深度学习提高模型准确率方法
Posted EDG viper
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深度学习提高模型准确率方法相关的知识,希望对你有一定的参考价值。
这里写目录标题
深度学习
我们已经收集好了一个数据集,建立了一个神经网络,并训练了模型,在测试和验证阶段最后得到的准确率不高不到90%。或者没有达到业务的期望(需要100%)。
下面列举一些提高模型性能指标的策略或技巧,来提高模型的准确率。

数据
使用更多数据
最简单的方法就是增加数据集,模型准确率不高,也可以理解为你模型不泛化,只是针对训练集内容来进行预测的,添加更多数据集,使数据更多样性,同时增加一些负样本。
至于数据增强,得了解自己做什么项目,比较简单的resize 之类的就是通用的,rotation肯定不适用于人,人不可能倒着对吧,还有小物件肯定就没必要random crop了,都crop没了,反正数据增强其实还是尽可能的增多接近现实的数据,还有一些color颜色变化,如果因为颜色修改,会使物件类型发生变化的都需要注意一下。具体可以看下图,根据自己的情况,选择合适的增强算子

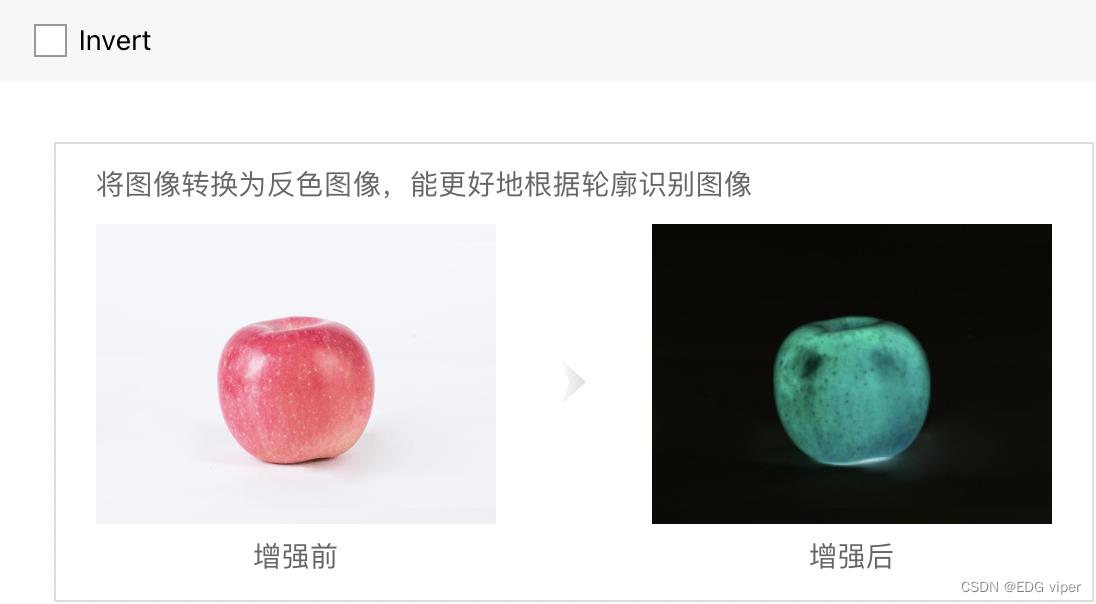






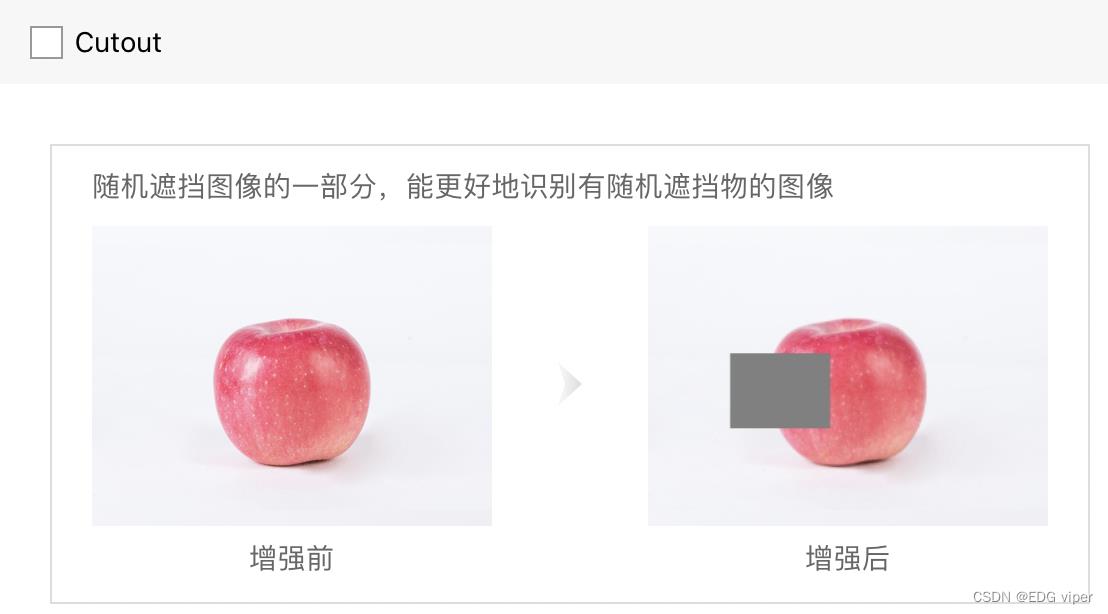
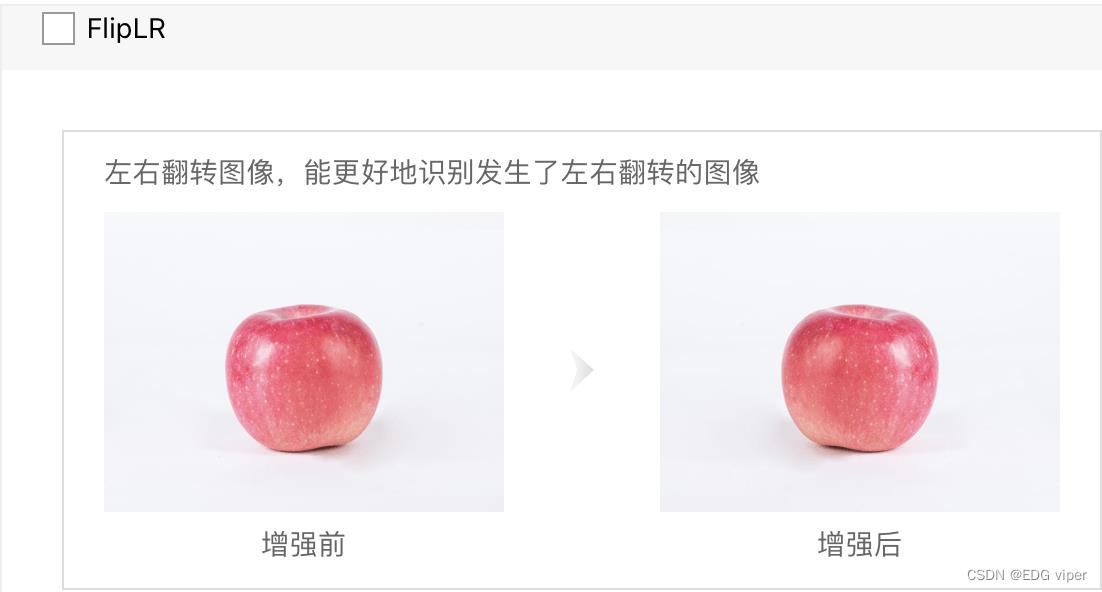
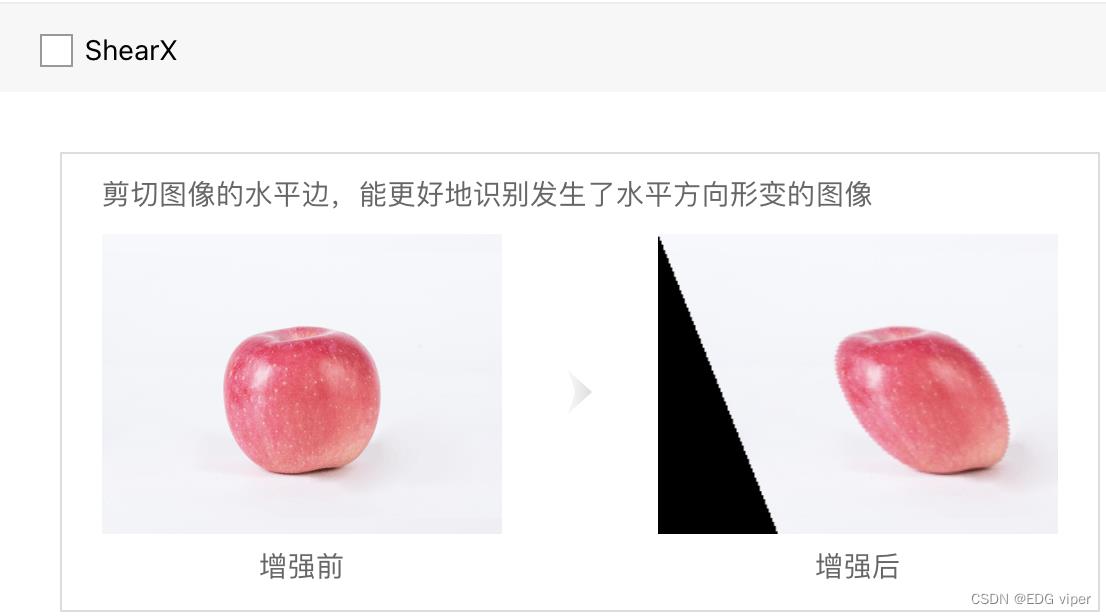




为了进行对比实验,观测不同数据增强方法的性能,实验 1 只进行图像切割,实验 2 只进行图像翻转,实验 3 只进行图像白化,实验 4 同时进行这三种数据增强方法,同样训练 5000 轮,观察到 loss 变化曲线、训练集准确率变化曲线和验证集准确率变化曲线对比如下图。

更改图像大小
当您对图像进行预处理以进行训练和评估时,需要做很多关于图像大小的实验。
如果您选择的图像尺寸太小,您的模型将无法识别有助于图像识别的显著特征。图像中的物件因为分辨率太低,都看模糊了
相反,如果您的图像太大,则会增加计算机所需的计算资源,并且/或者您的模型可能不够复杂,无法处理它们。
常见的图像大小包括64x64、128x128、28x28 (MNIST)和224x224 (vgg -16)。
请记住,大多数预处理算法不考虑图像的高宽比,因此较小尺寸的图像可能会在某个轴上收缩。
假如我们的模型是用小分辨率去训练的,用一个大分辨率的图像预测,图像会转化成小分辨率,这时候图像中很多的像素就减少,难免有些重要的内容去掉了。
减少颜色通道
颜色通道反映图像数组的维数。大多数彩色(RGB)图像由三个彩色通道组成,而灰度图像只有一个通道。
颜色通道越复杂,数据集就越复杂,训练模型所需的时间也就越长。
如果颜色在你的模型中不是那么重要的因素,你可以继续将你的彩色图像转换为灰度。
你甚至可以考虑其他颜色空间,比如HSV和Lab。
算法
模型改进
- 权重衰减(weight decay):对于目标函数加入正则化项,限制权重参数的个数,这是一种防止过拟合的方法,这个方法其实就是机器学习中的 l2 正则化方法,只不过在神经网络中旧瓶装新酒改名为 weight decay。
- dropout:在每次训练的时候,让某些的特征检测器停过工作,即让神经元以一定的概率不被激活,这样可以防止过拟合,提高泛化能力。
- 批正则化(batch normalization):batch normalization对神经网络的每一层的输入数据都进行正则化处理,这样有利于让数据的分布更加均匀,不会出现所有数据都会导致神经元的激活,或者所有数据都不会导致神经元的激活,这是一种数据标准化方法,能够提升模型的拟合能力
- LRN:LRN 层模仿生物神经系统的侧抑制机制,对局部神经元的活动创建竞争机制,使得响应比较大的值相对更大,提高模型泛化能力。
增加训练轮次
epoch基本上就是你将整个数据集通过神经网络传递的次数。以+25、+100的间隔逐步训练您的模型。
只有当您的数据集中有很多数据时,才有必要增加epoch。然而,你的模型最终将到达一个点,即增加的epoch将不能提高精度。
此时,您应该考虑调整模型的学习速度。这个小超参数决定了你的模型是达到全局最小值(神经网络的最终目标)还是陷入局部最小值。
迁移学习
迁移学习包括使用预先训练过的模型,如YOLO和ResNet,作为大多数计算机视觉和自然语言处理任务的起点。
预训练的模型是最先进的深度学习模型,它们在数百万个样本上接受训练,通常需要数月时间。这些模型在检测不同图像的细微差别方面有着惊人的巨大能力。
这些模型可以用作您的模型的基础。大多数模型都很好,所以您不需要添加卷积和池化
添加更多层
向模型中添加更多层可以增强它更深入地学习数据集特性的能力,因此它将能够识别出作为人类可能没有注意到的细微差异。
这个技巧图解决的任务的性质。
对于复杂的任务,比如区分猫和狗的品种,添加更多的层次是有意义的,因为您的模型将能够学习区分狮子狗和西施犬的微妙特征。
对于简单的任务,比如对猫和狗进行分类,一个只有很少层的简单模型就可以了。
或者最好的方法增加残差网络,残差网络能很好的解决了梯度衰减的问题,使得深度神经网络能够正常 work。由于网络层数加深,误差反传的过程中会使梯度不断地衰减,而通过跨层的直连边,可以使误差在反传的过程中减少衰减,使得深层次的网络可以成功训练
调整超参数
上面的技巧为你提供了一个优化模型的基础。要真正地调整模型,您需要考虑调整模型中涉及的各种超参数和函数,如学习率(如上所述)、激活函数、损失函数、甚至批大小等都是非常重要的需要调整的参数。
深层网络或者不适合的损失函数,不合适的学习率,可能会导致梯度消失、梯度爆炸。
预测模型不能只看准确率而要结合业务问题选择合适的评估指标
下面看一个列子
某企业希望销售 50 件产品,该企业建立了两个模型来选择待推销客户,混淆矩阵如下图,应该选择哪个模型?
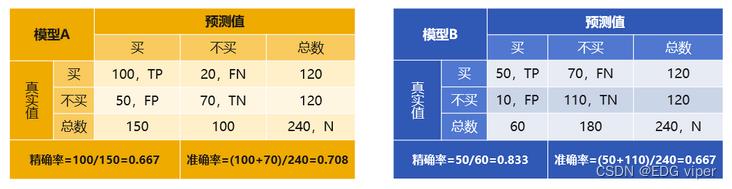
只考虑准确率,似乎应当选择A 模型,但这时候我们需要对75(=50/0.667,预测购买者中有 66.7% 的实际会购买,即精确率)个客户推销才可能卖出 50 件商品;而选择模型 B,则只要对60(=50/0.833)个客户推销就可能卖出 50 件商品了,推销成本反而降低了。在这个场景中,我们只关心能被推销成功的那些客户,而不能成功推销且被正确预测为不能成功推销的,虽然有助于提高模型的准确率,对我们却没什么意义。因此,这里用精确率来评估模型的好坏会更加合适
做项目,给出准确率,你的准确率是指测试到当前数据集的准确率,并不能代表其他数据集也是这个准确率
总结
- 嫌麻烦的:自己做的项目有现成的,就迁移学习 自己数据集单一的,就从数据集入手
- 模型过拟合:就改进模型的超参数,或者正则化,权重衰减,Dropout
- 模型欠拟合:就增加复杂模型,增加epoch
- 模型训练时间过长:批次处理标准化
以上是关于深度学习提高模型准确率方法的主要内容,如果未能解决你的问题,请参考以下文章