EMNLP 2019Sentence-BERT
Posted 小爷毛毛(卓寿杰)
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了EMNLP 2019Sentence-BERT相关的知识,希望对你有一定的参考价值。
1. 介绍
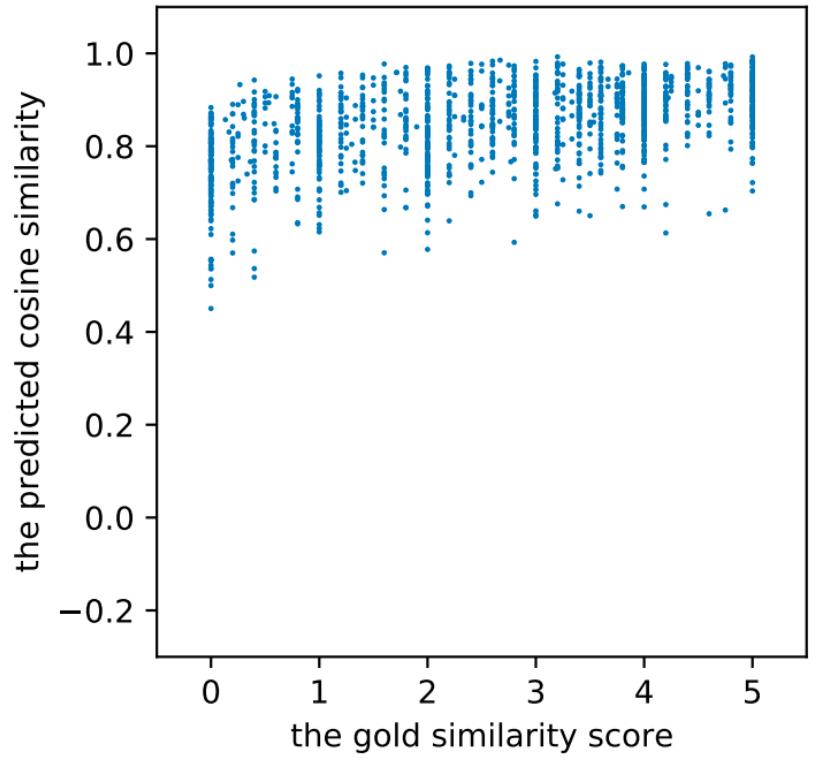
在许多NLP任务(特别是在文本语义匹、文本向量检索等)需要训练优质的句子表示向量,模型通过计算两个句子编码后的Embedding在表示空间的相似度来衡量这两个句子语义上的相关程度,从而决定其匹配分数。尽管基于BERT在诸多NLP任务上取得了不错的性能,但其自身导出的句向量(【CLS】输出的向量、对所有输出字词token向量求平均)质量较低。由于BERT输出token向量预训练中,后面接的的分类的任务。所以其实输出token向量并不适合作为生成句子表示。美团一篇论文中提到,发现以这种方式编码,句子都倾向于编码到一个较小的空间区域内,这使得大多数的句子对都具有较高的相似度分数,即使是那些语义上完全无关的句子对,并将此称为BERT句子表示的“坍缩(Collapse)”现象:
如何更好的利用BERT来做文本语义匹等任务呢?Sentence-BERT作者提出了以下方案:
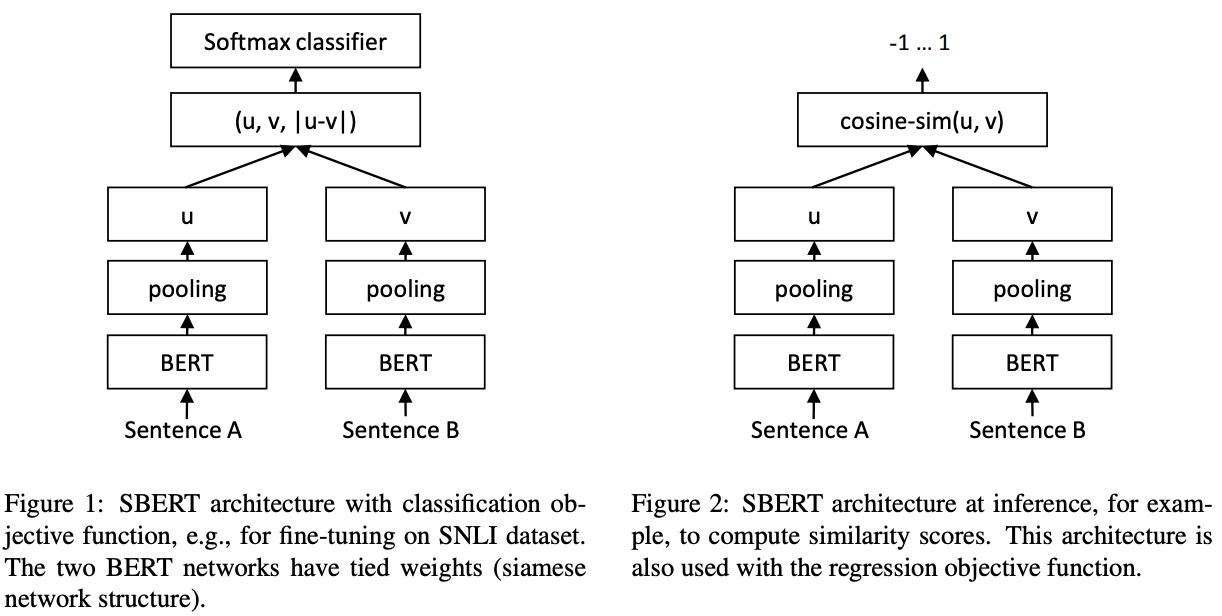
简单来说,就利用孪生网络,输出句子A和B,再将输出的token向量Pooling成两个向量(Pooling 方式可以是mean、max或者取【CLS】,实验mean的效果最好),进行有监督的向量相似度训练。
相似度训练目标函数一共有三种:
- 分类目标函数:

- 回归目标函数
如图2的方式计算向量cos相似度,使用平均差损失训练模型。 - 三重目标函数
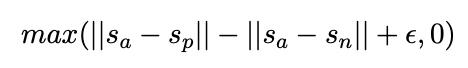
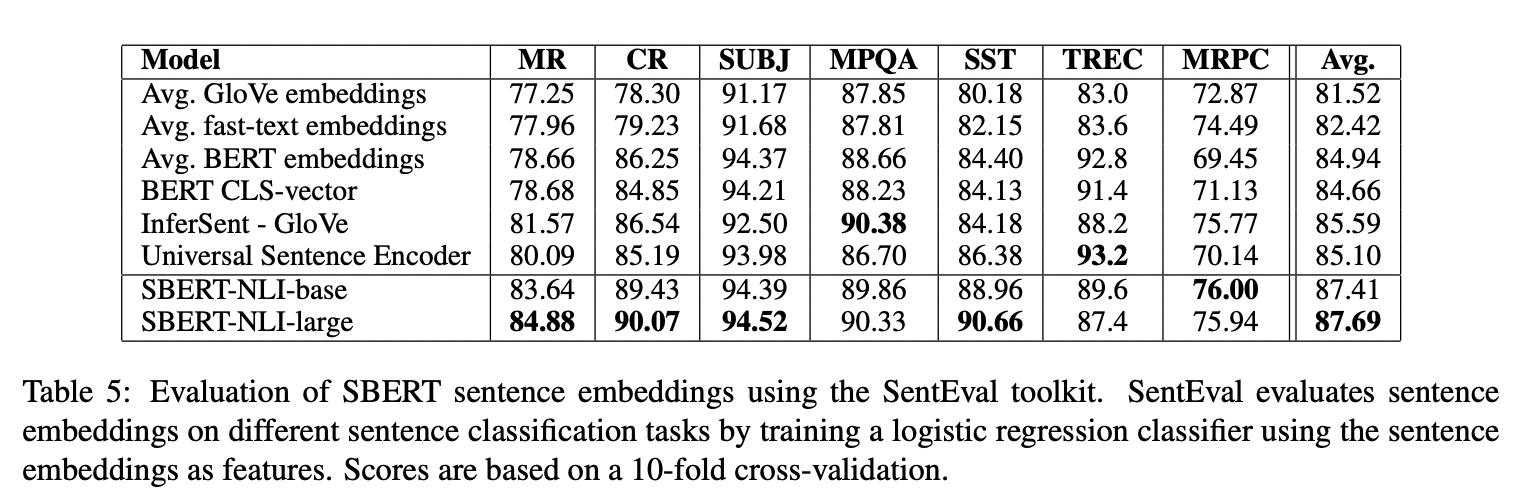
2. 实验效果
3.实现
sentence_transformers已经把Sentence-BERT已经封装成pip包,可以轻松进行Sentence-BERT训练:
from sentence_transformers import SentenceTransformer, models
#这里可以加载 Hugging Face 预训练模型,或者本地预训练模型
word_embedding_model = models.Transformer('bert-base-uncased', max_seq_length=256)
pooling_model = models.Pooling(word_embedding_model.get_word_embedding_dimension())
model = SentenceTransformer(modules=[word_embedding_model, pooling_model])
#训练样本
train_examples = [InputExample(texts=['My first sentence', 'My second sentence'], label=0.8),
InputExample(texts=['Another pair', 'Unrelated sentence'], label=0.3)]
train_dataloader = DataLoader(train_examples, shuffle=True, batch_size=16)
#定义损失函数
train_loss = losses.CosineSimilarityLoss(model)
#验证集
sentences1 = ['This list contains the first column', 'With your sentences', 'You want your model to evaluate on']
sentences2 = ['Sentences contains the other column', 'The evaluator matches sentences1[i] with sentences2[i]', 'Compute the cosine similarity and compares it to scores[i]']
scores = [0.3, 0.6, 0.2]
evaluator = evaluation.EmbeddingSimilarityEvaluator(sentences1, sentences2, scores)
#调整模型
model.fit(train_objectives=[(train_dataloader, train_loss)], epochs=1, warmup_steps=100, evaluator=evaluator, evaluation_steps=500)
以上是关于EMNLP 2019Sentence-BERT的主要内容,如果未能解决你的问题,请参考以下文章
论文泛读142Sentence-BERT:使用 Siamese BERT-Networks 的句子嵌入
人工智能干货推荐[第2020-49期][02NLP][Sentence-BERT:一种能快速计算句子相似度的孪生网络]