客快物流大数据项目(四十一):Kudu入门介绍
Posted Lansonli
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了客快物流大数据项目(四十一):Kudu入门介绍相关的知识,希望对你有一定的参考价值。
目录
Kudu入门介绍
一、背景介绍
在Kudu之前,大数据主要以两种方式存储;
- 静态数据:
- 以 HDFS 引擎作为存储引擎,适用于高吞吐量的离线大数据分析场景。
- 这类存储的局限性是数据无法进行随机的读写。
- 动态数据:
- 以 HBase、Cassandra 作为存储引擎,适用于大数据随机读写场景。
- 这类存储的局限性是批量读取吞吐量远不如 HDFS,不适用于批量数据分析的场景。
从上面分析可知,这两种数据在存储方式上完全不同,进而导致使用场景完全不同,但在真实的场景中,边界可能没有那么清晰,面对既需要随机读写,又需要批量分析的大数据场景,该如何选择呢?这个场景中,单种存储引擎无法满足业务需求,我们需要通过多种大数据工具组合来满足这一需求。
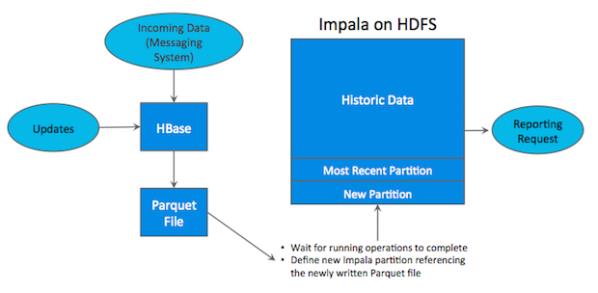
如上图所示,数据实时写入 HBase,实时的数据更新也在 HBase 完成,为了应对 OLAP 需求,我们定时(通常是 T+1 或者 T+H)将 HBase 数据写成静态的文件(如:Parquet)导入到 OLAP 引擎(如:HDFS)。这一架构能满足既需要随机读写,又可以支持 OLAP 分析的场景,但它有如下缺点:
- 架构复杂。从架构上看,数据在HBase、消息队列、HDFS 间流转,涉及环节太多,运维成本很高。并且每个环节需要保证高可用,都需要维护多个副本,存储空间也有一定的浪费。最后数据在多个系统上,对数据安全策略、监控等都提出了挑战。
- 时效性低。数据从HBase导出成静态文件是周期性的,一般这个周期是一天(或一小时),在时效性上不是很高。
- 难以应对后续的更新。真实场景中,总会有数据是延迟到达的。如果这些数据之前已经从HBase导出到HDFS,新到的变更数据就难以处理了,一个方案是把原有数据应用上新的变更后重写一遍,但这代价又很高。
为了解决上述架构的这些问题,Kudu应运而生。Kudu的定位是Fast Analytics on Fast Data,是一个既支持随机读写、又支持 OLAP 分析的大数据存储引擎。
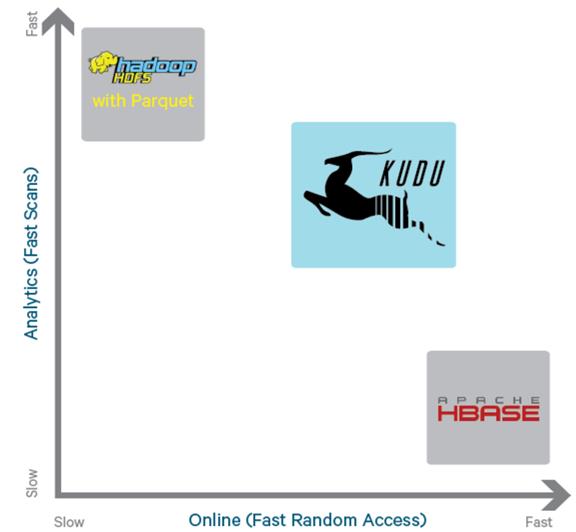
从上图可以看出,KUDU 是一个折中的产品,在 HDFS 和 HBase 这两个偏科生中平衡了随机读写和批量分析的性能。从 KUDU 的诞生可以说明一个观点:底层的技术发展很多时候都是上层的业务推动的,脱离业务的技术很可能是空中楼阁。
二、新的硬件设备
内存(RAM)的技术发展非常快,它变得越来越便宜,容量也越来越大。Cloudera的客户数据显示,他们的客户所部署的服务器,2012年每个节点仅有32GB RAM,现如今增长到每个节点有128GB或256GB RAM。存储设备上更新也非常快,在很多普通服务器中部署SSD也是屡见不鲜。HBase、HDFS、以及其他的Hadoop工具都在不断自我完善,从而适应硬件上的升级换代。然而,从根本上,HDFS基于03年GFS,HBase基于05年BigTable,在当时系统瓶颈主要取决于底层磁盘速度。当磁盘速度较慢时,CPU利用率不足的根本原因是磁盘速度导致的瓶颈,当磁盘速度提高了之后,CPU利用率提高,这时候CPU往往成为系统的瓶颈。HBase、HDFS由于年代久远,已经很难从基本架构上进行修改,而Kudu是基于全新的设计,因此可以更充分地利用RAM、I/O资源,并优化CPU利用率。
我们可以理解为:Kudu相比与以往的系统,CPU使用降低了,I/O的使用提高了,RAM的利用更充分了。
三、Kudu是什么
Apache Kudu是由Cloudera开源的存储引擎,可以同时提供低延迟的随机读写和高效的数据分析能力。它是一个融合HDFS和HBase的功能的新组件,具备介于两者之间的新存储组件。
Kudu支持水平扩展,并且与Cloudera Impala和Apache Spark等当前流行的大数据查询和分析工具结合紧密。
四、Kudu的应用场景
Kudu的很多特性跟HBase很像,它支持索引键的查询和修改。Cloudera曾经想过基于Hbase进行修改,然而结论是对HBase的改动非常大,Kudu的数据模型和磁盘存储都与Hbase不同。HBase本身成功的适用于大量的其它场景,因此修改HBase很可能吃力不讨好。最后Cloudera决定开发一个全新的存储系统。
- Strong performance for both scan and random access to help customers simplify complex hybrid architectures(适用于那些既有随机访问,也有批量数据扫描的复合场景)
- High CPU efficiency in order to maximize the return on investment that our customers are making in modern processors(高计算量的场景)
- High IO efficiency in order to leverage modern persistent storage(使用了高性能的存储设备,包括使用更多的内存)
- The ability to upDATE data in place, to avoid extraneous processing and data movement(支持数据更新,避免数据反复迁移)
- The ability to support active-active replicated clusters that span multiple data centers in geographically distant locations(支持跨地域的实时数据备份和查询)
五、Kudu架构
下图显示了一个具有三个 master 和多个 tablet server 的 Kudu 集群,每个服务器都支持多个 tablet。
它说明了如何使用 Raft 共识来允许 master 和 tablet server 的 leader 和 follow。
此外,tablet server 可以成为某些 tablet 的 leader,也可以是其他 tablet 的 follower。leader 以金色显示,而 follower 则显示为蓝色。
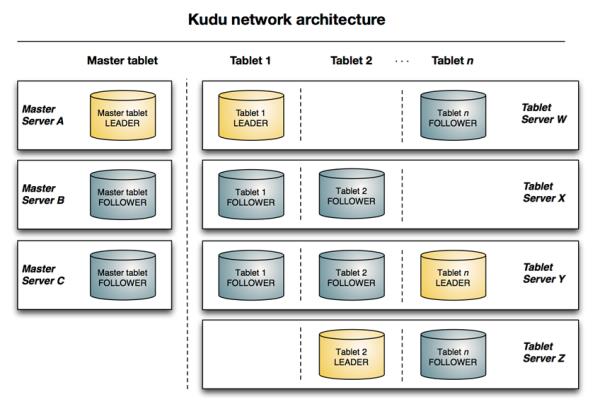
下面是一些基本概念:
| 角色 | 作用 |
| Master | 集群中的老大,负责集群管理、元数据管理等功能 |
| Tablet Server | 集群中的小弟,负责数据存储,并提供数据读写服务 一个 tablet server 存储了table表的tablet 和为 tablet 向 client 提供服务。对于给定的 tablet,一个tablet server 充当 leader,其他 tablet server 充当该 tablet 的 follower 副本。 只有 leader服务写请求,然而 leader 或 followers 为每个服务提供读请求 。一个 tablet server 可以服务多个 tablets ,并且一个 tablet 可以被多个 tablet servers 服务着。 |
| Table(表) | 一张table是数据存储在Kudu的tablet server中。表具有 schema 和全局有序的primary key(主键)。table 被分成称为 tablets 的 segments。 |
| Tablet | 一个 tablet 是一张 table连续的segment,tablet是kudu表的水平分区,类似于google Bigtable的tablet,或者HBase的region。每个tablet存储着一定连续range的数据(key),且tablet两两间的range不会重叠。一张表的所有tablet包含了这张表的所有key空间。与其它数据存储引擎或关系型数据库中的 partition(分区)相似。给定的tablet 冗余到多个 tablet 服务器上,并且在任何给定的时间点,其中一个副本被认为是leader tablet。任何副本都可以对读取进行服务,并且写入时需要在为 tablet 服务的一组 tablet server之间达成一致性。 |
- 📢博客主页:https://lansonli.blog.csdn.net
- 📢欢迎点赞 👍 收藏 ⭐留言 📝 如有错误敬请指正!
- 📢本文由 Lansonli 原创,首发于 CSDN博客🙉
- 📢大数据系列文章会每天更新,停下休息的时候不要忘了别人还在奔跑,希望大家抓紧时间学习,全力奔赴更美好的生活✨
以上是关于客快物流大数据项目(四十一):Kudu入门介绍的主要内容,如果未能解决你的问题,请参考以下文章
客快物流大数据项目(四十六):Spark操作Kudu dataFrame操作kudu