大数据Kudu:Kudu架构
Posted Lansonli
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据Kudu:Kudu架构相关的知识,希望对你有一定的参考价值。

文章目录
二、Kudu table存储原理
Kudu架构
一、Kudu存储模型及概念
Kudu有自己的数据存储模型,不依赖于HDFS、Hive、HBase其他大数据组件。Kudu有自己的集群,数据存储在Kudu自己的集群Tablet Server中。
- Kudu的存储模型是有结构的表,表中有主键,并且主键唯一,不能重复。
- 事务支持上与HBase类似,只支持行级ACID事务。
- Kudu是列式存储,支持数据压缩。
- Kudu不支持标准SQL,支持Nosql样式的API,例如:put,get,delete,scan。一般企业中kudu与impala进行整合使用,可以使用SQL对数据进行实时OLAP分析。

- Table:
table是数据存储在Kudu的位置,具有schema和全局有序的 primary key。一张table被分成多个tablet,其中Tablet的数量是根据hash或者range进行设置。
- Tablet:
一个tablet是一张table连续的segment,与其他数据存储引擎或关系型数据的partition相似。Tablet存在副本机制,其中一个副本为leader tablet。一个 tablet 通常由一个 Leader 和两个 Follower 组成, 这些角色分布的不同的服务器中。任何副本都可以对读取进行服务,并且写入时需要在所有副本对应的tablet server之间达成一致性。
- Master server:
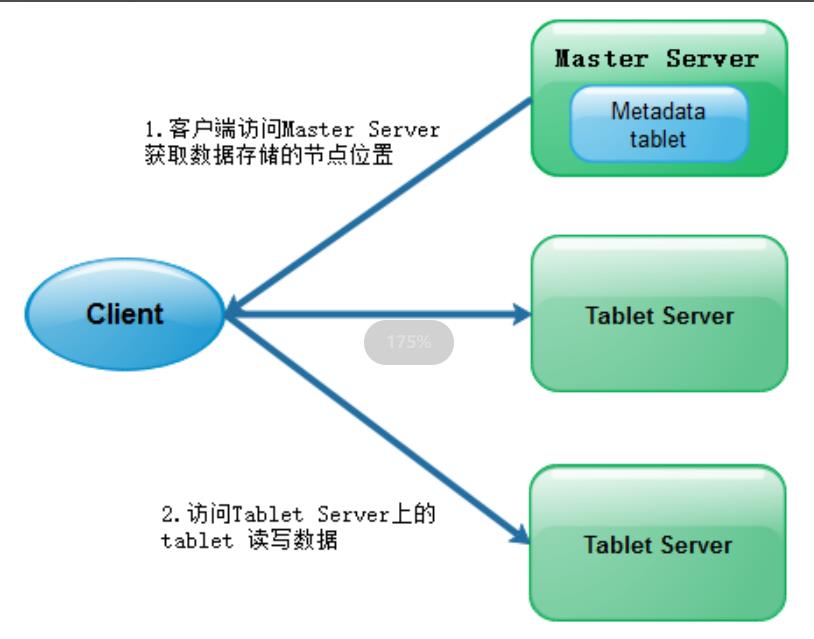
Master Servers使用一个tablet存储集群元数据信息,元数据包括所有tablet Server信息、所有tablet位置信息等。客户端访问某一张表的某一部分数据时, 会先询问 Master server, 获取这个数据的位置, 去对应位置获取或者存储数据。虽然 Master 比较重要, 但是其承担的职责并不多, 数据量也不大, 所以为了增进效率, 这个 tablet 会存储在内存中。生产环境中通常会使用多个 Master server 来保证可用性,给定的时间点只能有一个Master是Leader起作用。
- Tablet Server :

tablet server 存储 tablet,负责表数据存储且负责和数据相关的所有操作, 包括存储, 访问, 压缩, 其还负责将数据复制到其它机器。对于给定的 tablet,一个 tablet server 充当 leader,其他 tablet server 充当该 tablet 的 follower 副本。只有 leader 服务写请求,然而 leader 或 followers 为每个服务提供读请求。一个 tablet server 可以服务多个 tablets ,并且一个 tablet 可以被多个 tablet servers 服务着。
由于Tablet Server 特殊结构和任务繁重,Kudu最多支持300个服务器,建议每个Tablet Server最多包含2000个tablet(包含follower)。
二、Kudu table存储原理
对于一张特定的Kudu表,存储结构如下:
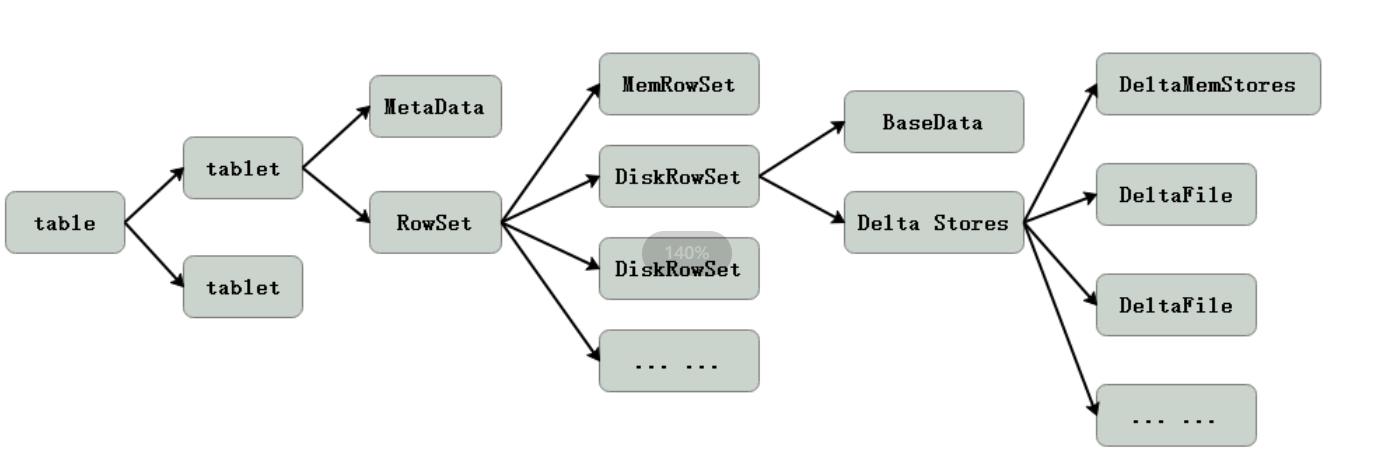
Kudu数据存储实现如下:
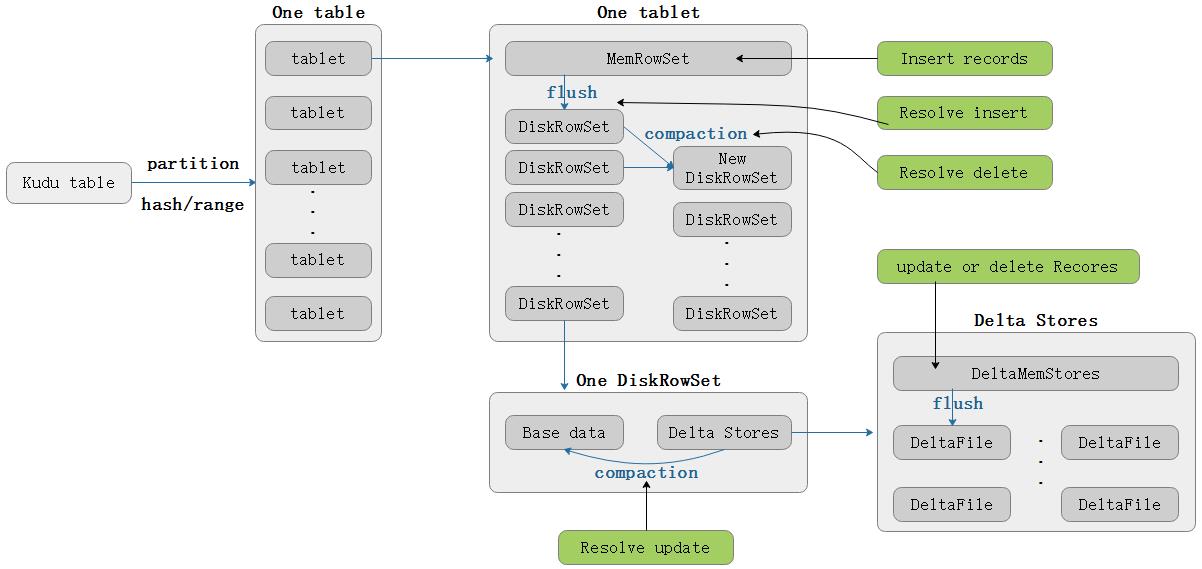
一个table根据hash或者range分区分成多个tablet,每个tablet中包含MetaData元数据信息和RowSet信息,RowSet中包含一个MemRowSet和0到多个的DiskRowSet。其中MemRowSet存储insert的数据,一旦MemRowSet写满会flush到磁盘生成一个或多个DiskRowSet,此时MemRowSet清空。MemRowSet默认写满1G或者120s flush一次。DiskRowSet一经写入就无法修改。
另外,memRowSet是行式存储,DiskRowSet是列式存储,这是Kudu可支持一些分析性查询的基础,MemRowSet基于primary key有序。每隔一段时间,tablet中会定期对一些DiskRowSet做compaction操作,目的是对多个DiskRowSet进行重新排序,以此来使其更有序并减少diskRowSet的数量,同时在compaction的过程中会resolve掉DeltaStores当中的delete记录。
DiskRowSet是不可以修改的,那么kudu如何进行数据修改和删除呢?在内部,每个DiskRowSet又分为两部分:Base Data和Delta Stores。数据从MemRowSet刷到磁盘后就形成一份DiskRowSet,只包含base data,每份DiskRowSet在内存中都会有一个对应的DeltaMemStore,负责记录此DiskRowSet后续数据的更新和删除。DeltaMemStore内部维护一个B树索引,映射每个row_offset对应的数据变更。DeltaMemStore数据增长到一定程序后存储到磁盘,形成一个DeltaFile,随着数据的不断变更,DeltaFile会逐渐增多。
随着时间推移,Kudu中的小文件会越来越多,主要包含各个DiskRowSet中的base data,还有每个base data对应的若干个DeltaFile。小文件增多会影响Kudu性能,为了提高性能,Kudu会定期Compaction,这里的Compaction主要包含两部分:
1、DeltaFile compaction:
过多的DeltaFile影响读性能,定期将DeltaFile合并回base data可以提升性能。
2、DiskRowSet compaction (上文提到):
除了DeltaFile,定期将DiskRowSet合并也能提升性能,一个原因是合并时可以将被删除的数据彻底删除,另外也减少了文件数,提升索引效率。
经过以上了解Kudu数据存储实现的原理,我们可以知道Kudu中写入数据时优先写入内存,可以加快数据插入效率;数据在磁盘中存储在DiskRowSet中,有主键,DiskRowSet结构类似parquet结构,可以保证数据扫描分析效率。Kudu就是通过以上来实现既能高效的插入数据同时又能快速扫描大量数据满足分析性能。
- 📢博客主页:https://lansonli.blog.csdn.net
- 📢欢迎点赞 👍 收藏 ⭐留言 📝 如有错误敬请指正!
- 📢本文由 Lansonli 原创,首发于 CSDN博客🙉
- 📢停下休息的时候不要忘了别人还在奔跑,希望大家抓紧时间学习,全力奔赴更美好的生活✨
以上是关于大数据Kudu:Kudu架构的主要内容,如果未能解决你的问题,请参考以下文章