大数据基石-Hadoop3.x学习教程-Hadoop产品了解与快速上手
Posted roykingw
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据基石-Hadoop3.x学习教程-Hadoop产品了解与快速上手相关的知识,希望对你有一定的参考价值。
大数据基石-Hadoop
Hadoop3.x版本全系列教程
=== 楼兰 ===文章目录
一、关于Hadoop
1、关于Hadoop产品
首先,关于Hadoop的重要性
对于Hadoop的重要性,再怎么强调也不过分。他可以说是开源大数据领域的开辟之作。Hadoop产品的推出,成了大数据时代来临的一个重要标志。整个开源的大数据领域,可以说都是以Hadoop为基础,才构建成熟起来的,所以也是学习大数据绕不开的一个产品。
Hadoop的设计思想,来源于Google的三篇论文。长久以来,各大互联网公司都在注重构建服务,业务数据的问题还没有显现出来。而像Google这样的搜索引擎公司,凭借其特殊的行业地位,最早接触到了海量数据造成的一系列问题。而对于海量数据的处理,也就只能由Google这样的搜索引擎公司率先进行深入的研究。
2003年,Google发布Google File System论文,(GFS)这是一个可扩展的分布式文件系统,用于大型的、分布式的、对大量数据进行访问的应用。它运行于廉价的普通硬件上,提供容错功能。从根本上说:文件被分割成很多块,使用冗余的方式储存于商用机器集群上。
紧随其后,2004年,Google公布了MapReduce论文,论文描述了大数据的分布式计算方式,主要思想是将任务分解然后在多台处理能力较弱的计算节点中同时处理,然后将结果合并从而完成大数据处理。
接着到了2006年,Google公布了BigTable论文,BigTable是一种构建于GFS和MapReduce之上的多维稀疏图管理工具。
正是这三篇论文,掀起了开源软件的大数据热潮。人们根据GFS,开发出了HDFS文件存储系统。而MapReduce计算框架,成了第一代大数据的计算标准。最终HDFS和MapReduce就合并形成了最早的Hadoop产品。BigTable最终形成了HBase产品。这也构成了大数据处理的基石。
Hadoop产品的创始人是Doug Cutting。而Hadoop的Logo,其实是Doug Cutting儿子的一个玩具大象。

Hadoop最早诞生于Cutting于1998年左右开发的一个全文文本搜索引擎Lucene,这个搜索引擎在2001年成为Apache基金会的一个子项目,也是ElasticSearch等重要搜索引擎的底层基础。然后到2004年,Cutting联合同为程序员出生的Mike Cafarella开发了一款开源的搜索引擎,成为Nutch。而接触到Google的论文之后,Doug Cutting对Lucene进行深入打磨,最终于2006年形成了Hadoop产品。可以看到,Hadoop产品是从海量数据的搜索起家,逐渐成长成为了一个集存储、检索、计算于一体的综合性产品。而随着以Hadoop为核心的周边生态不断成熟,Hadoop也成为了现代大数据技术的代名词。

然后,关于Hadoop的产品版本
Hadoop目前是Apache基金会非常重要的一个顶级项目。项目官方: https://hadoop.apache.org/
从官网的这段简单的介绍可以看到Hadoop的特点。 高可靠,高可扩展, 分布式以及高容错。并且,Hadoop允许使用廉价的普通计算机来构建庞大的服务器网络,一部分节点的损坏并不会影响整个服务的可靠性。这一点可以说从根本上改变了大数据的技术面貌,对海量数据的处理不用再完全依靠高配置的服务器。从而使得互联网企业的数据处理能力突破了服务器的限制,间接催生出了整个大数据的生态体系。例如现在广泛引用的Zookeeper,最早就是Hadoop中的一个子项目。而在Hadoop官网,也能看到一系列与Hadoop相关的项目。

然后,在Apache之外,Hadoop还有另外一个发行版本,就是Cloudera内部集成的版本,成为CDH版本。Cloudera是Doug Cutting后来进入的一家公司,其主要的业务就是为企业搭建基于Hadoop的整个大数据组件体系。而CDH是其中最为重要的产品。通过对开源的大数据组件进行修改封装,再由CDH提供统一的搭建管理方案,就形成了商业化的大数据产品体系。通过CDH可以很好的解决不同大数据组件之间的版本兼容问题。 Apache的另一个顶级项目Ambari也是提供同样的功能,不过免费的开源产品毕竟没有商用的CDH靠谱。
早前还有另外一个同样进行大数据组件商业化的公司Hortonworks,Ambari就是该公司的一个项目。经过多年与CDH的竞争,最终于2018年被CDH公司收购,合并到了CDH产品中。早期的CDH对个人用户是免费的,只对商业用户收费。但是在完成并购后,到2021年,CDH就不再对个人用户开放。需要收费订阅才能获取CDH。
所以现在搭建Hadoop服务及其周边的相关服务,有两种方式,一种是通过集成工具如CDH、Ambari进行搭建,另一种是下载Apache的开源版本手动搭建。第一种方式适合商业用户。搭建方式简单易行,只要页面上点点就可以,并且可以很好的解决不同组件之间的版本兼容问题,所以可靠性高。而第二种方式比较适合个人用户。搭建方式比较麻烦,需要自行进行大量的配置工作,并且不同组件之间的版本兼容性很多情况下只能靠经验来解决。综合考虑,第二种方式其实更能够了解这些产品的底层原理,所以,我们的大数据课程都会采用第二种方式手动搭建大数据的相关服务。
2、Hadoop课程内容
Hadoop非常重要,市面上其他的课程也都已经很多。而我们这个课程,将会是关于Hadoop的集大成版本。面向当前较新的Hadoop版本,以官方文档和官方示例为主体进行深入解读。同时参考吸收其他课程的优点以及大量的工程实践经验,仔细研读,一步步带你彻底理解Hadoop产品以及背后的设计精髓。
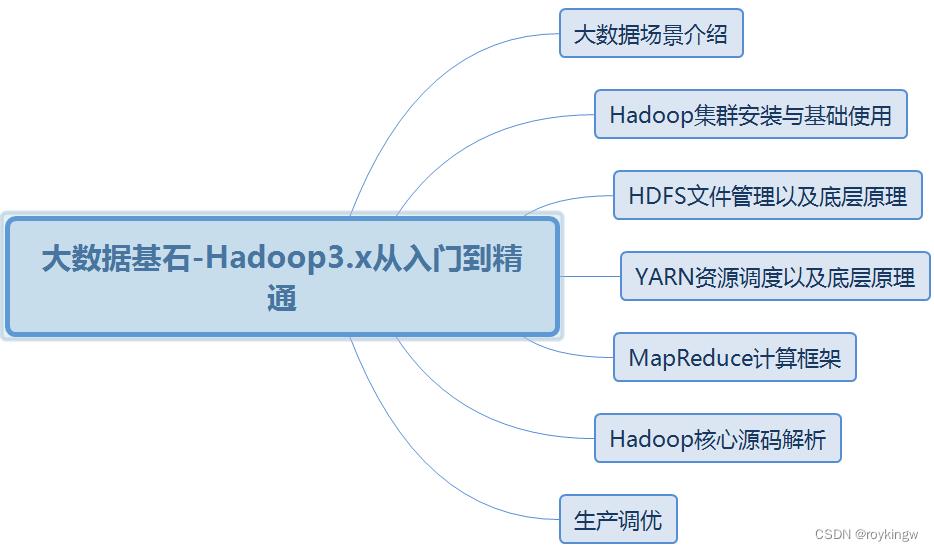
3、Hadoop的主要组件
Hadoop的1.X版本中,就包含MapReduce、HDFS和Common基础工具三个模块。从2.X版本开始,新加入了Yarn作为资源调度的组件。到目前3.X版本,功能组件没有大的变化。
其中,HDFS是一个分布式的文件系统,主要负责文件的存储。由 NameNode、Secondary NameNode和DataNode三种节点组成。HDFS上的文件,会以文件块(Block)的形式存储到不同的DataNode节点当中。NameNode则用来存储文件的相关元数据,比如文件名、文件目录结果、文件的块列表等。然后Secondary NameNode则负责每隔一段时间对NameNode上的元数据进行备份。整体结构如下图所示:

其中Rack表示机器机架。Hadoop会将文件优先存储在同机架的节点上,这样可以加快文件的读写效率。
而Yarn是一个资源调度的工具,负责对服务器集群内的计算资源,主要是CPU和内存,进行合理的分配与调度。由ResourceManager和NodeManager两种节点组成。ResourceManager负责对系统内的计算资源进行调度分配,将计算任务分配到具体的NodeManger节点上执行。而NodeManager则负责具体的计算任务执行。整体结构如下图:
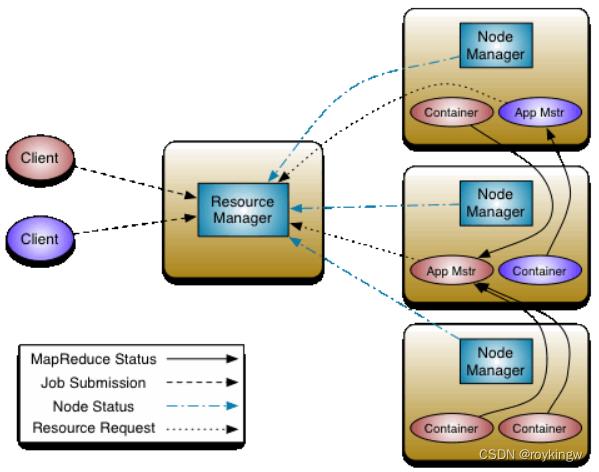
https://hadoop.apache.org/docs/r3.2.2/hadoop-yarn/hadoop-yarn-site/YARN.html
最后 MapReduce则是Hadoop中提供的一种大数据的计算框架。他定义了一种基于Mapper和Reducer两个阶段的分布式大数据计算框架,可以很好的基于廉价的普通计算机进行大批量数据的统一计算,而Yarn集群也可以为MapReduce计算提供非常高效的计算资源支持。MapReduce可以说是早期互联网进行海量数据计算的一丝曙光,但是随着像Spark、Flink等大数据计算框架不断成熟,MapReduce逐渐因为计算过于笨重,灵活性不够等原因,而稍显颓势。MapReduce计算框架本身虽然不再如大数据早期那么重要,但是MapReduce计算的思想,依然是大数据批量计算的重要参考。例如Spark中的批量计算功能,就可以简单理解为多个Mapepr和Reducer的自由组合。
在后续的学习过程中,我们的学习重点就是HDFS和YARN这两个框架,他们会为很多后续要学习的大数据组件提供支持。而MapReduce计算框架,则主要是要学习的他计算思想。
二、Hadoop环境搭建以及快速上手
课程中,我们将采用Apache的开源版本,手动搭建一个由三台服务器组成的Hadoop集群。关于Hadoop的服务搭建,我们选择的这种方式是最麻烦,最笨重的搭建方式,主要是为了带大家熟悉Hadoop。当你熟练了之后,可以有很多非常简单的快速搭建方式,例如使用CDH或者Ambari进行部署,只需要在页面上点点鼠标就可以快速完成搭建。也可以基于Docker,快速搭建别人已经搭建好的镜像。
1、Linux环境搭建
首先准备三台Linux服务器,预装CentOS7。三台服务器之间需要网络互通。我们实验环境的IP地址分别为:192.168.65.174,192.168.65.192,192.168.65.204。
内存配置建议不低于4G,硬盘空间建议不低于50G。
接下来按照以下步骤预先对服务器进行一些关键配置。
1》 配置hosts
在三台机器上分配修改/etc/hosts文件,统一加入下面内容:
192.168.65.174 hadoop01
192.168.65.204 hadoop02
192.168.65.192 hadoop03
这里是给每个机器配置一个机器名。后续集群中都会通过机器名进行配置管理,而不会再关注IP地址。
2》 关闭防火墙
Hadoop集群节点之间需要进行频繁复杂的网络交互,在实验环境建议关闭防火墙。生产环境下,可以根据情况选择是按照端口配置复杂的防火墙规则或者关闭内部防火墙,使用堡垒机进行统一防护。
systemctl stop firewalld
systemctl disable firewalld.service
3》 配置SSH免密
在hadoop01上生成密钥 ssh-keygen
将密钥分发到另外两台机器 ssh-copy-id hadoop02 这样配置完后, ssh hadoop02就不再需要输入密码了。这里注意每个节点都要配置,包括当前节点。
4》 安装JDK
尽量不要使用Linux自带的OpenJDK。卸载指令: rpm -qa | grep -i java | xargs -n1 rpm -e --nodeps
然后自行下载JDKjdk-8u212-linux-x64.tar.gz。解压到/app/java目录。
然后在~/.bash_profile中配置JAVA_HOME目录,指向JDK的安装目录。并将$JAVA_HOME/bin目录配置到Path环境变量中。
export JAVA_HOME=/app/java/jdk1.8.0_212/
PATH=$PATH:$JAVA_HOME/bin:$HOME/bin
export PATH
安装过程略过。安装完成后检查JDK的安装版本。
[root@192-168-65-174 bin]# java -version
java version "1.8.0_212"
Java(TM) SE Runtime Environment (build 1.8.0_212-b10)
Java HotSpot(TM) 64-Bit Server VM (build 25.212-b10, mixed mode)
5》 创建用户(可选)
在我们这次实验中,会直接使用系统提供的root用户来直接进行操作。但是通常在正是的生产环境中,root用户都是要被严格管控的,这时就需要单独创建一个用户来管理这些应用。
2、Hadoop集群搭建
Hadoop目前最新的版本是2021年六月15号发布的3.3.1版本。我们这次就不选择最新的版本,因为最新版本容易产生很多问题,尤其是与其他组件的版本兼容问题,这是非常麻烦的。所以选择次新的3.2.2版本。3.2.2版本的下载地址:https://hadoop.apache.org/release/3.2.2.html 。 这里下载运行版本 hadoop-3.2.2.tar.gz。
在实际生产环境中,通常都会下载源码包,自行打包。
在开始安装之前,需要对集群中机器的角色进行规划。对于我们这个集群,角色规划如下:
| hadoop01 | hadoop02 | hadoop03 | |
|---|---|---|---|
| HDFS | NameNode DataNode | DataNode | SecondaryNameNode DataNode |
| YARN | NodeManager | ResourceManager NodeManager | NodeManager |
step1 : 将下载好的hadoop-3.2.2.tar.gz上传到hadoop01机器,解压到/app/hadoop目录。接下来添加环境变量HADOOP_HOME指向hadoop的安装目录,并将$HADOOP_HOME/bin 目录配置到path环境变量当中。
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
export HADOOP_PID_DIR=/app/hadoop
export HADOOP_HOME=/app/hadoop/hadoop-3.2.2/
PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$JAVA_HOME/bin:$HOME/bin
export PATH
hadoop的主要配置文件在 $HADOOP_HOME/etc/hadoop目录下。依次配置以下几个文件。
1- core-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 指定 NameNode 的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop01:8020</value>
</property>
<!-- 指定 hadoop 数据的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/app/hadoop/hadoop-3.2.2/data</value>
</property>
<!-- 配置 HDFS 网页登录使用的静态用户为当前操作系统用户 -->
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
</configuration>
2- hdfs-site.xml
<configuration>
<!-- NameNode web 端访问地址-->
<property>
<name>dfs.namenode.http-address</name>
<value>hadoop01:9870</value>
</property>
<!-- 2NameNode web 端访问地址-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop03:9868</value>
</property>
<!-- 备份数量 -->
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<!-- 打开webhdfs -->
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
</configuration>
3- yarn-site.xml
<configuration>
<!-- 指定 MR 走 shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定 ResourceManager 的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop02</value>
</property>
<!-- 环境变量的继承 跑示例时要用到-->
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
<!-- 开启日志聚集功能 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 设置日志聚集服务器地址 -->
<property>
<name>yarn.log.server.url</name>
<value>http://hadoop01:19888/jobhistory/logs</value>
</property>
<!-- 设置日志保留时间为 7 天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
</configuration>
4- mapred-site.xml
<configuration>
<!-- 指定 MapReduce 程序运行在 Yarn 上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- 历史服务器 web 端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop01:19888</value>
</property>
</configuration>
5- workers
hadoop01
hadoop02
hadoop03
step 2: 将配置完成后的hadoop整体分发到另外的节点。
scp ~/.bash_profile root@hadoop02:~
scp -r /app/hadoop root@hadoop02:/app/hadoop
scp ~/.bash_profile root@hadoop03:~
scp -r /app/hadoop root@hadoop03:/app/hadoop
step3: 启动hadoop各项服务。
先启动hdfs服务:
第一次启动hdfs服务时,需要先对NameNode进行格式化。在NameNode所在的Hadoop01机器,执行hadoop namenode -format执行,完成初始化。初始化完成后,会在 /app/hadoop/hadoop-3.2.2/data/dfs/name/current目录下创建一个NameNode的镜像。
接下来可以尝试启动hdfs了。 hadoop的启动脚本在hadoop下的sbin目录下。 start-dfs.sh就是启动hdfs的脚本。
注意:1、sbin目录下有个start-all.sh脚本,是一次启动Hadoop所有服务的脚本。但是由于hadoop各个服务在启动过程中很容易出问题,所以通常不建议使用这个脚本,而是一个个服务单独启动。
2、启动hdfs最好是在NameNode上启动。
3、当前版本hadoop如果不创建单独用户,而是直接使用root用户启动,会报错的。这时就需要添加之前配置的HDFS_NAMENODE_USER等几个环境变量。
4、在当前实验中,第一次启动还遇到报错,说JAVA_HOME环境变量没有配置,这也是root用户的原因。解决的方法是在 sbin/hadoop-env.sh 脚本中声明一下环境变量。修改其中 export JAVA_HOME=/app/java/jdk1.8.0_212/这一行。
启动没问题的话,可以用jps来确认各个服务器上的进程状态。 进程名 DataNode: 数据节点。 NameNode 名称服务; SecondaryNameNode 备份名称服务。
然后访问 http://hadoop01:9870 ,可以访问到HDFS的Web页面。
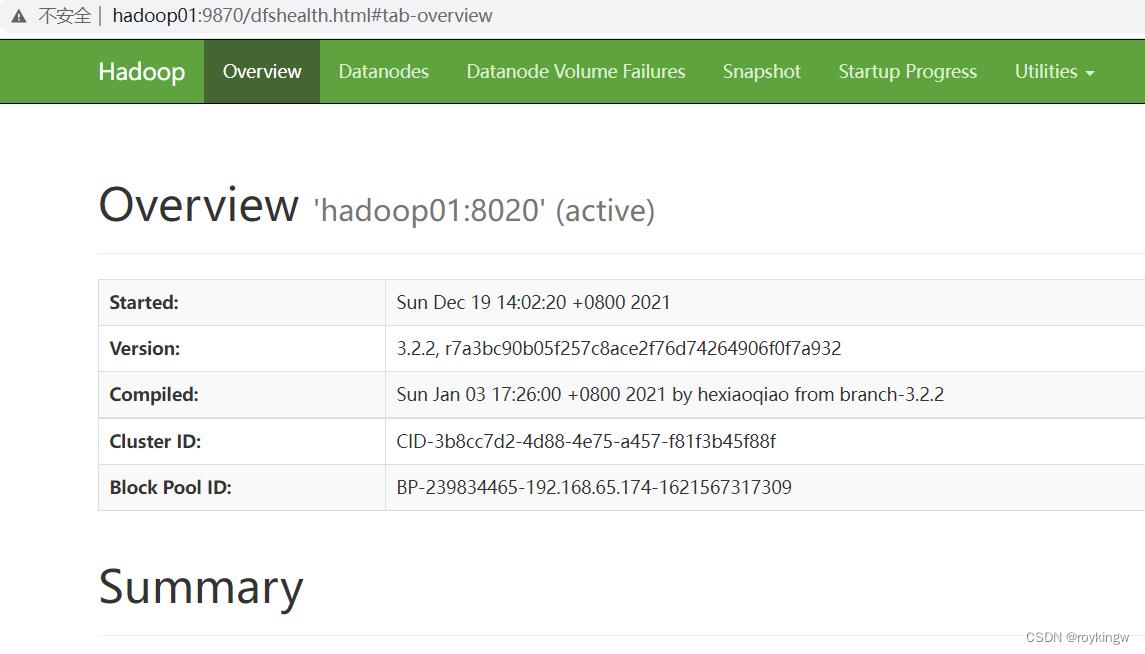
该页面上会列出集群整体的状态信息。
这个9870端口是非常重要的一个端口,要开始熟悉起来。在老版本的hadoop中,默认的是50070。
接下来启动Yarn:
yarn的启动脚本为start-yarn.sh。 同样建议在ResourceManger节点上启动。
启动完成后,也需要使用jps来确认进程状态。进程名: ResourceManager: 管理节点。 NodeManager: 工作节点。
注意下在yarn-site.xml中配置了日志聚合,将yarn的执行日志配置到了hdfs上。所以yarn建议在hdfs后启动。当然,在生产环境下需要评估这种日志方式是否合适。
yarn启动完成后,可以进入ResourceManager机器的8088端口访问到yarn的管理页面。
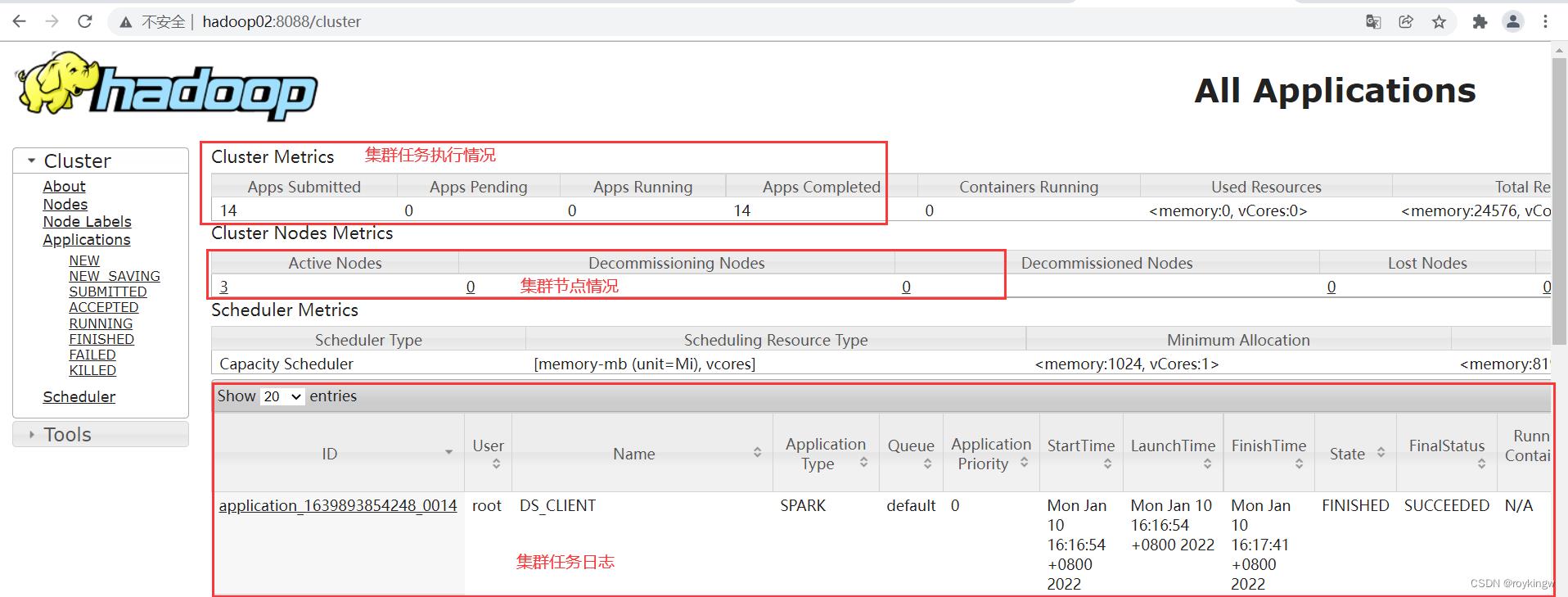
配置历史记录服务器:
当前版本Hadoop提供了一个HistoryServer服务,可以用来查看所有的MapReduce任务的提交执行日志。也建议一并打开。
配置方式是在 mapred-site.xml中配置的mapreduce.jobhistory.webapp.address属性。
启动服务的指令:mapred --daemon start historyserver 停止服务的指令:mapred --daemon stop historyserver
这个服务启动完成后,用JPS可以看到一个JobHistoryServer服务。
并且访问hadoop01:19888,就可以查看到对应的Web页面。

最终所有任务启动完成后,JPS查看到的进程状态是这样的:

1、通过进程确认各个服务的状态,这是需要锻炼的一个技能。以后大数据的组件多了之后,这些进程信息就会越越来越重要。
2、Hadoop的所有配置信息已经整理到资料当中。
3、Hadoop快速上手
集群搭建完成后,就可以简单体验一下Hadoop的基础功能。
首先是HDFS文件管理功能。
对HDFS上的文件管理,可以通过hadoop fs指令进行。直接敲hadoop fs 就能看到指令的提示信息。
[root@hadoop03 ~]# hadoop fs
Usage: hadoop fs [generic options]
[-appendToFile <localsrc> ... <dst>]
[-cat [-ignoreCrc] <src> ...]
[-checksum <src> ...]
[-chgrp [-R] GROUP PATH...]
[-chmod [-R] <MODE[,MODE]... | OCTALMODE> PATH...]
[-chown [-R] [OWNER][:[GROUP]] PATH...]
[-copyFromLocal [-f] [-p] [-l] [-d] [-t <thread count>] <localsrc> ... <dst>]
[-copyToLocal [-f] [-p] [-ignoreCrc] [-crc] <src> ... <localdst>]
[-count [-q] [-h] [-v] [-t [<storage type>]] [-u] [-x] [-e] <path> ...]
[-cp [-f] [-p | -p[topax]] [-d] <src> ... <dst>]
[-createSnapshot <snapshotDir> [<snapshotName>]]
[-deleteSnapshot <snapshotDir> <snapshotName>]
[-df [-h] [<path> ...]]
[-du [-s] [-h] [-v] [-x] <path> ...]
[-expunge [-immediate]]
[-find <path> ... <expression> ...]
[-get [-f] [-p] [-ignoreCrc] [-crc] <src> ... <localdst>]
[-getfacl [-R] <path>]
[-getfattr [-R] -n name | -d [-e en] <path>]
[-getmerge [-nl] [-skip-empty-file] <src> <localdst>]
[-head <file>]
[-help [cmd ...]]
[-ls [-C] [-d] [-h] [-q] [-R] [-t] [-S] [-r] [-u] [-e] [<path> ...]]
[-mkdir [-p] <path> ...]
[-moveFromLocal [-f] [-p] [-l] [-d] <localsrc> ... <dst>]
[-moveToLocal <src> <localdst>]
[-mv <src> ... <dst>]
[-put [-f] [-p] [-l] [-d] [-t <thread count>] <localsrc> ... <dst>]
[-renameSnapshot <snapshotDir> <oldName> <newName>]
[-rm [-f] [-r|-R] [-skipTrash] [-safely] <src> ...]
[-rmdir [--ignore-fail-on-non-empty] <dir> ...]
[-setfacl [-R] [-b|-k -m|-x <acl_spec> <path>]|[--set <acl_spec> <path>]]
[-setfattr -n name [-v value] | -x name <path>]
[-setrep [-R] [-w] <rep> <path> ...]
[-stat [format] <path> ...]
[-tail [-f] [-s <sleep interval>] <file>]
[-test -[defswrz] <path>]
[-text [-ignoreCrc] <src> ...]
[-touch [-a] [-m] [-t TIMESTAMP ] [-c] <path> ...]
[-touchz <path> ...]
[-truncate [-w] <length> <path> ...]
[-usage [cmd ...]]
Generic options supported are:
-conf <configuration file> specify an application configuration file
-D <property=value> define a value for a given property
-fs <file:///|hdfs://namenode:port> specify default filesystem URL to use, overrides 'fs.defaultFS' property from configurations.
-jt <local|resourcemanager:port> specify a ResourceManager
-files <file1,...> specify a comma-separated list of files to be copied to the map reduce cluster
-libjars <jar1,...> specify a comma-separated list of jar files to be included in the classpath
-archives <archive1,...> specify a comma-separated list of archives to be unarchived on the compute machines
The general command line syntax is:
command [genericOptions] [commandOptions]
其实,抛开前面的hadoop fs 指令不说, hdfs的很多管理指令跟Linux是很像的。例如put上传文件, cat查看文件,cp复制文件,mv移动文件,mkdir创建目录等。
接下来简单体验一下。
先在hadoop01服务器本地编辑一个文件。
vim wdtest.txt
--随意输入一些文本
my name is roy
this is my bigdata lesson
welcome to my lesson
然后就可以将这个文件上传到hdfs上。这里我们将这个文件上传到hdfs的input目录下。
hadoop fs -put ~/wdtest.txt /input
上传的文件可以使用hadoop fs指令查看
[root@hadoop01 ~]# hadoop fs -cat /input/wdtest.txt
my name is roy
this is my bigdata lesson
welcome to my lesson
并且上传的文件也可以在HDFS的web页面通过定于的 Utilities -> Browse the file system查看。

然后其他的文件操作指令也可以自行尝试一下。
然后是Yarn资源管理以及MapReduce计算
yarn集群也有一个管理的指令yarn。 例如 yarn node -list -all 可以查看yarn集群的节点状态
[root@hadoop01 ~]# yarn node -list -all
2022-01-20 14:08:00,632 INFO client.RMProxy: Connecting to ResourceManager at hadoop02/192.168.65.204:8032
Total Nodes:3
Node-Id Node-State Node-Http-Address Number-of-Running-Containers
hadoop01:37258 RUNNING hadoop01:8042 0
hadoop03:36193 RUNNING hadoop03:8042 0
hadoop02:46362 RUNNING hadoop02:8042 0
这里就列出了yarn集群中的三个节点以及节点上正在执行的任务。yarn会为每个执行的
以上是关于大数据基石-Hadoop3.x学习教程-Hadoop产品了解与快速上手的主要内容,如果未能解决你的问题,请参考以下文章
大数据基石-Hadoop3.x学习教程-Hadoop产品了解与快速上手
大数据基石-Hadoop3.x学习教程-Hadoop产品了解与快速上手
大数据Hadoop2.x与Hadoop3.x相比较都有哪些变化
2021年大数据Hadoop(三十):Hadoop3.x的介绍