.~day06-07_FlinkTable&SQL
Posted ChinaManor
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了.~day06-07_FlinkTable&SQL相关的知识,希望对你有一定的参考价值。
day06-07_FlinkSQL&Table
今日目标
- 了解Flink Table&SQL发展历史
- 了解为什么要使用Table API & SQL
- 掌握Flink Table&SQL进行批处理开发
- 掌握Flink Table&SQL进行流处理开发
- 掌握常用的开发案例
- Flink-SQL的常用算子
Flink Table & SQL
-
FlinkTable & SQL 是抽象级别更高的操作, 底层Flink Runtime => Stream 流程
-
批处理是流处理的一种特殊形态
-
FlinkSQL 遵循ANSI的SQL规范
-
Flink1.9之前, FlinkSQL包括两套Table api , DataStream Table API(流处理) ,DataSet Table API(批处理)
-
Planner 查询器, 抽象语法树,parser、optimizer、codegen(模板代码生成),最终生成 Flink Runtime 直接进行执行的代码
-
Planner包括old Planner 和 Blink Planner ,Blink Planner 底层实现了 流批一体(默认的Planner)
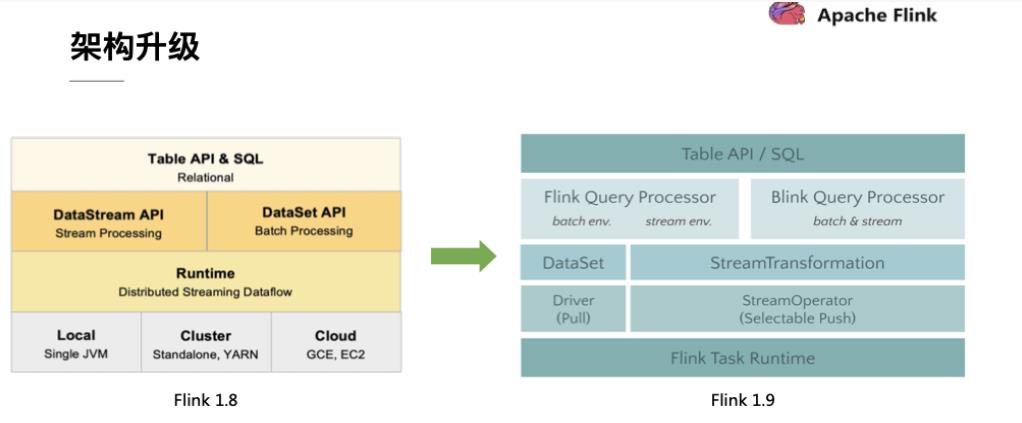
FlinkTable & SQL 程序结构
-
导入 pom 依赖, jar包坐标
<dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-table-api-scala-bridge_2.12</artifactId> <version>${flink.version}</version> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-table-api-java-bridge_2.12</artifactId> <version>${flink.version}</version> </dependency> <!-- flink执行计划,这是1.9版本之前的--> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-table-planner_2.12</artifactId> <version>${flink.version}</version> </dependency> <!-- blink执行计划,1.11+默认的--> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-table-planner-blink_2.12</artifactId> <version>${flink.version}</version> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-table-common</artifactId> <version>${flink.version}</version> </dependency> -
-
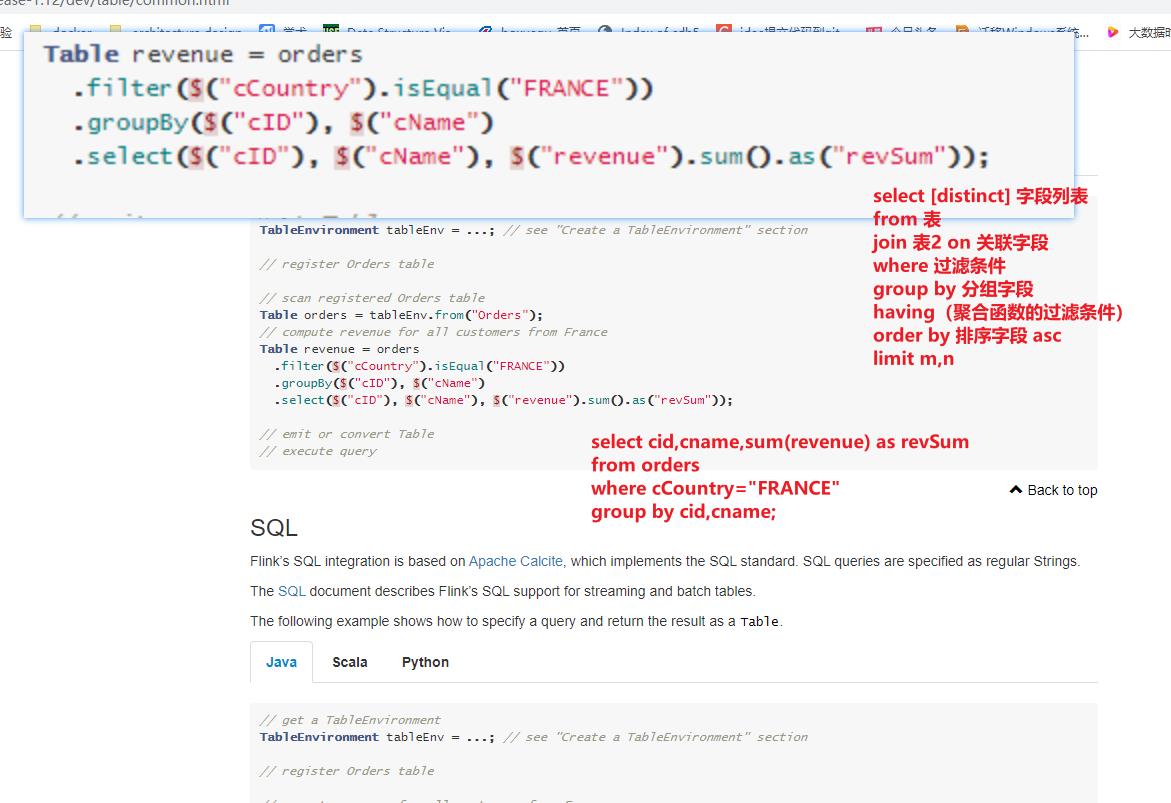
创建 FlinkTable FlinkSQL的 表的方式
// table is the result of a simple projection query Table projTable = tableEnv.from("X").select(...); // register the Table projTable as table "projectedTable" tableEnv.createTemporaryView("projectedTable", projTable); -
SQL的四种语句
- DDL 数据定义语言, 创建数据库、表,删除数据库、表
- DML 数据操作语言, 对数据进行增、删、改操作
- DCL 数据控制语言, 对数据的操作权限进行设置 grant revoke
- DQL 数据查询语言,对数据表中的数据进行查询,基础查询,复杂查询,多表查询,子查询
-
需求
将两个数据流 DataStream 通过 FlinkTable & SQL API 进行 union all 操作,条件ds1 amount>2 union all ds2 amount<2
-
开发步骤
package cn.itcast.flink.sql; import lombok.AllArgsConstructor; import lombok.Data; import lombok.NoArgsConstructor; import org.apache.flink.streaming.api.datastream.DataStream; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.table.api.EnvironmentSettings; import org.apache.flink.table.api.Table; import org.apache.flink.table.api.bridge.java.StreamTableEnvironment; import org.apache.flink.types.Row; import java.util.Arrays; import static org.apache.flink.table.api.Expressions.$; /** * Author itcast * Date 2021/6/22 9:45 * Desc TODO */ public class FlinkTableAPIDemo { public static void main(String[] args) throws Exception { //1.准备环境 创建流环境 和 流表环境,并行度设置为1 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setParallelism(1); EnvironmentSettings settings = EnvironmentSettings.newInstance().useBlinkPlanner().inStreamingMode().build(); //创建流表环境 StreamTableEnvironment tEnv = StreamTableEnvironment.create(env,settings); //2.Source 创建数据集 DataStream<Order> orderA = env.fromCollection(Arrays.asList( new Order(1L, "beer", 3), new Order(1L, "diaper", 4), new Order(3L, "rubber", 2))); DataStream<Order> orderB = env.fromCollection(Arrays.asList( new Order(2L, "pen", 3), new Order(2L, "rubber", 3), new Order(4L, "beer", 1))); //3.注册表 将数据流转换成表 // 通过fromDataStream将数据流转换成表 Table orderTableA = tEnv.fromDataStream(orderA, $("user"), $("product"), $("amount")); // 将数据流转换成 创建临时视图 tEnv.createTemporaryView("orderTableB",orderB,$("user"), $("product"), $("amount")); //4.执行查询,查询order1的amount>2并union all 上 order2的amoun<2的数据生成表 Table result = tEnv.sqlQuery("" + "select * from " + orderTableA + " where amount>2 " + "union all " + "select * from orderTableB where amount<2"); //4.1 将结果表转换成toAppendStream数据流 //字段的名称和类型 result.printSchema(); DataStream<Row> resultDS = tEnv.toAppendStream(result, Row.class); //5.打印结果 resultDS.print(); //6.执行环境 env.execute(); // 创建实体类 user:Long product:String amount:int } @Data @NoArgsConstructor @AllArgsConstructor public static class Order { public Long user; public String product; public int amount; } }
动态表 & 连续查询
-
动态表就是无界的数据表, 源源不断的将数据输入和输出
-
需求: 使用SQL和Table两种方式对DataStream中的单词进行统计。
package cn.itcast.flink.sql; import lombok.AllArgsConstructor; import lombok.Data; import lombok.NoArgsConstructor; import org.apache.flink.api.java.tuple.Tuple2; import org.apache.flink.streaming.api.datastream.DataStream; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.table.api.Table; import org.apache.flink.table.api.bridge.java.StreamTableEnvironment; import org.apache.flink.types.Row; import java.util.Arrays; import static org.apache.flink.table.api.Expressions.$; /** * Author itcast * Date 2021/6/22 11:16 * Desc TODO */ public class FlinkSQLDemo { public static void main(String[] args) throws Exception { //1.准备环境 获取流执行环境 流表环境 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setParallelism(1); //流表环境 StreamTableEnvironment tEnv = StreamTableEnvironment.create(env); //2.Source 获取 单词信息 //2.Source DataStream<Order> orderA = env.fromCollection(Arrays.asList( new Order(1L, "beer", 3), new Order(1L, "diaper", 4), new Order(3L, "rubber", 2))); DataStream<Order> orderB = env.fromCollection(Arrays.asList( new Order(2L, "pen", 3), new Order(2L, "rubber", 3), new Order(4L, "beer", 1))); //3.创建视图 WordCount tEnv.createTemporaryView("t_order",orderA,$("user"),$("product"),$("amount")); //4.执行查询 根据用户统计订单总量 Table table = tEnv.sqlQuery( "select user,sum(amount) as totalAmount " + " from t_order " + " group by user " ); //5.输出结果 retractStream获取数据流(别名) DataStream<Tuple2<Boolean, Row>> result = tEnv.toRetractStream(table, Row.class); //6.打印输出结果 result.print(); //7.执行 env.execute(); } @Data @NoArgsConstructor @AllArgsConstructor public static class Order { public Long user; public String product; public int amount; } } -
需求
单词统计,统计出来单词的出现次数为2 的单词的数据流打印输出,使用 Flink Table
-
开发步骤
package cn.itcast.flink.sql; import lombok.AllArgsConstructor; import lombok.Data; import lombok.NoArgsConstructor; import org.apache.flink.api.java.tuple.Tuple2; import org.apache.flink.streaming.api.datastream.DataStream; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.table.api.Table; import org.apache.flink.table.api.bridge.java.StreamTableEnvironment; import org.apache.flink.types.Row; import static org.apache.flink.table.api.Expressions.$; /** * Author itcast * Date 2021/6/22 11:29 * Desc TODO */ public class FlinkTableDemo { public static void main(String[] args) throws Exception { //1.准备环境 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); StreamTableEnvironment tEnv = StreamTableEnvironment.create(env); //2.Source DataStream<WC> input = env.fromElements( new WC("Hello", 1), new WC("World", 1), new WC("Hello", 1) ); //3.注册表 Table table = tEnv.fromDataStream(input, $("word"), $("frequency")); //4.通过 FLinkTable API 过滤分组查询 // select word,count(frequency) as frequency // from table // group by word // having count(frequency)=2; Table filter = table .groupBy($("word")) .select($("word"), $("frequency").count().as("frequency")) .filter($("frequency").isEqual(2)); //5.将结果集转换成 DataStream DataStream<Tuple2<Boolean, Row>> result = tEnv.toRetractStream(filter, Row.class); //6.打印输出 result.print(); //7.执行 env.execute(); } @Data @NoArgsConstructor @AllArgsConstructor public static class WC { public String word; public long frequency; } } -
需求
使用Flink SQL来统计 5秒内 每个用户的 订单总数、订单的最大金额、订单的最小金额
也就是每隔5秒统计最近5秒的每个用户的订单总数、订单的最大金额、订单的最小金额
上面的需求使用流处理的Window的基于时间的滚动窗口就可以搞定!
那么接下来使用FlinkTable&SQL-API来实现
-
开发步骤
package cn.itcast.flink.SQL; import lombok.AllArgsConstructor; import lombok.Data; import lombok.NoArgsConstructor; import org.apache.flink.api.common.eventtime.WatermarkStrategy; import org.apache.flink.api.java.tuple.Tuple2; import org.apache.flink.streaming.api.datastream.DataStream; import org.apache.flink.streaming.api.datastream.DataStreamSource; import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.api.functions.source.RichSourceFunction; import org.apache.flink.table.api.EnvironmentSettings; import org.apache.flink.table.api.Table; import org.apache.flink.table.api.bridge.java.StreamTableEnvironment; import org.apache.flink.types.Row; import java.time.Duration; import java.util.Random; import java.util.UUID; import static org.apache.flink.table.api.Expressions.$; /** * Author itcast * Date 2021/6/23 8:42 * Desc TODO */ public class FlinkTableWindow { public static void main(String[] args) throws Exception { //1.准备环境 创建流执行环境和流表环境 //准备流执行环境 StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); //设置Flink table配置 EnvironmentSettings settings = EnvironmentSettings.newInstance().useBlinkPlanner().inStreamingMode().build(); //准备流表环境 StreamTableEnvironment tEnv = StreamTableEnvironment.create(env, settings); //2.Source 自定义Order 每一秒中睡眠一次 DataStreamSource<Order> source = env.addSource(new