搜索与问答——EMNLP 2021TSDAE:基于Transformer的顺序去噪自动编码器
Posted 小爷毛毛(卓寿杰)
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了搜索与问答——EMNLP 2021TSDAE:基于Transformer的顺序去噪自动编码器相关的知识,希望对你有一定的参考价值。
1. 介绍
TSDAE(Transformer-based Sequential Denoising Auto-Encoder)模型使用纯句子作为训练数据来无监督训练句子向量。在训练期间,TSDAE 将加了噪声的句子编码为固定大小的向量,并要求decoder从这个句子表征中重建原始句子。为了获得良好的重建质量,必须在encoder的句子向量中很好地捕获语义。在后续推理时,我们只使用encoder来创建句子向量。架构如下图所示:
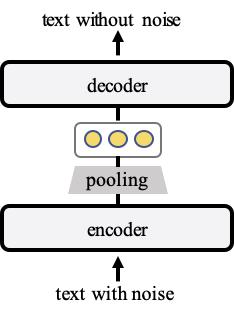
encoder部分就是将带噪音的文本进行编码。控制变量实验发现,以“删除词语”的方式加入噪音、噪音比率在0.6效果的最好的:


然后将encoder的输出进行pooling,控制变量实验发现,以mean的方式pooling效果最好:

接下来我们主要关注下decoder部分。decoder使用的是 cross-attention:

其中s是encoder输出pooling后的句子表征,
H
k
H^k
Hk的decoder第k层的隐层。
目标函数:
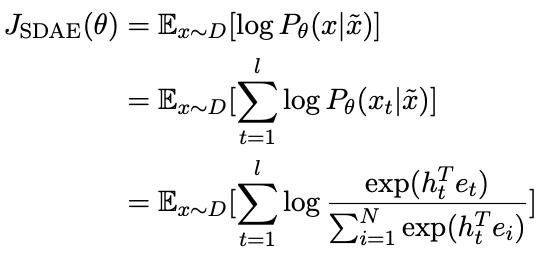
其中 l 是原文本x的token数,N的词表大小
2. 实验效果
对比来看,大部分任务,TSDAE效果会优于我们之前介绍的CT和SimCSE的:

3. 实现
sentence_transformers已经把TSDAE已经封装成pip包,完整的训练流程例子可以参考《Sentence-BERT》。我们在此基础上只用修改dataset和loss就能轻松的训练TSDAE:
# 创建可即时添加噪声的特殊去噪数据集
train_dataset = datasets.DenoisingAutoEncoderDataset(train_sentences)
# DataLoader 批量处理数据
train_dataloader = DataLoader(train_dataset, batch_size=8, shuffle=True)
# 使用去噪自动编码器损失
train_loss = losses.DenoisingAutoEncoderLoss(model, decoder_name_or_path=model_name, tie_encoder_decoder=True)
# 模型训练
model.fit(
train_objectives=[(train_dataloader, train_loss)],
epochs=1,
weight_decay=0,
scheduler='constantlr',
optimizer_params='lr': 3e-5,
show_progress_bar=True
)
以上是关于搜索与问答——EMNLP 2021TSDAE:基于Transformer的顺序去噪自动编码器的主要内容,如果未能解决你的问题,请参考以下文章