预训练句子表征——EMNLP 2021SimCSE
Posted 卓寿杰SoulJoy
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了预训练句子表征——EMNLP 2021SimCSE相关的知识,希望对你有一定的参考价值。
1. 介绍
SimCSE(Simple Contrastive Learning of Sentence Embeddings)是一种简单在没有监督训练数据的情况下训练句子向量的对比学习方法。
这个方法是对同一个句子进行两次编码。由于在 Transformer 模型中使用了 dropout,两个句子表征的位置将略有不同。这两个表征之间的距离将被最小化,而同一批中其他句子的其他表征的距离将被最大化(它们作为反例):
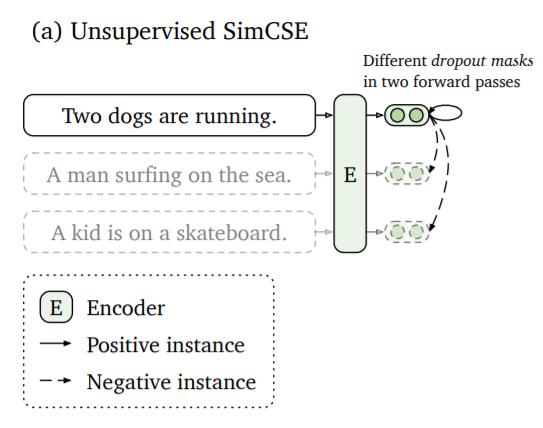
- 目标函数:
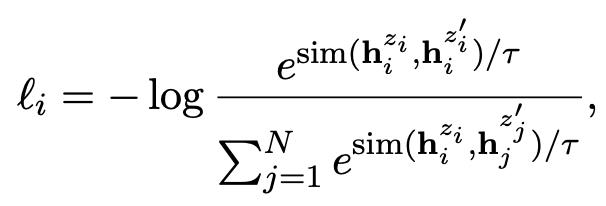
其中,z和z’ 是两个不同的dropout随机掩码。 h i z i , h i z i ′ h_i^{z_i},h_i^{z'_i} hizi,hizi′ 是相同句子 x i x_i xi输入相同编码器,但使用两个不同的dropout随机掩码而得到的向量。
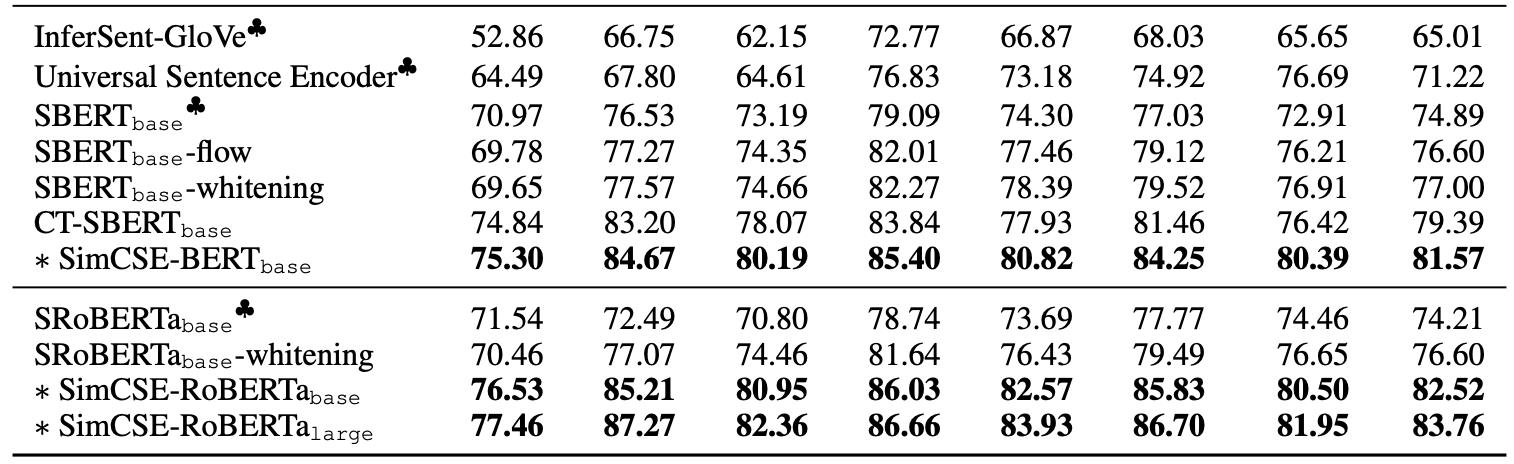
2. 实验效果
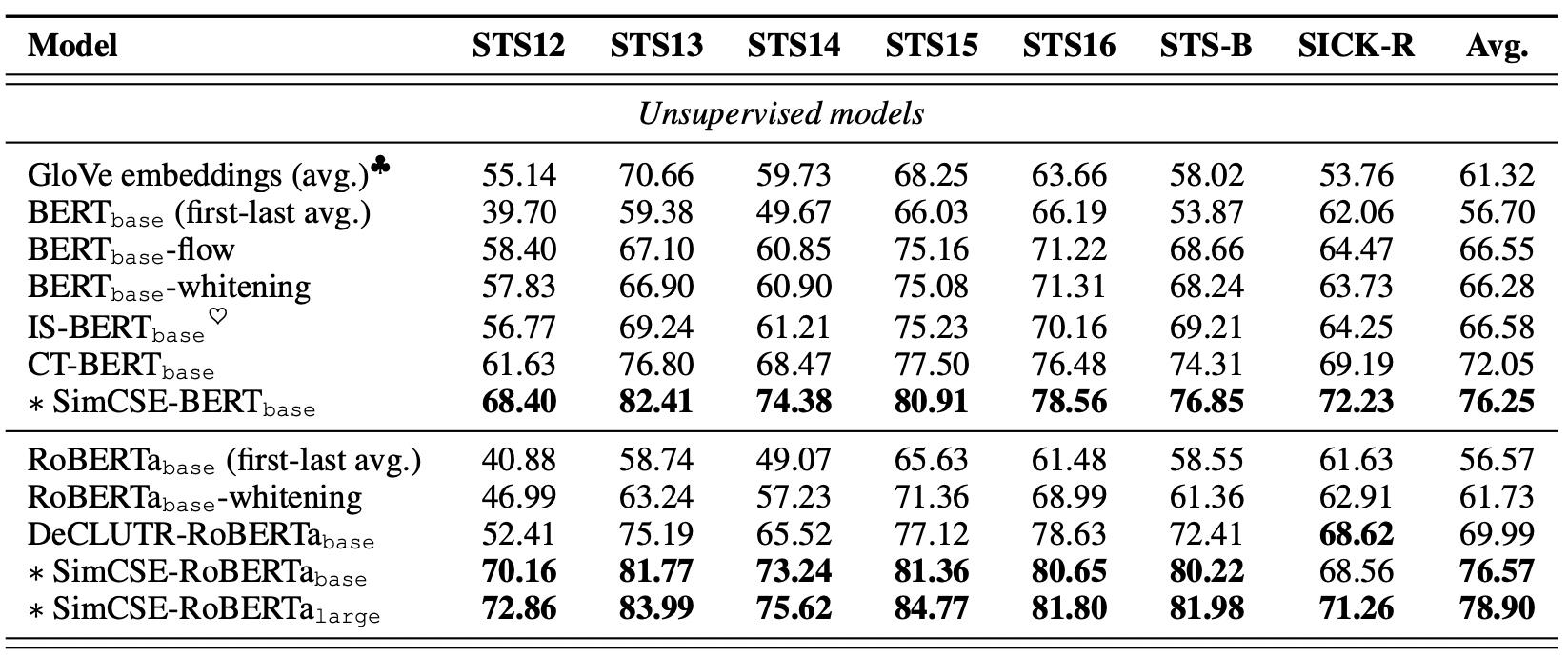
发现效果会比我之前介绍的CT要好
3. 实现
sentence_transformers已经把SimCSE已经封装成pip包,完整的训练流程例子可以参考《Sentence-BERT》。我们在此基础上只用修改loss就能轻松的训练SimCSE了:
from sentence_transformers import SentenceTransformer, InputExample
from sentence_transformers import models, losses
from torch.utils.data import DataLoader
# ……
train_loss = losses.MultipleNegativesRankingLoss(model)
# 训练模型
model.fit(
train_objectives=[(train_dataloader, train_loss)],
epochs=1,
show_progress_bar=True
)
4. 有监督的训练
SimCSE也可以用于有监督的数据上训练。我们构造的有监督数据形式为
(
x
i
,
x
i
+
,
x
i
−
)
(x_i,x_i^+,x_i^-)
(xi,xi+,xi−)。简单来说,就是在训练时不只是把
x
i
−
x_i^-
xi−视为负例,且把同batch其他句子的正负例都视为句子i的负例:
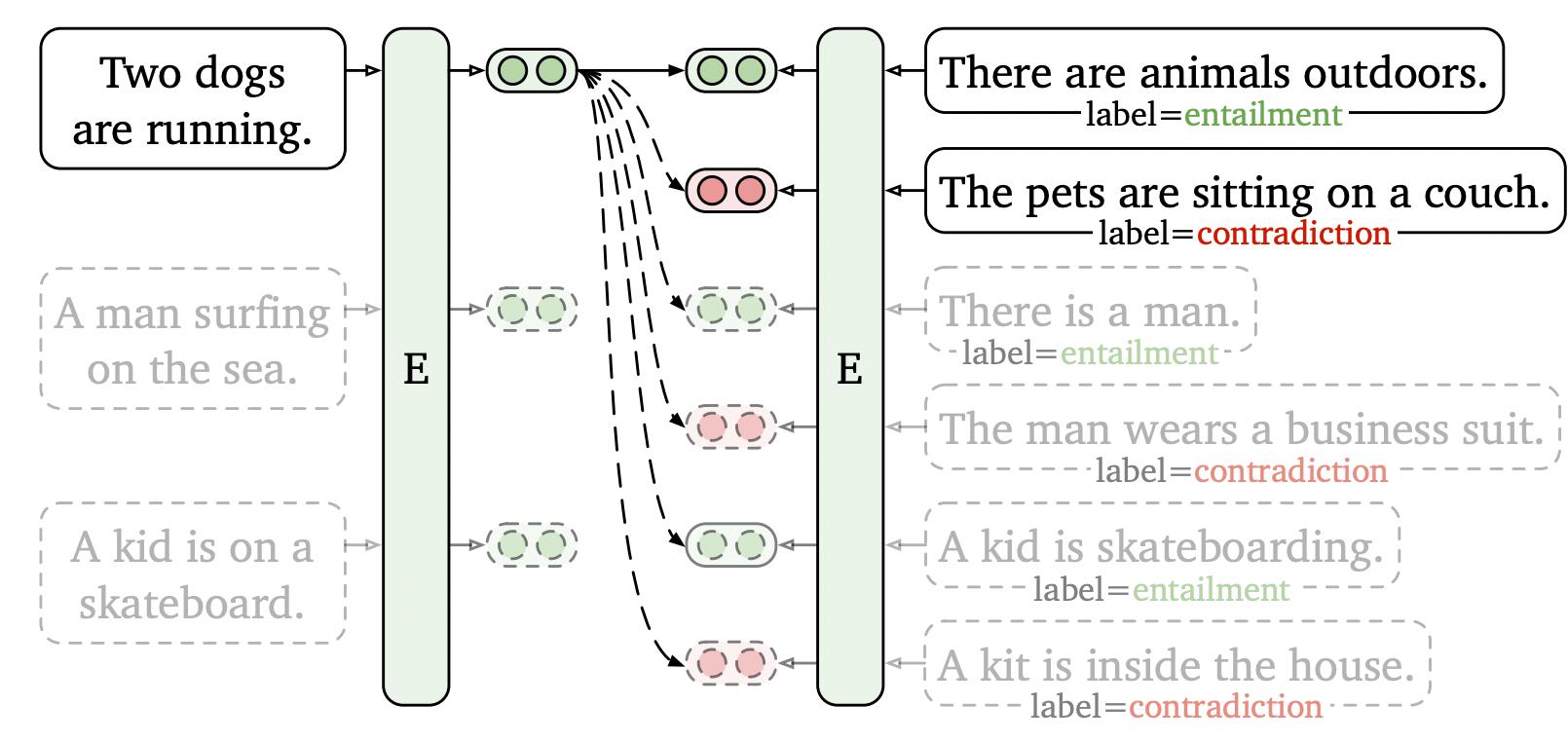
目标函数为:

实验效果:
以上是关于预训练句子表征——EMNLP 2021SimCSE的主要内容,如果未能解决你的问题,请参考以下文章