大数据入门-什么是Kudu
Posted 水坚石青
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据入门-什么是Kudu相关的知识,希望对你有一定的参考价值。
目录
这里简单介绍的Kudu的一些常见的名词,简单的架构,一些常用的语句。至于后续比较详细的介绍,会单独针对这个组件进行详细介绍,可以关注博客后续阅读。
一、概念

Kudu是Cloudera开源的新型列式存储系统,是Apache Hadoop生态圈的成员之一,专门为了对快速变化的数据进行快速的分析,填补了以往Hadoop存储层的空缺。
Kudu提供了更接近于RDBMS的功能和数据模型,提供类似于关系型数据库的存储结构来存储数据,允许用户以和关系型数据库相同的方式插入、更新、删除数据。
Kudu仅仅是一个存储层,它并不存储数据,而是依赖外部的Hadoop处理引擎(MapReduce,Spark,Impala)。Kudu把数据按照自己的列存储格式存储在底层Linux文件系统中。
Kudu中的核心是基于表的存储引擎。Kudu存储自己的元数据(有关表的)信息和用户的数据,保存在Tablet中。
Kudu有Upsert来更新数据,类似于Oracle的Merge。
二、架构

与HDFS和HBase相似,Kudu使用单个的Master节点,用来管理集群的元数据,并且使用任意数量的Tablet Server(可对比理解HBase中的RegionServer角色)节点用来存储实际数据。可以部署多个Master节点来提高容错性。一个Table表的数据,被分割成1个或多个Tablet,Tablet被部署在Tablet Server来提供数据读写服务。
1.Master Server
Kudu集群中的老大,可以有多个Master Server提高集群的容错能力,但是只有一个Master Server对外提供服务,负责管理集群和管理元数据。
2.Tablet Server
Kudu集群中的小弟,可以有任意多个,负责存储数据和数据读写。在Tablet Server上存储Tablet,对于一个Tablet,只有其中一个Table Server作为Leader,提供读写服务,其他Table Server都是Follower,只提供读服务。
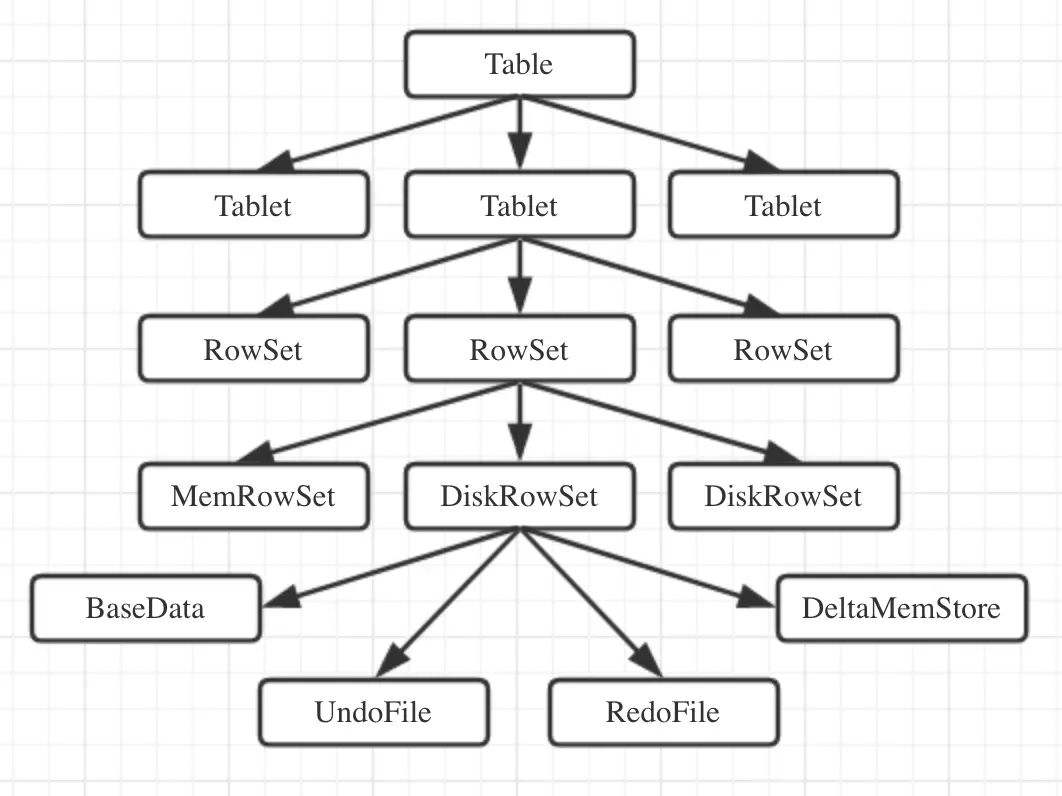
3.Table
Table: Kudu中的表概念,有Schema和Primary Key概念,Kudu中的表会被水平方向分为多个Tablet片段存储在Tablet Server上。
4.Tablet
一个Tablet是一张表的一个连续片段,Tablet是表的水平分区,Tablet之间的Primary Key范围不会重叠,一张表的所有Tablet片段构成了这张表的所有Primary Key范围。Tablet会冗余存储在多个Tablet Server上设置副本,任何时刻只有一个Tablet Server是Leader,其他都是Follower。
三、特性
1.重要性
1.大数据分析的复杂性往往是存储系统的局限性带来的,Kudu 的局限性小很多,一定程度使大数据分析变得简单。
2.新的应用场景需要 Kudu,例如越来越多的应用集中在机器生成的数据和实时分析领域。
3.适配新的硬件环境,从而带来更高的性能和应用灵活性。
2.易用性
1.提供了更接近于 RDBMS 的功能和数据模型;
2.提供类似 RDBMS 的库表存储结构;
3.允许用户以和 RDBMS 相同的方式插入、更新和删除数据。
3.优势
Kudu 同时具备了逐行插入、低延迟随机访问、更新和快速分析扫描的能力,使得它在 OLAP 和 OLTP 中都能提供较好的支持,这些原本需要多个存储系统同时支持的复杂架构被替换成只有一个存储系统,所有的数据被存放在这个存储系统里,极大地简化了大数据的架构。
4.与传统关系型数据库比较
1.跟关系型数据库一样,Kudu 表有一个唯一的主键。
2.关系型数据库中常见的特性,比如事务、外键和非主键索引,目前在Kudu中是不支持的。
3.Kudu拥有一些OLAP和OLTP特性,但是缺少对跨行的原子性、一致性、隔离性、持久性事务的支持。
4.Kudu可被归为混合食物/分析处理(Hybrid Transaction/Analytic Processing,HTAP)类型数据库。
5.Kudu支持快速主键检索,并能在数据持续输入的同时进行分析,而 OLAP 数据库在这种场景下性能通常不是很好。
6.Kudu的持久性保证和 OLTP 数据库更为接近。
7.Kudu的Quorum 能力可以实现一种名为Fractured Mirrors的机制,即一个或两个节点使用行存储,另外的节点使用列存储。这样就可以在行存储的节点上执行OLTP类型的查询,在列存储的节点上执行OLAP查询,混合两种负载。
5.与其他大数据组件比较
1.HDFS擅长大规模扫描,但不擅长随机读,严格来说,并不支持随机写,可以通过合并的方式模拟随机写,但成本很高。
2.HBase和Cassandra擅长随机访问,随机读取和修改数据,但大规模扫描性能较差。
3.Kudu的目标是把扫描性能做到HDFS的两倍,而随机读性能接 HBase和Cassandra,实际目标是在SSD上随机读/写的延迟在1ms以内。
四、常用语句
1.建表
Kudu建表是需要主键的,主键不能为空。
1.建普通表
create table test.test1 (
date_timekey string not null,
username string null,
product_qty string null
)
stored as kudu2.建分区表
create table test.test1 (
date_timekey string not null,
username string null,
product_qty string null,
primary key (date_timekey)
)
partition by range (date_timekey) (value='20220417')
stored as kudu
2.删除表
drop table if exists test.test1;
3.查询数据
注意:查询数据的时候,最好是把要查询的列带上,这样可以减少查询的列,减轻查询的Loading。在写SQL的时候,使用指定的列对大数据集群压力更小,系统健壮性更加强。
select date_timekey,username from test.test1
4.添加数据
注意:分区表插入数据之前,一定要先建好分区。
insert into test.test1 (date_timekey,username)values('20200330','shuijianshiqing');
注意:添加的数据主键不能为空,否则数据进去不。
insert into test.test1 (date_timekey,b)values(null,'shuijianshiqing');
5.更新数据
upsert into test.test1 (date_timekey,username)values('20200330','shuijianshiqing');
6.删除数据
注意:删除数据时候,不能使用别名删除,比如test.test t,然后条件里面是t.date_timekey,这样数据删除不了。
delete from test.test1 where date_timekey='20200328';
7.新增单个分区
alter table test.test1 add range partition value='20200325';
8.删除单个分区
alter table test.test1 drop range partition value='20200325';
9.新增多个分区
alter table test.test1 add range partition '20200327'<=values<'20200331';
10.删除多个分区
alter table test.test1 drop range partition '20200327'<=values<'20200331';11.新增列
alter table test.test1 add columns(column_new string);
12.删除列
alter table test.test1 drop column column_new;
13.修改列名
username是列的原来的名称,username_new是新列的名称,
alter table test.test1 change column username username_new string;
14.分区为多列
1.新建表
drop table if exists test.test2;
create table test.test2 (
id String not null,
date_timekey String not null,
hour_timekey String not null,
username STRING,
password STRING,
interface_time String,
primary key (id,date_timekey,hour_timekey)
)
partition by range (date_timekey,hour_timekey) (partition value=('20200601','20200601 0730'))
stored as kudu
2.新增分区
alter table test.test2_kudu add range partition value=('20200601','20200601 0830');
3.删除分区
alter table test.test2_kudu drop range partition value=('20200601','20200601 0830');五、大白话
Kudu就是一个存储引擎,类似于RDBMS,能够增删改查,让大数据分析更加便捷。他的存储不是基于Hadoop,而是自己有一套独立的系统在Linux。至于Kudu的读写等更加细致的内容,后面会详细介绍。
六、其他
鸡汤:世间最怕认真二字,这二字值千金,千金不换!
大数据入门系列文章
帅哥美女们走过路过不要错过,关注点赞走上人生巅峰!!!
以上是关于大数据入门-什么是Kudu的主要内容,如果未能解决你的问题,请参考以下文章