把字符串的增删查改,插入以及删除各种操作封装为一个用c代码写的库,代码怎么写,我写不来求教 Posted 2023-04-13
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了把字符串的增删查改,插入以及删除各种操作封装为一个用c代码写的库,代码怎么写,我写不来求教相关的知识,希望对你有一定的参考价值。
我比较笨,求尽量详细点的代码
C语言中没有输入输出语句,所有的输入输出功能都用ANSIC提供的一组标准库函数来实现。文件操作标准库函数有: 文件的打开操作fopen打开一个文件 文件的关闭操作fclose关闭一个文件 文件的读写操作fgetc从文件中读取一个字符 fputc写一个字符到文件中去 fgets从文件中读取一个字符串 fputs写一个字符串到文件中去 fprintf往文件中写格式化数据 fscanf格式化读取文件中数据 fread以二进制形式读取文件中的数据 fwrite以二进制形式写数据到文件中去 getw以二进制形式读取一个整数 putw以二进制形式存贮一个整数 文件状态检查函数feof文件结束 ferror文件读/写出错 clearerr清除文件错误标志 ftell了解文件指针的当前位置 文件定位函数rewind反绕 fseek随机定位#文件的打开 1.函数原型FILE*fopen(char*pname,char*mode) 2.功能说明 按照mode规定的方式,打开由pname指定的文件。若找不到由pname指定的相应文件,就按以下方式之一处理:(1)此时如mode规定按写方式打开文件,就按由pname指定的名字建立一个新文件;(2)此时如mode规定按读方式打开文件,就会产生一个错误。打开文件的作用是:(1)分配给打开文件一个FILE类型的文件结构体变量,并将有关信息填入文件结构体变量;(2)开辟一个缓冲区;(3)调用操作系统提供的打开文件或建立新文件功能,打开或建立指定文件;FILE*:指出fopen是一个返回文件类型的指针函数; 3.参数说明pname:是一个字符指针,它将指向要打开或建立的文件的文件名字符串。mode:是一个指向文件处理方式字符串的字符指针。所有可能的文件处理方式见表8.1 4.返回值 正常返回:被打开文件的文件指针。 异常返回:NULL,表示打开操作不成功。例如://定义一个名叫fp文件指针FILE*fp;//判断按读方式打开一个名叫test的文件是否失败if((fp=fopen("test","r"))==NULL)//打开操作不成功printf("Thefilecannotbeopened.\n"); exit(1);//结束程序的执行 要说明的是:C语言将计算机的输入输出设备都看作是文件。例如,键盘文件、屏幕文件等。ANSIC标准规定,在执行程序时系统先自动打开键盘、屏幕、错误三个文件。这三个文件的文件指针分别是:标准输入stdin、标准输出stdout和标准出错stderr。*文件的关闭1.函数原型intfclose(FILE*fp);2.功能说明 关闭由fp指出的文件。此时调用操作系统提供的文件关闭功能,关闭由fp->fd指出的文件;释放由fp指出的文件类型结构体变量;返回操作结果,即0或EOF。3.参数说明 fp:一个已打开文件的文件指针。4.返回值 正常返回:0。 异常返回:EOF,表示文件在关闭时发生错误。例如:intn=fclose(fp);*文件的读写操作A.从文件中读取一个字符 1.函数原型intfgetc(FILE*fp); 2.功能说明 从fp所指文件中读取一个字符。 3.参数说明 fp:这是个文件指针,它指出要从中读取字符的文件。 4.返回值 正常返回:返回读取字符的代码。 非正常返回:返回EOF。B.写一个字符到文件中去1.函数原型intfputc(intch,FILE*fp)2.功能说明 把ch中的字符写入由fp指出的文件中去。3.参数说明 ch:是一个整型变量,内存要写到文件中的字符(C语言中整型量和字符量可以通用)。 fp:这是个文件指针,指出要在其中写入字符的文件。4.返回值 正常返回:要写入字符的代码。 非正常返回:返回EOF。例如,要往"读打开"文件中写一个字符时,会发生错误而返回一个EOF。C.从文件中读取一个字符串1.函数原型 char*fgets(char*str,intn,FILE*fp)2.功能说明 从由fp指出的文件中读取n-1个字符,并把它们存放到由str指出的字符数组中去,最后加上一个字符串结束符'\0'。3.参数说明 str:接收字符串的内存地址,可以是数组名,也可以是指针。 n:指出要读取字符的个数。 fp:这是个文件指针,指出要从中读取字符的文件。4.返回值正常返回:返回字符串的内存首地址,即str的值。非正常返回:返回一个NULL值,此时应当用feof()或ferror()函数来判别是读取到了文件尾,还是发生了错误。例如,要从"写打开"文件中读取字符串,将发生错误而返回一个NULL值。D.写一个字符串到文件中去1.函数原型intfputs(char*str,FILE*fp)2.功能说明 把由str指出的字符串写入到fp所指的文件中去。3.参数说明 str:指出要写到文件中去的字符串。 fp:这是个文件指针,指出字符串要写入其中的文件。4.返回值 正常返回:写入文件的字符个数,即字符串的长度。 非正常返回:返回一个NULL值,此时应当用feof()或ferror()函数来判别是读取到了文件尾,还是发生了错误。例如,要往一个"读打开"文件中写字符串时,会发生错误而返回一个NULL值。E.往文件中写格式化数据1.函数原型intfprintf(FILE*fp,char*format,arg_list)2.功能说明 将变量表列(arg_list)中的数据,按照format指出的格式,写入由fp指定的文件。fprintf()函数与printf()函数的功能相同,只是printf()函数是将数据写入屏幕文件(stdout)。3.参数说明 fp:这是个文件指针,指出要将数据写入的文件。 format:这是个指向字符串的字符指针,字符串中含有要写出数据的格式,所以该字符串成为格式串。格式串描述的规则与printf()函数中的格式串相同。arg_list:是要写入文件的变量表列,各变量之间用逗号分隔。4.返回值 无。G.以二进制形式读取文件中的数据1.函数原型intfread(void*buffer,unsignedsife,unsignedcount,FILE*fp)2.功能说明 从由fp指定的文件中,按二进制形式将sife*count个数据读到由buffer指出的数据区中。3.参数说明buffer:这是一个void型指针,指出要将读入数据存放在其中的存储区首地址。sife:指出一个数据块的字节数,即一个数据块的大小尺寸。count:指出一次读入多少个数据块(sife)。fp:这是个文件指针,指出要从其中读出数据的文件。4.返回值 正常返回:实际读取数据块的个数,即count。 异常返回:如果文件中剩下的数据块个数少于参数中count指出的个数,或者发生了错误,返回0值。此时可以用feof()和ferror()来判定到底出现了什么情况。H.以二进制形式写数据到文件中去1.函数原型intfwrite(void*buffer,unsignedsife,unsignedcount,FILE*fp)2.功能说明 按二进制形式,将由buffer指定的数据缓冲区内的sife*count个数据写入由fp指定的文件中去。3.参数说明buffer:这是一个void型指针,指出要将其中数据输出到文件的缓冲区首地址。sife:指出一个数据块的字节数,即一个数据块的大小尺寸。count:一次输出多少个数据块(sife)。fp:这是个文件指针,指出要从其中读出数据的文件。4.返回值 正常返回:实际输出数据块的个数,即count。 异常返回:返回0值,表示输出结束或发生了错误。I.以二进制形式读取一个整数1.函数原型intgetw(FILE*fp)2.功能说明 从由fp指定的文件中,以二进制形式读取一个整数。3.参数说明 fp:是文件指针。4.返回值 正常返回:所读取整数的值。 异常返回:返回EOF,即-1。由于读取的整数值有可能是-1,所以必须用feof()或ferror()来判断是到了文件结束,还是出现了一个出错。J.以二进制形式存贮一个整数1.函数原型intputw(intn,FILE*fp)2.功能说明 以二进制形式把由变量n指出的整数值存放到由fp指定的文件中。3.参数说明 n:要存入文件的整数。 fp:是文件指针。4.返回值 正常返回:所输出的整数值。 异常返回:返回EOF,即-1。由于输出的整数值有可能是-1,所以必须用feof()或ferror()来判断是到了文件结束,还是出现了一个出错。*文件状态检查A.文件结束(1)函数原型intfeof(FILE*fp)(2)功能说明 该函数用来判断文件是否结束。(3)参数说明 fp:文件指针。(4)返回值 0:假值,表示文件未结束。 1:真值,表示文件结束。B.文件读/写出错(1)函数原型intferror(FILE*fp)(2)功能说明 检查由fp指定的文件在读写时是否出错。(3)参数说明 fp:文件指针。(4)返回值 0:假值,表示无错误。 1:真值,表示出错。C.清除文件错误标志(1)函数原型voidclearerr(FILE*fp)(2)功能说明 清除由fp指定文件的错误标志。(3)参数说明 fp:文件指针。(4)返回值 无。D.了解文件指针的当前位置(1)函数原型longftell(FILE*fp)(2)功能说明 取得由fp指定文件的当前读/写位置,该位置值用相对于文件开头的位移量来表示。(3)参数说明 fp:文件指针。(4)返回值 正常返回:位移量(这是个长整数)。 异常返回:-1,表示出错。(5)实例*文件定位A.反绕(1)函数原型voidrewind(FILE*fp)(2)功能说明 使由文件指针fp指定的文件的位置指针重新指向文件的开头位置。(3)参数说明 fp:文件指针。(4)返回值 无。(5)实B.随机定位(1)函数原型intfseek(FILE*fp,longoffset,intbase)(2)功能说明 使文件指针fp移到基于base的相对位置offset处。(3)参数说明 fp:文件指针。 offset:相对base的字节位移量。这是个长整数,用以支持大于64KB的文件。 base:文件位置指针移动的基准位置,是计算文件位置指针位移的基点。ANSIC定义了base的可能取值,以及这些取值的符号常量。(4)返回值 正常返回:当前指针位置。 异常返回:-1,表示定位操作出错。*关于exit()函数1.函数原型voidexit(intstatus)2.功能说明 exit()函数使程序立即终止执行,同时将缓冲区中剩余的数据输出并关闭所有已经打开的文件。3.参数说明 status:为0值表示程序正常终止,为非0值表示一个定义错误。4.返回值 无。*关于feof()函数1.函数原型intfeof(FILE*fp)2.功能说明 在文本文件(ASCII文件)中可以用值为-1的符号常量EOF来作为文件的结束符。但是在二进制文件中-1往往可能是一个有意义的数据,因此不能用它来作为文件的结束标志。为了能有效判别文件是否结束,ANSIC提供了标准函数feof(),用来识别文件是否结束。3.参数说明 fp:文件指针。4.返回值 返回为非0值:已到文件尾。 返回为0值:表示还未到文件尾。
参考技术A
这个工作量有点大,你可以先网上找C标准库来学习参考下。
MySQL 表的增删查改
文章目录
例:
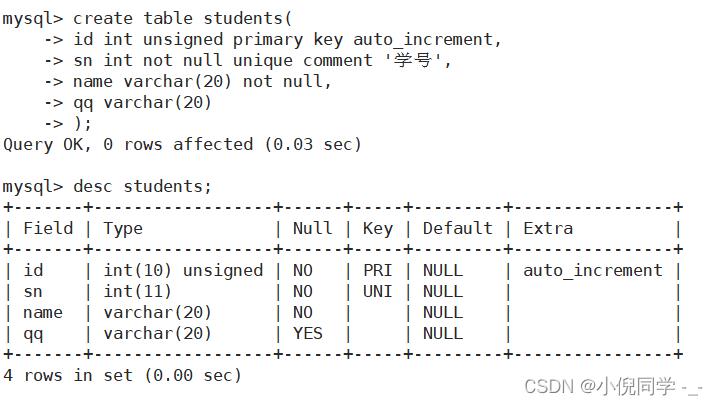
创建一张学生表
value_list 数量必须和定义表的列的数量及顺序一致。
注意,这里id是主键,在插入的时候,可以不用指定id,此时mysql会使用默认的值进行自增。
当 主键 或者 唯一键 对应的值已经存在而导致插入失败时,可以选择性的进行同步更新操作。
语法:
INSERT . . . ON DUPLICATE KEY UPDATE column = value [ , column = value] . . .
当我们更新时代码下方会有数据
数据的含义如下
0 row affected: 表中有冲突数据,但冲突数据的值和 update 的值相等 1 row affected: 表中没有冲突数据,数据被插入 2 row affected: 表中有冲突数据,并且数据已经被更新 替换规则如下
主键 或者 唯一键 没有冲突,则直接插入 主键 或者 唯一键 如果冲突,则删除后再插入
上方数字的含义:
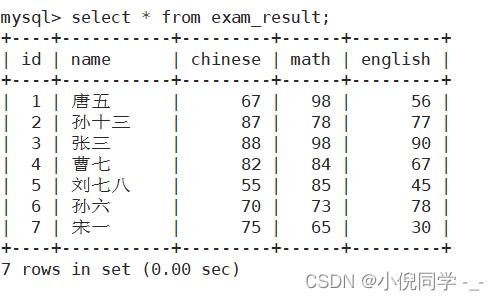
1 row affected: 表中没有冲突数据,数据被插入 2 row affected: 表中有冲突数据,删除后重新插入 先创建一个表格并向其中插入数据,方便下文检索。
全列查询就是将整个表格都打印出来
通常情况下不建议使用 * 进行全列查询,原因如下
查询的列越多,意味着需要传输的数据量越大 可能会影响到索引的使用 使用:
指定列的顺序不需要按定义表的顺序来
表达式包含一个字段
语法:
SELECT column [ AS] alias_name [ . . . ] FROM table_name;
比较运算符:
运算符 说明 >, >=, <, <= 大于,大于等于,小于,小于等于 = 等于,NULL 不安全,例如 NULL = NULL 的结果是 NULL <=> 等于,NULL 安全,例如 NULL <=> NULL 的结果是 TRUE(1) !=, <> 不等于 between a0 and a1 范围匹配,[a0, a1],如果 a0 <= value <= a1,返回 TRUE(1) in (option, …) 如果是 option 中的任意一个,返回 TRUE(1) IS NULL 是 NULL IS NOT NULL 不是 NULL LIKE 模糊匹配。% 表示任意多个(包括 0 个)任意字符;_ 表示任意一个字符
逻辑运算符:
运算符 说明 AND 多个条件必须都为 TRUE(1),结果才是 TRUE(1) OR 任意一个条件为 TRUE(1), 结果为 TRUE(1) NOT 条件为 TRUE(1),结果为 FALSE(0)
让我们通过下面的题目来熟悉上面的操作符
英语不及格的同学及英语成绩 ( < 60 )
语文成绩在 [80, 90] 分的同学及语文成绩
数学成绩是 58 或者 59 或者 98 或者 99 分的同学及数学成绩 使用 OR 进行条件连接
姓孙的同学 及 孙某同学 这里需要注意 % 和 _ 的区别
% 匹配任意多个(包括 0 个)任意字符 _ 匹配严格的一个任意字符
5.语文成绩好于英语成绩的同学
总分在 200 分以下的同学 注意:WHERE 条件中使用表达式 且 别名不能用在 WHERE 条件中
语文成绩 > 80 并且不姓孙的同学
孙某同学,否则要求总成绩 > 200 并且 语文成绩 < 数学成绩 并且 英语成绩 > 80
NULL 和 NULL 的比较,= 和 <=> 的区别
在排序中 ASC 为升序(从小到大) , DESC 为降序(从大到小)。
注意:没有 ORDER BY 子句的查询,返回的顺序是未定义的,永远不要依赖这个顺序
还有一点要注意的是NULL 视为比任何值都小,升序出现在最上面
使用实例:
同学及数学成绩,按数学成绩升序显示
查询同学各门成绩,依次按 数学降序,英语升序,语文升序的方式显示 当有多字段排序时,排序优先级随书写顺序
查询同学及总分,由高到低 ORDER BY 中可以使用表达式也可以使用列别名
查询姓孙的同学或者姓曹的同学数学成绩,结果按数学成绩由高到低显示
语法:
起始下标为 0
从 0 开始,筛选 n 条结果
SELECT . . . FROM table_name [ WHERE . . . ] [ ORDER BY . . . ] LIMIT n;
从 s 开始,筛选 n 条结果
SELECT . . . FROM table_name [ WHERE . . . ] [ ORDER BY . . . ] LIMIT s, n;
从 s 开始,筛选 n 条结果,比第二种用法更明确,建议使用
SELECT . . . FROM table_name [ WHERE . . . ] [ ORDER BY . . . ] LIMIT n OFFSET s;
建议:对未知表进行查询时,最好加一条 LIMIT 1,避免因为表中数据过大,查询全表数据导致数据库卡死
按 id 进行分页,每页 3 条记录,分别显示 第 1、2、3 页
语法:
UPDATE table_name SET column = expr [, column = expr …] [WHERE …] [ORDER BY …] [LIMIT …]
例:
将孙十三同学的数学成绩变更为 80 分
将曹七同学的数学成绩变更为 60 分,语文成绩变更为 70 分
将总成绩倒数前三的 3 位同学的数学成绩加上 30 分
注意:MySQL数据更新,不支持 math += 30 这种语法
将所有同学的语文成绩加5分
语法:
DELETE FROM table_name [WHERE …] [ORDER BY …] [LIMIT …]
例:
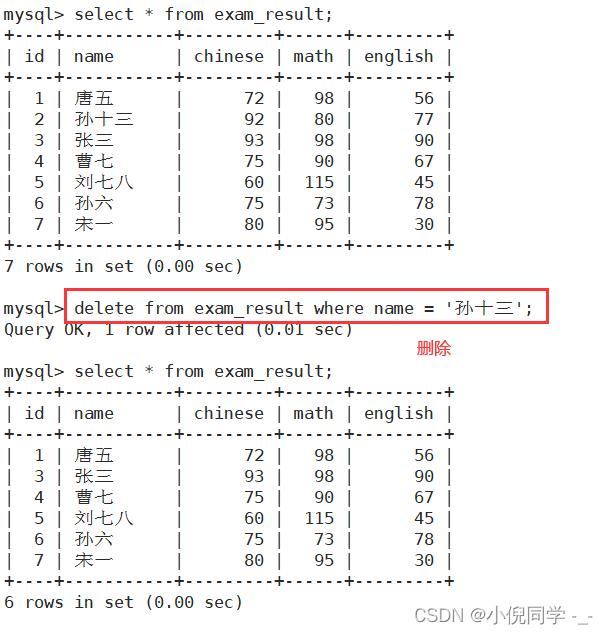
删除孙十三同学的考试成绩
删除整张表数据 注意:删除整表操作要慎用!
语法:
TRUNCATE [TABLE] table_name
注意:
只能对整表操作,不能像 DELETE 一样针对部分数据操作。 实际上 MySQL 不对数据操作,TRUNCATE在删除数据的时候,并不经过真正的事物,所以比 DELETE 更快,但是无法回滚。 TRUNCATE在删除数据的时候会重置 AUTO_INCREMENT 项
语法:
INSERT INTO table_name [(column [, column …])] SELECT …
例:
删除表中的的重复复记录,重复的数据只能有一份
函数 说明 COUNT([DISTINCT] expr) 返回查询到的数据的 数量 SUM([DISTINCT] expr) 返回查询到的数据的 总和,不是数字没有意义 AVG([DISTINCT] expr) 返回查询到的数据的 平均值,不是数字没有意义 MAX([DISTINCT] expr) 返回查询到的数据的 最大值,不是数字没有意义 MIN([DISTINCT] expr) 返回查询到的数据的 最小值,不是数字没有意义
案例:
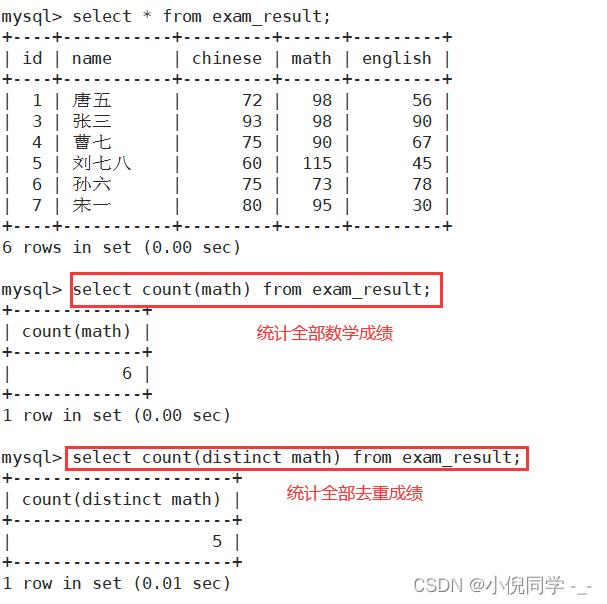
统计班级共有多少同学 使用 * 做统计,不受 NULL 影响
使用表达式做统计
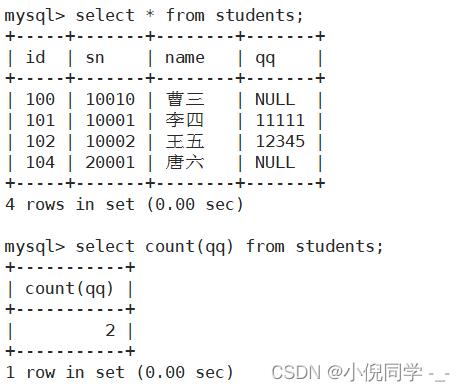
统计班级收集的 qq 号有多少(NULL不计入结果)
统计本次考试的数学成绩分数个数
统计数学成绩总分
统计平均总分
返回英语最高分
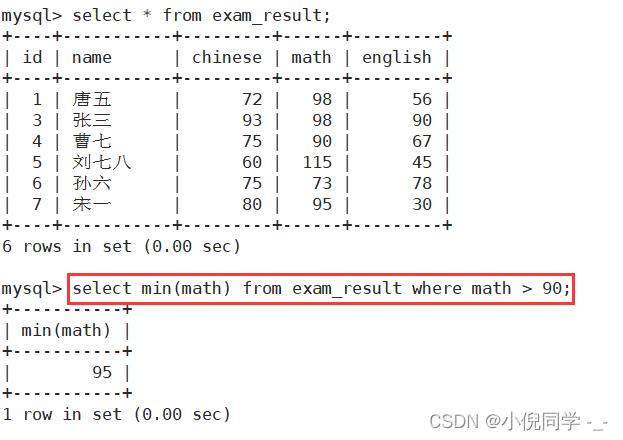
返回 > 90 分以上的数学最低分
在select中使用group by 子句可以对指定列进行分组查询
语法:
select column1, column2, . . from table group by column;
例:
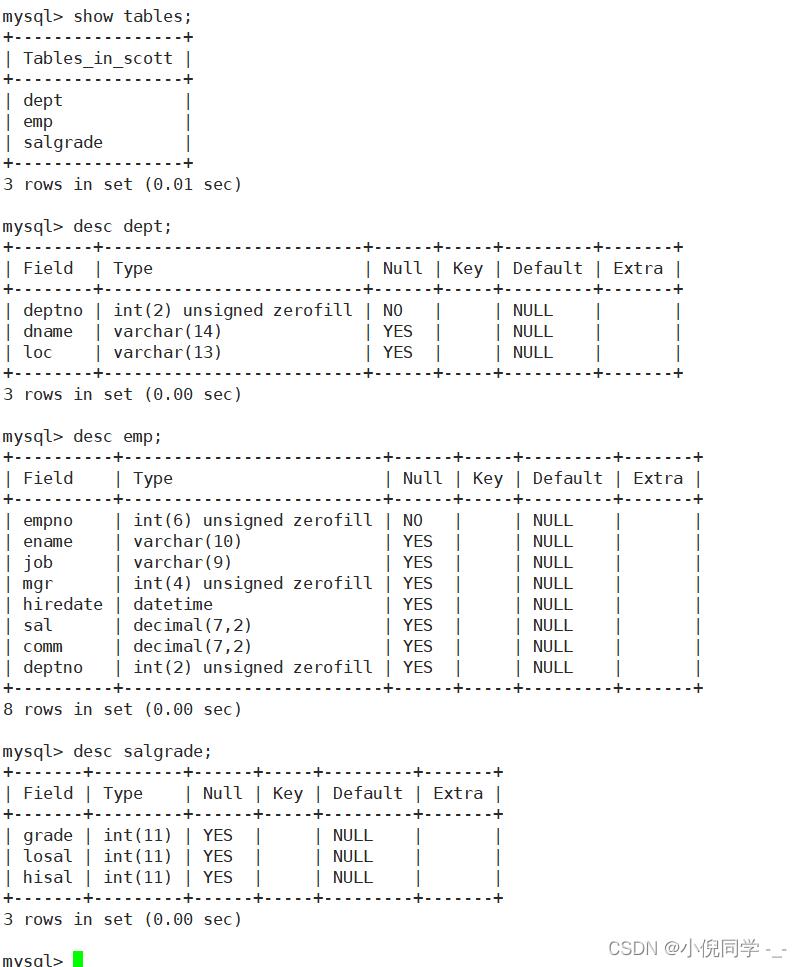
准备工作,创建一个雇员信息表
EMP员工表 DEPT部门表 SALGRADE工资等级表
云服务器中将外部资源传送值MySQL ,在MySQL中,使用 source + 资源名路径 指令。
显示每个部门的平均工资和最高工资
显示每个部门的每种岗位的平均工资和最低工资
显示平均工资低于2000的部门和它的平均工资
这里用的是having,那么它和where有何区别呢?
having 只能和 group by 搭配,是在分完组,做完数据统计之后,进行条件筛选。 where 和 having 起效果的时间是不一样的 where 是数据从原始表中筛选的时候起效果 having 是把数据全部取出,然后分组完成,甚至聚合统计之后,在对中间数据做筛选 where 和 having 可以同时被使用
以上是关于把字符串的增删查改,插入以及删除各种操作封装为一个用c代码写的库,代码怎么写,我写不来求教的主要内容,如果未能解决你的问题,请参考以下文章
数据结构之单链表的增删查改等操作画图详解
二叉搜索树的思想,以及增删查改的实现
MySQL 表的增删查改
初识链表(无头单向非循环链表的增删查改)
顺序表的基本操作——增删查改
SQL Server之 ADO增删查改 登录demo 带参数的sql语句 插入自动返回行号