户端)操作
3.1 HDFS命令行客户端使用
HDFS提供shell命令行客户端,使用方法如下:

3.2 命令行客户端支持的命令参数
[-appendToFile <localsrc> ... <dst>] [-cat [-ignoreCrc] <src> ...] [-checksum <src> ...] [-chgrp [-R] GROUP PATH...] [-chmod [-R] <MODE[,MODE]... | OCTALMODE> PATH...] [-chown [-R] [OWNER][:[GROUP]] PATH...] [-copyFromLocal [-f] [-p] <localsrc> ... <dst>] [-copyToLocal [-p] [-ignoreCrc] [-crc] <src> ... <localdst>] [-count [-q] <path> ...] [-cp [-f] [-p] <src> ... <dst>] [-createSnapshot <snapshotDir> [<snapshotName>]] [-deleteSnapshot <snapshotDir> <snapshotName>] [-df [-h] [<path> ...]] [-du [-s] [-h] <path> ...] [-expunge] [-get [-p] [-ignoreCrc] [-crc] <src> ... <localdst>] [-getfacl [-R] <path>] [-getmerge [-nl] <src> <localdst>] [-help [cmd ...]] [-ls [-d] [-h] [-R] [<path> ...]] [-mkdir [-p] <path> ...] [-moveFromLocal <localsrc> ... <dst>] [-moveToLocal <src> <localdst>] [-mv <src> ... <dst>] [-put [-f] [-p] <localsrc> ... <dst>] [-renameSnapshot <snapshotDir> <oldName> <newName>] [-rm [-f] [-r|-R] [-skipTrash] <src> ...] [-rmdir [--ignore-fail-on-non-empty] <dir> ...] [-setfacl [-R] [{-b|-k} {-m|-x <acl_spec>} <path>]|[--set <acl_spec> <path>]] [-setrep [-R] [-w] <rep> <path> ...] [-stat [format] <path> ...] [-tail [-f] <file>] [-test -[defsz] <path>] [-text [-ignoreCrc] <src> ...] [-touchz <path> ...] [-usage [cmd ...]] |
3.2 常用命令参数介绍
-help 功能:输出这个命令参数手册 |
-ls 功能:显示目录信息 示例: hadoop fs -ls hdfs://hadoop-server01:9000/ 备注:这些参数中,所有的hdfs路径都可以简写 -->hadoop fs -ls / 等同于上一条命令的效果 |
-mkdir 功能:在hdfs上创建目录 示例:hadoop fs -mkdir -p /aaa/bbb/cc/dd |
-moveFromLocal 功能:从本地剪切粘贴到hdfs 示例:hadoop fs - moveFromLocal /home/hadoop/a.txt /aaa/bbb/cc/dd -moveToLocal 功能:从hdfs剪切粘贴到本地 示例:hadoop fs - moveToLocal /aaa/bbb/cc/dd /home/hadoop/a.txt |
--appendToFile 功能:追加一个文件到已经存在的文件末尾 示例:hadoop fs -appendToFile ./hello.txt hdfs://hadoop-server01:9000/hello.txt 可以简写为: Hadoop fs -appendToFile ./hello.txt /hello.txt |
-cat 功能:显示文件内容 示例:hadoop fs -cat /hello.txt
-tail 功能:显示一个文件的末尾 示例:hadoop fs -tail /weblog/access_log.1 -text 功能:以字符形式打印一个文件的内容 示例:hadoop fs -text /weblog/access_log.1 |
-chgrp -chmod -chown 功能:linux文件系统中的用法一样,对文件所属权限 示例: hadoop fs -chmod 666 /hello.txt hadoop fs -chown someuser:somegrp /hello.txt |
-copyFromLocal 功能:从本地文件系统中拷贝文件到hdfs路径去 示例:hadoop fs -copyFromLocal ./jdk.tar.gz /aaa/ -copyToLocal 功能:从hdfs拷贝到本地 示例:hadoop fs -copyToLocal /aaa/jdk.tar.gz |
-cp 功能:从hdfs的一个路径拷贝hdfs的另一个路径 示例: hadoop fs -cp /aaa/jdk.tar.gz /bbb/jdk.tar.gz.2
-mv 功能:在hdfs目录中移动文件 示例: hadoop fs -mv /aaa/jdk.tar.gz / |
-get 功能:等同于copyToLocal,就是从hdfs下载文件到本地 示例:hadoop fs -get /aaa/jdk.tar.gz -getmerge 功能:合并下载多个文件 示例:比如hdfs的目录 /aaa/下有多个文件:log.1, log.2,log.3,... hadoop fs -getmerge /aaa/log.* ./log.sum |
-put 功能:等同于copyFromLocal 示例:hadoop fs -put /aaa/jdk.tar.gz /bbb/jdk.tar.gz.2 |
-rm 功能:删除文件或文件夹 示例:hadoop fs -rm -r /aaa/bbb/
-rmdir 功能:删除空目录 示例:hadoop fs -rmdir /aaa/bbb/ccc |
-df 功能:统计文件系统的可用空间信息 示例:hadoop fs -df -h /
-du 功能:统计文件夹的大小信息 示例: hadoop fs -du -s -h /aaa/* |
-count 功能:统计一个指定目录下的文件节点数量 示例:hadoop fs -count /aaa/ |
-setrep 功能:设置hdfs中文件的副本数量 示例:hadoop fs -setrep 3 /aaa/jdk.tar.gz |
******HDFS原理篇******
4. hdfs的工作机制
(工作机制的学习主要是为加深对分布式系统的理解,以及增强遇到各种问题时的分析解决能力,形成一定的集群运维能力)
注:很多不是真正理解hadoop技术体系的人会常常觉得HDFS可用于网盘类应用,但实际并非如此。要想将技术准确用在恰当的地方,必须对技术有深刻的理解
4.1 概述
1. HDFS集群分为两大角色:NameNode、DataNode (Secondary Namenode)
2. NameNode负责管理整个文件系统的元数据
3. DataNode 负责管理用户的文件数据块
4. 文件会按照固定的大小(blocksize)切成若干块后分布式存储在若干台datanode上
5. 每一个文件块可以有多个副本,并存放在不同的datanode上
6. Datanode会定期向Namenode汇报自身所保存的文件block信息,而namenode则会负责保持文件的副本数量
7. HDFS的内部工作机制对客户端保持透明,客户端请求访问HDFS都是通过向namenode申请来进行
4.2 HDFS写数据流程
4.2.1 概述
客户端要向HDFS写数据,首先要跟namenode通信以确认可以写文件并获得接收文件block的datanode,然后,客户端按顺序将文件逐个block传递给相应datanode,并由接收到block的datanode负责向其他datanode复制block的副本
4.2.2 详细步骤图
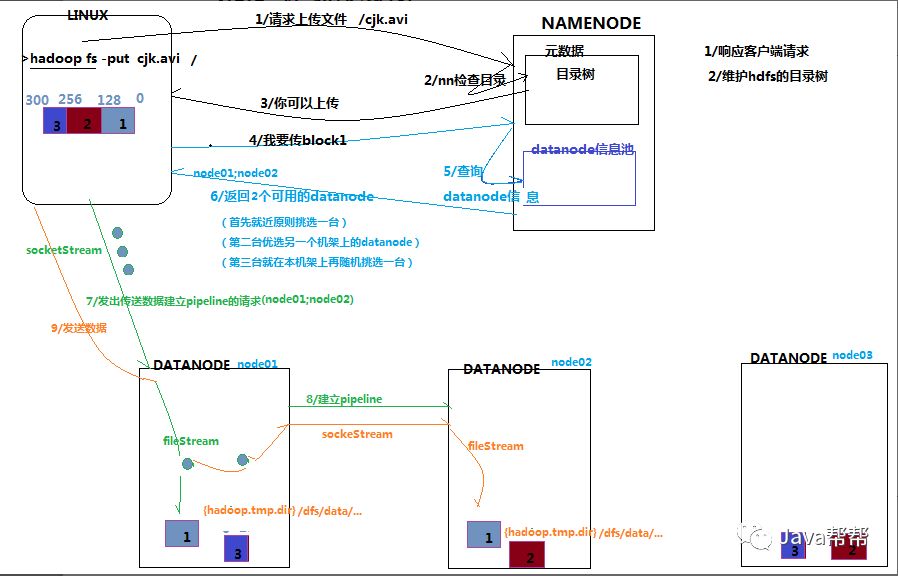
4.2.3 详细步骤解析
1、根namenode通信请求上传文件,namenode检查目标文件是否已存在,父目录是否存在
2、namenode返回是否可以上传
3、client请求第一个 block该传输到哪些datanode服务器上
4、namenode返回3个datanode服务器ABC
5、client请求3台dn中的一台A上传数据(本质上是一个RPC调用,建立pipeline),A收到请求会继续调用B,然后B调用C,将真个pipeline建立完成,逐级返回客户端
6、client开始往A上传第一个block(先从磁盘读取数据放到一个本地内存缓存),以packet为单位,A收到一个packet就会传给B,B传给C;A每传一个packet会放入一个应答队列等待应答
7、当一个block传输完成之后,client再次请求namenode上传第二个block的服务器。
4.3. HDFS读数据流程
4.3.1 概述
客户端将要读取的文件路径发送给namenode,namenode获取文件的元信息(主要是block的存放位置信息)返回给客户端,客户端根据返回的信息找到相应datanode逐个获取文件的block并在客户端本地进行数据追加合并从而获得整个文件
4.3.2 详细步骤图
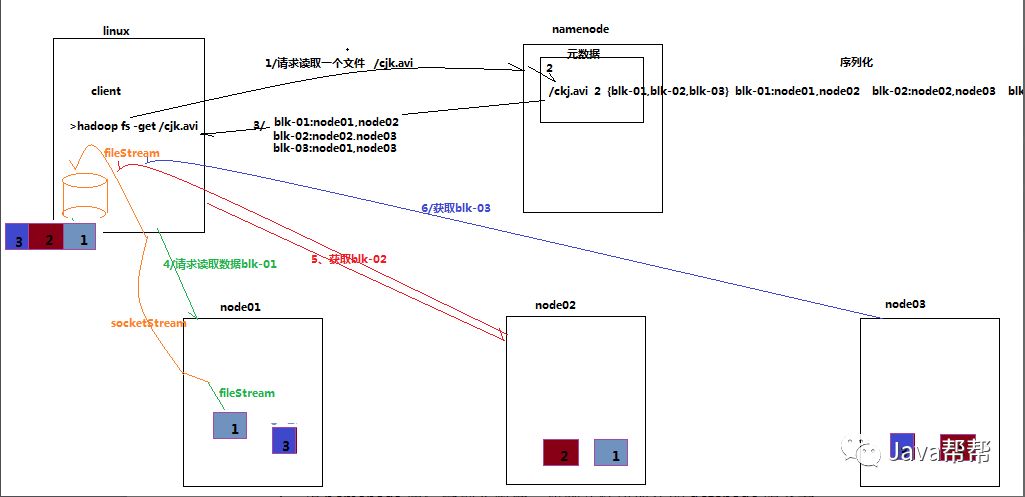
4.3.3 详细步骤解析
1、跟namenode通信查询元数据,找到文件块所在的datanode服务器
2、挑选一台datanode(就近原则,然后随机)服务器,请求建立socket流
3、datanode开始发送数据(从磁盘里面读取数据放入流,以packet为单位来做校验)
4、客户端以packet为单位接收,现在本地缓存,然后写入目标文件
5. NAMENODE工作机制
学习目标:理解namenode的工作机制尤其是元数据管理机制,以增强对HDFS工作原理的理解,及培养hadoop集群运营中“性能调优”、“namenode”故障问题的分析解决能力
问题场景:
1、集群启动后,可以查看文件,但是上传文件时报错,打开web页面可看到namenode正处于safemode状态,怎么处理?
2、Namenode服务器的磁盘故障导致namenode宕机,如何挽救集群及数据?
3、Namenode是否可以有多个?namenode内存要配置多大?namenode跟集群数据存储能力有关系吗?
4、文件的blocksize究竟调大好还是调小好?
……
诸如此类问题的回答,都需要基于对namenode自身的工作原理的深刻理解
5.1 NAMENODE职责
NAMENODE职责:
负责客户端请求的响应
元数据的管理(查询,修改)
5.2 元数据管理
namenode对数据的管理采用了三种存储形式:
内存元数据(NameSystem)
磁盘元数据镜像文件
数据操作日志文件(可通过日志运算出元数据)
5.2.1 元数据存储机制
A、内存中有一份完整的元数据(内存meta data)
B、磁盘有一个“准完整”的元数据镜像(fsimage)文件(在namenode的工作目录中)
C、用于衔接内存metadata和持久化元数据镜像fsimage之间的操作日志(edits文件)
注:当客户端对hdfs中的文件进行新增或者修改操作,操作记录首先被记入edits日志文件中,当客户端操作成功后,相应的元数据会更新到内存meta.data中
5.2.2 元数据手动查看
可以通过hdfs的一个工具来查看edits中的信息
bin/hdfs oev -i edits -o edits.xml
bin/hdfs oiv -i fsimage_0000000000000000087 -p XML -o fsimage.xml
5.2.3 元数据的checkpoint
每隔一段时间,会由secondary namenode将namenode上积累的所有edits和一个最新的fsimage下载到本地,并加载到内存进行merge(这个过程称为checkpoint)
checkpoint的详细过程
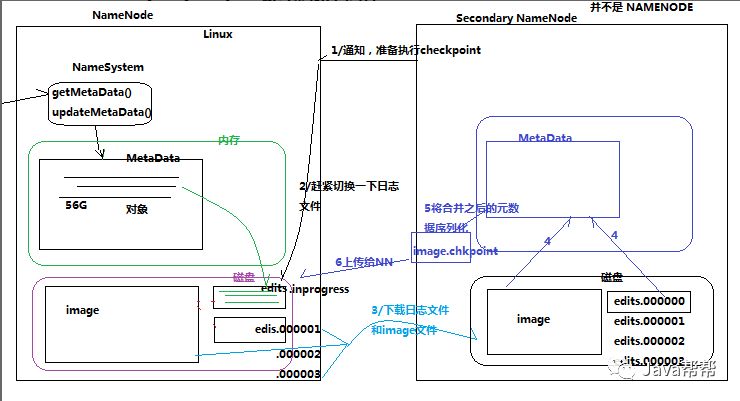
checkpoint操作的触发条件配置参数
dfs.namenode.checkpoint.check.period=60 #检查触发条件是否满足的频率,60秒 dfs.namenode.checkpoint.dir=file://${hadoop.tmp.dir}/dfs/namesecondary #以上两个参数做checkpoint操作时,secondary namenode的本地工作目录 dfs.namenode.checkpoint.edits.dir=${dfs.namenode.checkpoint.dir} dfs.namenode.checkpoint.max-retries=3 #最大重试次数 dfs.namenode.checkpoint.period=3600 #两次checkpoint之间的时间间隔3600秒 dfs.namenode.checkpoint.txns=1000000 #两次checkpoint之间最大的操作记录 |
checkpoint的附带作用
namenode和secondary namenode的工作目录存储结构完全相同,所以,当namenode故障退出需要重新恢复时,可以从secondary namenode的工作目录中将fsimage拷贝到namenode的工作目录,以恢复namenode的元数据
5.2.4 元数据目录说明
在第一次部署好Hadoop集群的时候,我们需要在NameNode(NN)节点上格式化磁盘:
$HADOOP_HOME/bin/hdfs namenode -format |
格式化完成之后,将会在$dfs.namenode.name.dir/current目录下如下的文件结构
current/ |-- VERSION |-- edits_* |-- fsimage_0000000000008547077 |-- fsimage_0000000000008547077.md5 `-- seen_txid |
其中的dfs.name.dir是在hdfs-site.xml文件中配置的,默认值如下:
<property> <name>dfs.name.dir</name> <value>file://${hadoop.tmp.dir}/dfs/name</value> </property>
hadoop.tmp.dir是在core-site.xml中配置的,默认值如下 <property> <name>hadoop.tmp.dir</name> <value>/tmp/hadoop-${user.name}</value> <description>A base for other temporary directories.</description> </property> |
dfs.namenode.name.dir属性可以配置多个目录,
如/data1/dfs/name,/data2/dfs/name,/data3/dfs/name,....。各个目录存储的文件结构和内容都完全一样,相当于备份,这样做的好处是当其中一个目录损坏了,也不会影响到Hadoop的元数据,特别是当其中一个目录是NFS(网络文件系统Network File System,NFS)之上,即使你这台机器损坏了,元数据也得到保存。
下面对$dfs.namenode.name.dir/current/目录下的文件进行解释。
1.VERSION文件是Java属性文件,内容大致如下:
#Fri Nov 15 19:47:46 CST 2013 namespaceID=934548976 clusterID=CID-cdff7d73-93cd-4783-9399-0a22e6dce196 cTime=0 storageType=NAME_NODE blockpoolID=BP-893790215-192.168.24.72-1383809616115 layoutVersion=-47 |
其中
(1)namespaceID是文件系统的唯一标识符,在文件系统首次格式化之后生成的;
(2)storageType说明这个文件存储的是什么进程的数据结构信息(如果是DataNode,storageType=DATA_NODE);
(3)cTime表示NameNode存储时间的创建时间,由于我的NameNode没有更新过,所以这里的记录值为0,以后对NameNode升级之后,cTime将会记录更新时间戳;
(4)layoutVersion表示HDFS永久性数据结构的版本信息, 只要数据结构变更,版本号也要递减,此时的HDFS也需要升级,否则磁盘仍旧是使用旧版本的数据结构,这会导致新版本的NameNode无法使用;
(5)clusterID是系统生成或手动指定的集群ID,在-clusterid选项中可以使用它;如下说明
a.使用如下命令格式化一个Namenode:
$HADOOP_HOME/bin/hdfs namenode -format [-clusterId <cluster_id>]
选择一个唯一的cluster_id,并且这个cluster_id不能与环境中其他集群有冲突。如果没有提供cluster_id,则会自动生成一个唯一的ClusterID。
b.使用如下命令格式化其他Namenode:
$HADOOP_HOME/bin/hdfs namenode -format -clusterId <cluster_id>
c.升级集群至最新版本。在升级过程中需要提供一个ClusterID,例如:
$HADOOP_PREFIX_HOME/bin/hdfs start namenode --config $HADOOP_CONF_DIR -upgrade -clusterId <cluster_ID>
如果没有提供ClusterID,则会自动生成一个ClusterID。
2、$dfs.namenode.name.dir/current/seen_txid非常重要
是存放transactionId的文件,format之后是0,它代表的是namenode里面的edits_*文件的尾数,namenode重启的时候,会按照seen_txid的数字,循序从头跑edits_0000001~到seen_txid的数字。所以当你的hdfs发生异常重启的时候,一定要比对seen_txid内的数字是不是你edits最后的尾数,不然会发生建置namenode时metaData的资料有缺少,导致误删Datanode上多余Block的资讯。
3、$dfs.namenode.name.dir/current目录下在format的同时也会生成fsimage和edits文件,及其对应的md5校验文件。
补充:seen_txid
文件中记录的是edits滚动的序号,每次重启namenode时,namenode就知道要将哪些edits进行加载edits
6. DATANODE的工作机制
问题场景:
1、集群容量不够,怎么扩容?
2、如果有一些datanode宕机,该怎么办?
3、datanode明明已启动,但是集群中的可用datanode列表中就是没有,怎么办?
以上这类问题的解答,有赖于对datanode工作机制的深刻理解
6.1 概述
1.Datanode工作职责:
存储管理用户的文件块数据
定期向namenode汇报自身所持有的block信息(通过心跳信息上报)
(这点很重要,因为,当集群中发生某些block副本失效时,集群如何恢复block初始副本数量的问题)
<property> <name>dfs.blockreport.intervalMsec</name> <value>3600000</value> <description>Determines block reporting interval in milliseconds.</description> </property> |
2.Datanode掉线判断时限参数
datanode进程死亡或者网络故障造成datanode无法与namenode通信,namenode不会立即把该节点判定为死亡,要经过一段时间,这段时间暂称作超时时长。HDFS默认的超时时长为10分钟+30秒。如果定义超时时间为timeout,则超时时长的计算公式为:
timeout = 2 * heartbeat.recheck.interval + 10 * dfs.heartbeat.interval。
而默认的heartbeat.recheck.interval 大小为5分钟,dfs.heartbeat.interval默认为3秒。
需要注意的是hdfs-site.xml 配置文件中的heartbeat.recheck.interval的单位为毫秒,dfs.heartbeat.interval的单位为秒。所以,举个例子,如果heartbeat.recheck.interval设置为5000(毫秒),dfs.heartbeat.interval设置为3(秒,默认),则总的超时时间为40秒。
<property> <name>heartbeat.recheck.interval</name> <value>2000</value> </property> <property> <name>dfs.heartbeat.interval</name> <value>1</value> </property> |
6.2 观察验证DATANODE功能
上传一个文件,观察文件的block具体的物理存放情况:
在每一台datanode机器上的这个目录中能找到文件的切块:
/home/hadoop/app/hadoop-2.4.1/tmp/dfs/data/current/BP-193442119-192.168.2.120-1432457733977/current/finalized
******HDFS应用开发篇******
7. HDFS的java操作
hdfs在生产应用中主要是客户端的开发,其核心步骤是从hdfs提供的api中构造一个HDFS的访问客户端对象,然后通过该客户端对象操作(增删改查)HDFS上的文件
7.1 搭建开发环境
1.引入依赖
| <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-client</artifactId> <version>2.6.1</version></dependency>
|
注:如需手动引入jar包,hdfs的jar包----hadoop的安装目录的share下
2.window下开发的说明
建议在linux下进行hadoop应用的开发,不会存在兼容性问题。如在window上做客户端应用开发,需要设置以下环境:
A、在windows的某个目录下解压一个hadoop的安装包
B、将安装包下的lib和bin目录用对应windows版本平台编译的本地库替换
C、在window系统中配置HADOOP_HOME指向你解压的安装包
D、在windows系统的path变量中加入hadoop的bin目录
7.2 获取api中的客户端对象
在java中操作hdfs,首先要获得一个客户端实例
Configuration conf = new Configuration() FileSystem fs = FileSystem.get(conf) |
而我们的操作目标是HDFS,所以获取到的fs对象应该是DistributedFileSystem的实例;
get方法是从何处判断具体实例化那种客户端类呢?
——从conf中的一个参数 fs.defaultFS的配置值判断;
如果我们的代码中没有指定fs.defaultFS,并且工程classpath下也没有给定相应的配置,conf中的默认值就来自于hadoop的jar包中的core-default.xml,默认值为: file:///,则获取的将不是一个DistributedFileSystem的实例,而是一个本地文件系统的客户端对象
7.3 DistributedFileSystem实例对象所具备的方法
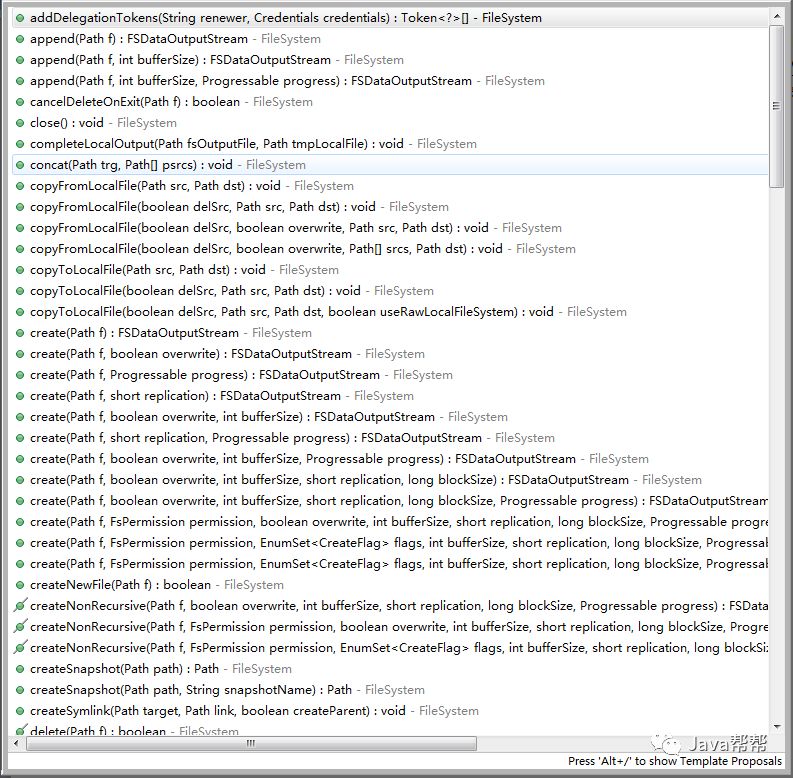
7.4 HDFS客户端操作数据代码示例:
7.4.1 文件的增删改查
public class HdfsClient { FileSystem fs = null; @Before public void init() throws Exception { // 构造一个配置参数对象,设置一个参数:我们要访问的hdfs的URI // new Configuration();的时候,它就会去加载jar包中的hdfs-default.xml // 然后再加载classpath下的hdfs-site.xml Configuration conf = new Configuration(); conf.set("fs.defaultFS", "hdfs://hdp-node01:9000"); /** * 参数优先级: 1、客户端代码中设置的值 2、classpath下的用户自定义配置文件 3、然后是服务器的默认配置 */ conf.set("dfs.replication", "3"); // 获取一个hdfs的访问客户端,根据参数,这个实例应该是DistributedFileSystem的实例 // fs = FileSystem.get(conf); // 如果这样去获取,那conf里面就可以不要配"fs.defaultFS"参数,而且,这个客户端的身份标识已经是hadoop用户 fs = FileSystem.get(new URI("hdfs://hdp-node01:9000"), conf, "hadoop"); }
/** * 往hdfs上传文件 * * @throws Exception */ @Test public void testAddFileToHdfs() throws Exception { // 要上传的文件所在的本地路径 Path src = new Path("g:/redis-recommend.zip"); // 要上传到hdfs的目标路径 Path dst = new Path("/aaa"); fs.copyFromLocalFile(src, dst); fs.close(); }
/** * 从hdfs中复制文件到本地文件系统 * * @throws IOException * @throws IllegalArgumentException */ @Test public void testDownloadFileToLocal() throws IllegalArgumentException, IOException { fs.copyToLocalFile(new Path("/jdk-7u65-linux-i586.tar.gz"), new Path("d:/")); fs.close(); } @Test public void testMkdirAndDeleteAndRename() throws IllegalArgumentException, IOException { // 创建目录 fs.mkdirs(new Path("/a1/b1/c1")); // 删除文件夹 ,如果是非空文件夹,参数2必须给值true fs.delete(new Path("/aaa"), true); // 重命名文件或文件夹 fs.rename(new Path("/a1"), new Path("/a2")); }
/** * 查看目录信息,只显示文件 * * @throws IOException * @throws IllegalArgumentException * @throws FileNotFoundException */ @Test public void testListFiles() throws FileNotFoundException, IllegalArgumentException, IOException { // 思考:为什么返回迭代器,而不是List之类的容器 RemoteIterator<LocatedFileStatus> listFiles = fs.listFiles(new Path("/"), true); while (listFiles.hasNext()) { LocatedFileStatus fileStatus = listFiles.next(); System.out.println(fileStatus.getPath().getName()); System.out.println(fileStatus.getBlockSize()); System.out.println(fileStatus.getPermission()); System.out.println(fileStatus.getLen()); BlockLocation[] blockLocations = fileStatus.getBlockLocations(); for (BlockLocation bl : blockLocations) { System.out.println("block-length:" + bl.getLength() + "--" + "block-offset:" + bl.getOffset()); String[] hosts = bl.getHosts(); for (String host : hosts) { System.out.println(host); } } System.out.println("--------------为angelababy打印的分割线--------------"); } }
/** * 查看文件及文件夹信息 * * @throws IOException * @throws IllegalArgumentException * @throws FileNotFoundException */ @Test public void testListAll() throws FileNotFoundException, IllegalArgumentException, IOException { FileStatus[] listStatus = fs.listStatus(new Path("/")); String flag = "d-- "; for (FileStatus fstatus : listStatus) { if (fstatus.isFile()) flag = "f-- "; System.out.println(flag + fstatus.getPath().getName()); } } } |
7.4.2 通过流的方式访问hdfs
/** * 相对那些封装好的方法而言的更底层一些的操作方式 * 上层那些mapreduce spark等运算框架,去hdfs中获取数据的时候,就是调的这种底层的api * @author * */ public class StreamAccess { FileSystem fs = null; @Before public void init() throws Exception { Configuration conf = new Configuration(); fs = FileSystem.get(new URI("hdfs://hdp-node01:9000"), conf, "hadoop"); } /** * 通过流的方式上传文件到hdfs * @throws Exception */ @Test public void testUpload() throws Exception { FSDataOutputStream outputStream = fs.create(new Path("/angelababy.love"), true); FileInputStream inputStream = new FileInputStream("c:/angelababy.love"); IOUtils.copy(inputStream, outputStream); } @Test public void testDownLoadFileToLocal() throws IllegalArgumentException, IOException{ //先获取一个文件的输入流----针对hdfs上的 FSDataInputStream in = fs.open(new Path("/jdk-7u65-linux-i586.tar.gz")); //再构造一个文件的输出流----针对本地的 FileOutputStream out = new FileOutputStream(new File("c:/jdk.tar.gz")); //再将输入流中数据传输到输出流 IOUtils.copyBytes(in, out, 4096); } /** * hdfs支持随机定位进行文件读取,而且可以方便地读取指定长度 * 用于上层分布式运算框架并发处理数据 * @throws IllegalArgumentException * @throws IOException */ @Test public void testRandomAccess() throws IllegalArgumentException, IOException{ //先获取一个文件的输入流----针对hdfs上的 FSDataInputStream in = fs.open(new Path("/iloveyou.txt")); //可以将流的起始偏移量进行自定义 in.seek(22); //再构造一个文件的输出流----针对本地的 FileOutputStream out = new FileOutputStream(new File("c:/iloveyou.line.2.txt")); IOUtils.copyBytes(in,out,19L,true); } /** * 显示hdfs上文件的内容 * @throws IOException * @throws IllegalArgumentException */ @Test public void testCat() throws IllegalArgumentException, IOException{ FSDataInputStream in = fs.open(new Path("/iloveyou.txt")); IOUtils.copyBytes(in, System.out, 1024); } } |
7.4.3 场景编程
在mapreduce 、spark等运算框架中,有一个核心思想就是将运算移往数据,或者说,就是要在并发计算中尽可能让运算本地化,这就需要获取数据所在位置的信息并进行相应范围读取
以下模拟实现:获取一个文件的所有block位置信息,然后读取指定block中的内容
@Test public void testCat() throws IllegalArgumentException, IOException{ FSDataInputStream in = fs.open(new Path("/weblog/input/access.log.10")); //拿到文件信息 FileStatus[] listStatus = fs.listStatus(new Path("/weblog/input/access.log.10")); //获取这个文件的所有block的信息 BlockLocation[] fileBlockLocations = fs.getFileBlockLocations(listStatus[0], 0L, listStatus[0].getLen()); //第一个block的长度 long length = fileBlockLocations[0].getLength(); //第一个block的起始偏移量 long offset = fileBlockLocations[0].getOffset(); System.out.println(length); System.out.println(offset); //获取第一个block写入输出流 // IOUtils.copyBytes(in, System.out, (int)length); byte[] b = new byte[4096]; FileOutputStream os = new FileOutputStream(new File("d:/block0")); while(in.read(offset, b, 0, 4096)!=-1){ os.write(b); offset += 4096; if(offset>=length) return; }; os.flush(); os.close(); in.close(); } |
8. 案例1:开发shell采集脚本
8.1需求说明
点击流日志每天都10T,在业务应用服务器上,需要准实时上传至数据仓库(Hadoop HDFS)上
8.2需求分析
一般上传文件都是在凌晨24点操作,由于很多种类的业务数据都要在晚上进行传输,为了减轻服务器的压力,避开高峰期。
如果需要伪实时的上传,则采用定时上传的方式
8.3技术分析
HDFS SHELL: hadoop fs –put xxxx.tar /data 还可以使用 Java Api
满足上传一个文件,不能满足定时、周期性传入。
定时调度器:
Linux crontab
crontab -e
*/5 * * * * $home/bin/command.sh //五分钟执行一次
系统会自动执行脚本,每5分钟一次,执行时判断文件是否符合上传规则,符合则上传
8.4实现流程
8.4.1日志产生程序
日志产生程序将日志生成后,产生一个一个的文件,使用滚动模式创建文件名。

日志生成的逻辑由业务系统决定,比如在log4j配置文件中配置生成规则,如:当xxxx.log 等于10G时,滚动生成新日志
log4j.logger.msg=info,msg log4j.appender.msg=cn.maoxiangyi.MyRollingFileAppender log4j.appender.msg.layout=org.apache.log4j.PatternLayout log4j.appender.msg.layout.ConversionPattern=%m%n log4j.appender.msg.datePattern='.'yyyy-MM-dd log4j.appender.msg.Threshold=info log4j.appender.msg.append=true log4j.appender.msg.encoding=UTF-8 log4j.appender.msg.MaxBackupIndex=100 log4j.appender.msg.MaxFileSize=10GB log4j.appender.msg.File=/home/hadoop/logs/log/access.log |
细节:
1.如果日志文件后缀是123等数字,该文件满足需求可以上传的话。把该文件移动到准备上传的工作区间。
2.工作区间有文件之后,可以使用hadoop put命令将文件上传。阶段问题:
1.待上传文件的工作区间的文件,在上传完成之后,是否需要删除掉。
8.4.2伪代码
使用ls命令读取指定路径下的所有文件信息,
ls | while read line
//判断line这个文件名称是否符合规则
if line=access.log.* (
将文件移动到待上传的工作区间
)
//批量上传工作区间的文件
hadoop fs –put xxx
脚本写完之后,配置linux定时任务,每5分钟运行一次。
8.5代码实现
代码第一版本,实现基本的上传功能和定时调度功能
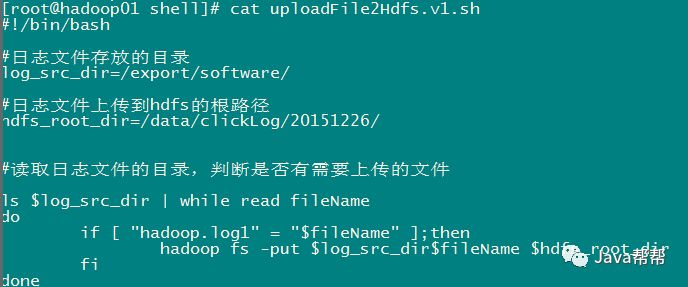
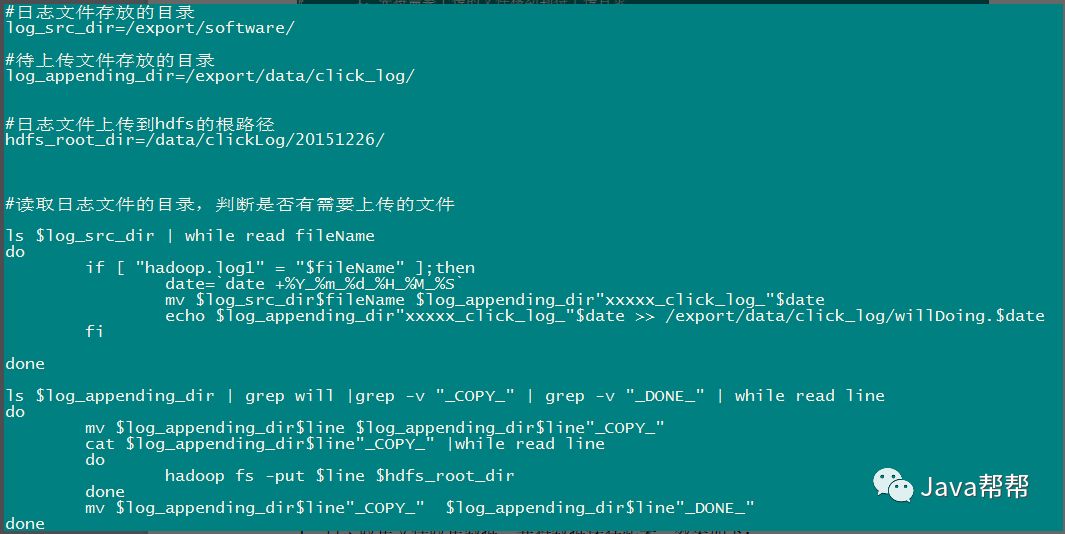
代码第二版本:增强版V2(基本能用,还是不够健全)

8.6效果展示及操作步骤
1.日志收集文件收集数据,并将数据保存起来,效果如下:

2.上传程序通过crontab定时调度

3.程序运行时产生的临时文件

4.Hadoo hdfs上的效果

9. 案例2:开发JAVA采集程序
9.1 需求
从外部购买数据,数据提供方会实时将数据推送到6台FTP服务器上,我方部署6台接口采集机来对接采集数据,并上传到HDFS中
提供商在FTP上生成数据的规则是以小时为单位建立文件夹(2016-03-11-10),每分钟生成一个文件(00.dat,01.data,02.dat,........)
提供方不提供数据备份,推送到FTP服务器的数据如果丢失,不再重新提供,且FTP服务器磁盘空间有限,最多存储最近10小时内的数据
由于每一个文件比较小,只有150M左右,因此,我方在上传到HDFS过程中,需要将15分钟时段的数据合并成一个文件上传到HDFS
为了区分数据丢失的责任,我方在下载数据时最好进行校验
9.2 设计分析
问题解决
1.HDFS冗余数据块的自动删除
在日常维护hadoop集群的过程中发现这样一种情况:
某个节点由于网络故障或者DataNode进程死亡,被NameNode判定为死亡,HDFS马上自动开始数据块的容错拷贝;当该节点重新添加到集群中时,由于该节点上的数据其实并没有损坏,所以造成了HDFS上某些block的备份数超过了设定的备份数。通过观察发现,这些多余的数据块经过很长的一段时间才会被完全删除掉,那么这个时间取决于什么呢?
该时间的长短跟数据块报告的间隔时间有关。Datanode会定期将当前该结点上所有的BLOCK信息报告给Namenode,参数dfs.blockreport.intervalMsec就是控制这个报告间隔的参数。
hdfs-site.xml文件中有一个参数:
<property>
<name>dfs.blockreport.intervalMsec</name>
<value>3600000</value>
<description>Determines block reporting interval in milliseconds.</description>
</property>
其中3600000为默认设置,3600000毫秒,即1个小时,也就是说,块报告的时间间隔为1个小时,所以经过了很长时间这些多余的块才被删除掉。通过实际测试发现,当把该参数调整的稍小一点的时候(60秒),多余的数据块确实很快就被删除了。
2.hadoop datanode节点超时时间设置
datanode进程死亡或者网络故障造成datanode无法与namenode通信,namenode不会立即把该节点判定为死亡,要经过一段时间,这段时间暂称作超时时长。HDFS默认的超时时长为10分钟+30秒。如果定义超时时间为timeout,则超时时长的计算公式为:
timeout = 2 * heartbeat.recheck.interval + 10 * dfs.heartbeat.interval。
而默认的heartbeat.recheck.interval 大小为5分钟,dfs.heartbeat.interval默认为3秒。
需要注意的是hdfs-site.xml 配置文件中的heartbeat.recheck.interval的单位为毫秒,dfs.heartbeat.interval的单位为秒。所以,举个例子,如果heartbeat.recheck.interval设置为5000(毫秒),dfs.heartbeat.interval设置为3(秒,默认),则总的超时时间为40秒。
hdfs-site.xml中的参数设置格式:
<property>
<name>heartbeat.recheck.interval</name>
<value>2000</value>
</property>
<property>
<name>dfs.heartbeat.interval</name>
<value>1</value>
</property>
3.hadoop的日志目录(/home/hadoop/app/hadoop-2.6.4/logs)
hadoop启动不正常
用浏览器访问namenode的50070端口,不正常,需要诊断问题出在哪里:
a.在服务器的终端命令行使用jps查看相关进程
(namenode1个节点 datanode3个节点 secondary namenode1个节点)
b.如果已经知道了启动失败的服务进程,进入到相关进程的日志目录下,查看日志,分析异常的原因
1).配置文件出错,saxparser exception; ——找到错误提示中所指出的配置文件检查修改即可
2).unknown host——主机名不认识,配置/etc/hosts文件即可,或者是配置文件中所用主机名跟实际不一致
3).directory 访问异常—— 检查namenode的工作目录,看权限是否正常
start-dfs.sh启动后,发现有datanode启动不正常
a)查看datanode的日志,看是否有异常,如果没有异常,手动将datanode启动起来
sbin/hadoop-daemon.sh start datanode
b)很有可能是slaves文件中就没有列出需要启动的datanode
c)排除上述两种情况后,基本上,能在日志中看到异常信息:
1).配置文件
2).ssh免密登陆没有配置好
3).datanode的身份标识跟namenode的集群身份标识不一致(删掉datanode的工作目录)
4.namenode安全模式问题
当namenode发现集群中的block丢失数量达到一个阀值时,namenode就进入安全模式状态,不再接受客户端的数据更新请求
在正常情况下,namenode也有可能进入安全模式:
集群启动时(namenode启动时)必定会进入安全模式,然后过一段时间会自动退出安全模式(原因是datanode汇报的过程有一段持续时间)
也确实有异常情况下导致的安全模式
原因:block确实有缺失
措施:可以手动让namenode退出安全模式,bin/hdfs dfsadmin -safemode leave
或者:调整safemode门限值: dfs.safemode.threshold.pct=0.999f
5.ntp时间服务同步问题
第一种方式:
同步到网络时间服务器
# ntpdate time.windows.com
将硬件时间设置为当前系统时间。
#hwclock –w
加入crontab:
30 8 * * * root /usr/sbin/ntpdate 192.168.0.1; /sbin/hwclock -w
每天的8:30将进行一次时间同步。
重启crond服务:
service crond restart
第二种方式
同步到局域网内部的一台时间同步服务器
一.搭建时间同步服务器
1.编译安装ntp server
rpm -qa | grep ntp
若没有找到,则说明没有安装ntp包,从光盘上找到ntp包,使用rpm -Uvh ntp***.rpm进行安装
2.修改ntp.conf配置文件
vi /etc/ntp.conf
①第一种配置:允许任何IP的客户机都可以进行时间同步
将“restrict default nomodify notrap noquery”
这行修改成:
restrict default nomodify notrap
配置文件示例:/etc/ntp.conf
②第二种配置:只允许192.168.211.***网段的客户机进行时间同步
在restrict default nomodify notrap noquery(表示默认拒绝所有IP的时间同步)之后增加一行:
restrict 192.168.211.0 mask 255.255.255.0 nomodify notrap
3.启动ntp服务
service ntpd start
开机启动服务
chkconfig ntpd on
4.ntpd启动后,客户机要等几分钟再与其进行时间同步,否则会提示“no server suitable for synchronization found”错误。
二.配置时间同步客户机
手工执行 ntpdate <ntp server> 来同步或者利用crontab来执行
crontab -e 0 21 * * * ntpdate 192.168.211.22 >> /root/ntpdate.log 2>&1
每天晚上9点进行同步
附:
当用ntpdate -d 来查询时会发现导致 no server suitable for synchronization found 的错误的信息有以下2个:
错误1.Server dropped: Strata too high
在ntp客户端运行ntpdate serverIP,出现no server suitable for synchronization found的错误。
在ntp客户端用ntpdate –d serverIP查看,发现有“Server dropped: strata too high”的错误,并且显示“stratum 16”。
而正常情况下stratum这个值得范围是“0~15”。
这是因为NTP server还没有和其自身或者它的server同步上。
以下的定义是让NTP Server和其自身保持同步,如果在/ntp.conf中定义的server都不可用时,将使用local时间作为ntp服务提供给ntp客户端。
server 127.127.1.0
fudge 127.127.1.0 stratum 8
在ntp server上重新启动ntp服务后,ntp server自身或者与其server的同步的需要一个时间段,这个过程可能是5分钟,在这个时间之内在客户端运行ntpdate命令时会产生no server suitable for synchronization found的错误。
那么如何知道何时ntp server完成了和自身同步的过程呢?
在ntp server上使用命令:
# watch ntpq -p
出现画面:
Every 2.0s: ntpq -p Thu Jul 10 02:28:32 2008
remote refid st t when poll reach delay offset jitter
==============================================================================
192.168.30.22 LOCAL(0) 8 u 22 64 1 2.113 179133. 0.001
LOCAL(0) LOCAL(0) 10 l 21 64 1 0.000 0.000 0.001
注意:LOCAL的这个就是与自身同步的ntp server。
注意:reach这个值,在启动ntp server服务后,这个值就从0开始不断增加,当增加到17的时候,从0到17是5次的变更,每一次是poll的值的秒数,是64秒*5=320秒的时间。
如果之后从ntp客户端同步ntp server还失败的话,用ntpdate –d来查询详细错误信息,再做判断。
6.Hadoop机器感知
1).背景
Hadoop在设计时考虑到数据的安全与高效,数据文件默认在HDFS上存放三份,存储策略为本地一份,同机架内其它某一节点上一份,不同机架的某一节点上一份。这样如果本地数据损坏,节点可以从同一机架内的相邻节点拿到数据,速度肯定比从跨机架节点上拿数据要快;同时,如果整个机架的网络出现异常,也能保证在其它机架的节点上找到数据。为了降低整体的带宽消耗和读取延时,HDFS会尽量让读取程序读取离它最近的副本。如果在读取程序的同一个机架上有一个副本,那么就读取该副本。如果一个HDFS集群跨越多个数据中心,那么客户端也将首先读本地数据中心的副本。那么Hadoop是如何确定任意两个节点是位于同一机架,还是跨机架的呢?答案就是机架感知。
默认情况下,hadoop的机架感知是没有被启用的。所以,在通常情况下,hadoop集群的HDFS在选机器的时候,是随机选择的,也就是说,很有可能在写数据时,hadoop将第一块数据block1写到了rack1上,然后随机的选择下将block2写入到了rack2下,此时两个rack之间产生了数据传输的流量,再接下来,在随机的情况下,又将block3重新又写回了rack1,此时,两个rack之间又产生了一次数据流量。在job处理的数据量非常的大,或者往hadoop推送的数据量非常大的时候,这种情况会造成rack之间的网络流量成倍的上升,成为性能的瓶颈,进而影响作业的性能以至于整个集群的服务
2).配置
默认情况下,namenode启动时候日志是这样的:
2013-09-22 17:27:26,423 INFO org.apache.hadoop.net.NetworkTopology: Adding a new node: /default-rack/ 192.168.147.92:50010
每个IP 对应的机架ID都是 /default-rack ,说明hadoop的机架感知没有被启用。
要将hadoop机架感知的功能启用,配置非常简单,在 NameNode所在节点的/home/bigdata/apps/hadoop/etc/hadoop的core-site.xml配置文件中配置一个选项:
<property>
<name>topology.script.file.name</name>
<value>/home/bigdata/apps/hadoop/etc/hadoop/topology.sh</value>
</property>
#!/bin/bash
HADOOP_CONF=/home/bigdata/apps/hadoop/etc/hadoop
while [ $# -gt 0 ] ; do
nodeArg=$1
exec<${HADOOP_CONF}/topology.data
result=""
while read line ; do
ar=( $line )
if [ "${ar[0]}" = "$nodeArg" ]||[ "${ar[1]}" = "$nodeArg" ]; then
result="${ar[2]}"
fi
done
shift
if [ -z "$result" ] ; then
echo -n "/default-rack"
else
echo -n "$result"
fi
done
topology.data,格式为:节点(ip或主机名) /交换机xx/机架xx
192.168.147.91 tbe192168147091 /dc1/rack1
192.168.147.92 tbe192168147092 /dc1/rack1
192.168.147.93 tbe192168147093 /dc1/rack2
192.168.147.94 tbe192168147094 /dc1/rack3
192.168.147.95 tbe192168147095 /dc1/rack3
192.168.147.96 tbe192168147096 /dc1/rack3
需要注意的是,在Namenode上,该文件中的节点必须使用IP,使用主机名无效,而Jobtracker上,该文件中的节点必须使用主机名,使用IP无效,所以,最好ip和主机名都配上。
这样配置后,namenode启动时候日志是这样的:
2013-09-23 17:16:27,272 INFO org.apache.hadoop.net.NetworkTopology: Adding a new node: /dc1/rack3/ 192.168.147.94:50010
说明hadoop的机架感知已经被启用了。
查看HADOOP机架信息命令:
./hadoop dfsadmin -printTopology
Rack: /dc1/rack1
192.168.147.91:50010 (tbe192168147091)
192.168.147.92:50010 (tbe192168147092)
Rack: /dc1/rack2
192.168.147.93:50010 (tbe192168147093)
Rack: /dc1/rack3
192.168.147.94:50010 (tbe192168147094)
192.168.147.95:50010 (tbe192168147095)
192.168.147.96:50010 (tbe192168147096)
3).增加数据节点,不重启NameNode
假设Hadoop集群在192.168.147.68上部署了NameNode和DataNode,启用了机架感知,执行bin/hadoop dfsadmin -printTopology看到的结果:
Rack: /dc1/rack1
192.168.147.68:50010 (dbj68)
现在想增加一个物理位置在rack2的数据节点192.168.147.69到集群中,不重启NameNode。
首先,修改NameNode节点的topology.data的配置,加入:192.168.147.69 dbj69 /dc1/rack2,保存。
192.168.147.68 dbj68 /dc1/rack1
192.168.147.69 dbj69 /dc1/rack2
然后,sbin/hadoop-daemons.sh start datanode启动数据节点dbj69,任意节点执行bin/hadoop dfsadmin -printTopology 看到的结果:
Rack: /dc1/rack1
192.168.147.68:50010 (dbj68)
Rack: /dc1/rack2
192.168.147.69:50010 (dbj69)
说明hadoop已经感知到了新加入的节点dbj69。
注意:如果不将dbj69的配置加入到topology.data中,执行sbin/hadoop-daemons.sh start datanode启动数据节点dbj69,datanode日志中会有异常发生,导致dbj69启动不成功。
2013-11-21 10:51:33,502 FATAL org.apache.hadoop.hdfs.server.datanode.DataNode: Initialization failed for block pool Block pool BP-1732631201-192.168.147.68-1385000665316 (storage id DS-878525145-192.168.147.69-50010-1385002292231) service to dbj68/192.168.147.68:9000
org.apache.hadoop.ipc.RemoteException(org.apache.hadoop.net.NetworkTopology$InvalidTopologyException): Invalid network topology. You cannot have a rack and a non-rack node at the same level of the network topology.
at org.apache.hadoop.net.NetworkTopology.add(NetworkTopology.java:382)
at org.apache.hadoop.hdfs.server.blockmanagement.DatanodeManager.registerDatanode(DatanodeManager.java:746)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.registerDatanode(FSNamesystem.java:3498)
at org.apache.hadoop.hdfs.server.namenode.NameNodeRpcServer.registerDatanode(NameNodeRpcServer.java:876)
at org.apache.hadoop.hdfs.protocolPB.DatanodeProtocolServerSideTranslatorPB.registerDatanode(DatanodeProtocolServerSideTranslatorPB.java:91)
at org.apache.hadoop.hdfs.protocol.proto.DatanodeProtocolProtos$DatanodeProtocolService$2.callBlockingMethod(DatanodeProtocolProtos.java:20018)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Server$ProtoBufRpcInvoker.call(ProtobufRpcEngine.java:453)
at org.apache.hadoop.ipc.RPC$Server.call(RPC.java:1002)
at org.apache.hadoop.ipc.Server$Handler$1.run(Server.java:1701)
at org.apache.hadoop.ipc.Server$Handler$1.run(Server.java:1697)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:415)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1408)
at org.apache.hadoop.ipc.Server$Handler.run(Server.java:1695)
at org.apache.hadoop.ipc.Client.call(Client.java:1231)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Invoker.invoke(ProtobufRpcEngine.java:202)
at $Proxy10.registerDatanode(Unknown Source)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:601)
at org.apache.hadoop.io.retry.RetryInvocationHandler.invokeMethod(RetryInvocationHandler.java:164)
at org.apache.hadoop.io.retry.RetryInvocationHandler.invoke(RetryInvocationHandler.java:83)
at $Proxy10.registerDatanode(Unknown Source)
at org.apache.hadoop.hdfs.protocolPB.DatanodeProtocolClientSideTranslatorPB.registerDatanode(DatanodeProtocolClientSideTranslatorPB.java:149)
at org.apache.hadoop.hdfs.server.datanode.BPServiceActor.register(BPServiceActor.java:619)
at org.apache.hadoop.hdfs.server.datanode.BPServiceActor.connectToNNAndHandshake(BPServiceActor.java:221)
at org.apache.hadoop.hdfs.server.datanode.BPServiceActor.run(BPServiceActor.java:660)
at java.lang.Thread.run(Thread.java:722)
4).节点间距离计算
有了机架感知,NameNode就可以画出下图所示的datanode网络拓扑图。D1,R1都是交换机,最底层是datanode。则H1的rackid=/D1/R1/H1,H1的parent是R1,R1的是D1。这些rackid信息可以通过topology.script.file.name配置。有了这些rackid信息就可以计算出任意两台datanode之间的距离,得到最优的存放策略,优化整个集群的网络带宽均衡以及数据最优分配。
distance(/D1/R1/H1,/D1/R1/H1)=0 相同的datanode
distance(/D1/R1/H1,/D1/R1/H2)=2 同一rack下的不同datanode
distance(/D1/R1/H1,/D1/R2/H4)=4 同一IDC下的不同datanode
distance(/D1/R1/H1,/D2/R3/H7)=6 不同IDC下的datanode
以上是关于day07.HDFS学习大数据教程的主要内容,如果未能解决你的问题,请参考以下文章