网页数据爬取初探
Posted 猛龙过江ing
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了网页数据爬取初探相关的知识,希望对你有一定的参考价值。
满树和娇烂漫红,万枝丹彩灼春融。——(唐)吴融《桃花》
套用朱自清的话来开头吧!“盼望着,盼望着,东风来了,春天的脚步近了。一切都像刚睡醒的样子,欣欣然张开了眼”。时间不知不觉中已经来到了三月,春回大地,万物复苏。俗话说:一年之计在于春,所以还要努力加油呀!
一、我们要做什么
我先提前说好,由于我只是有点兴趣,所以就玩了一下,也没有仔细研究,所以会说的很浅显笼统。什么?你不在乎?没有关系?你就想看我的文章?那好吧,既然这样,那咱们就闲言少叙,正式开始吧!
最近有个需求就是从网页上爬取一些数据。我们选定采购网作为目标网站,设定一些搜索条件,获取符合条件的条目之后将它们的相关信息提取出来。
二、获取条目链接
首先,设定一些条件,在网页上搜索出我们想要的信息条目,结果如下图所示。
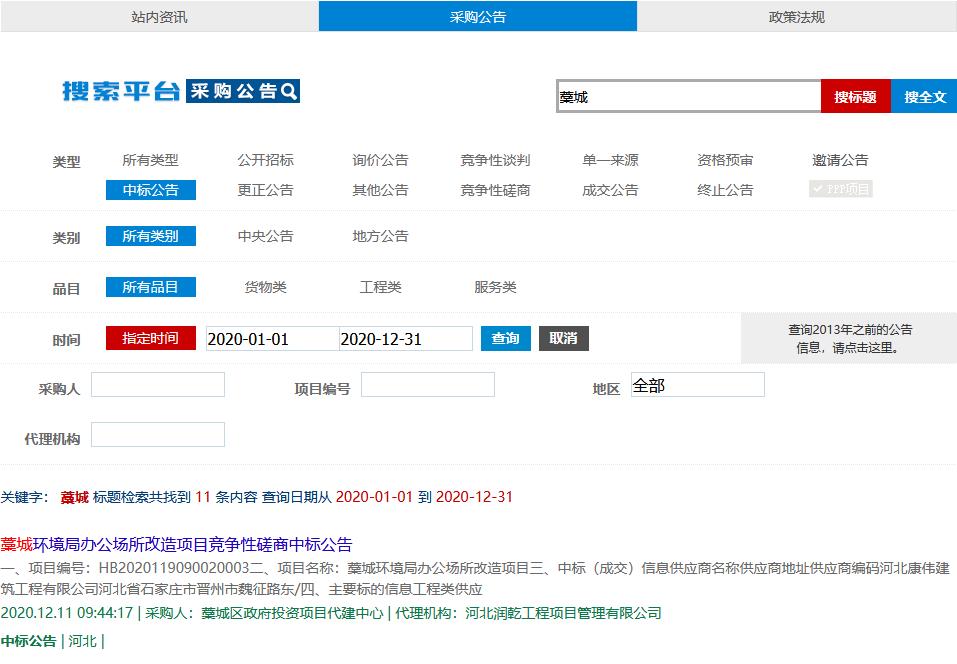
之后,我们需要做的就是获取这些搜索结果的链接,并且下载下来。我们采用Excel表格来进行存储,分成两列,第一列写入条目链接,第二列写入条目名称。话不多说,直接上代码,都在代码里。
from selenium import webdriver
from lxml import etree
import csv
def wash(node): # 处理网页名称
res = ''
for term in node.xpath("./node()[self::text() or self::span]"):
if str(term)[0] != '<':
res += term
elif term.tag == 'span':
res += term.text
res = res.strip()
return res
def main(n):
url = 'http://search.ccgp.gov.cn/bxsearch?searchtype=1&page_index=' + str(
n) + '&bidSort=0&buyerName=&projectId=&pinMu=2&bidType=5&dbselect=bidx&kw=%E8%A7%84%E5%88%92&start_time=2018%3A01%3A01&end_time=2018%3A12%3A31&timeType=6&displayZone=%E5%B1%B1%E4%B8%9C%E7%9C%81&zoneId=37+not+3702&pppStatus=&agentName=' # 这个地方就是拼凑URL地址,n代表页数
print(url)
options = webdriver.FirefoxOptions()
options.add_argument('-headless')
browser = webdriver.Firefox(firefox_options=options)
browser.get(url)
html_source = browser.page_source
browser.quit()
tree = etree.HTML(html_source)
html_data = tree.xpath('//*[@class="vT-srch-result-list-bid"]/li/a/@href') # URL地址
html_text = tree.xpath('//*[@class="vT-srch-result-list-bid"]/li/a') # 网页名称
rongqi_text = []
for k in html_text:
rongqi_text.append(wash(k))
h_n = 0
for i in html_data:
a = i, rongqi_text[h_n] # 把地址和网页名称都交给了a
h_n = h_n + 1
out = open(link_path, 'a', newline='')
csv_write = csv.writer(out, dialect='excel')
csv_write.writerow(a)
out.close()
link_path = '001.csv'
for a in range(1): # 有几页就写几
n = a + 1
main(n)
print("当前第" + str(n) + "页。")
其中,浏览器地址栏里的地址需要经过处理之后放到存放地址的那里,完成URL地址的拼凑。这样我们就获取到了满足条件的条目的链接和名称了。
三、获取网页的相关信息
这一步是非常关键的,说简单也简单,但是说难也非常的难,主要还是取决于网页的格式样式以及不同网页之间是否发生了变化。众所周知,计算机处理一些重复性的工作比较拿手,因此当网页的形式不断变化时,计算机很可能会束手无策。话不多说,还是直接上代码。
import csv
from lxml import etree
import pandas as pd
def csv_to_dataframe(csv_path): # csv转dataframe
data = pd.read_csv(csv_path, sep=',', engine='python', iterator=True, encoding='ANSI')
loop = True
chunkSize = 10000
chunks = []
while loop:
try:
chunk = data.get_chunk(chunkSize)
chunk = chunk.dropna(axis=1)
chunk = chunk.drop_duplicates()
chunks.append(chunk)
except StopIteration:
loop = False
df = pd.concat(chunks, ignore_index=True)
df = df.dropna(axis=1)
df = df.drop_duplicates()
return df
def get_message(csv_path, save_name):
df = csv_to_dataframe(csv_path)
df = df.drop_duplicates("name", keep='first').reset_index(drop=True)
num = len(df)
print(num)
rongqi = []
for k in range(num):
url = df.iloc[k, 0]
print(url)
page = page[1]
if page != '':
tree = etree.HTML(page)
bianhao1 = tree.xpath('/html/body/div[2]/div/div[2]/div/div[3]/div/p[4]/text()')
zhongbiaodanwei1 = None
name = tree.xpath('/html/body/div[2]/div/div[2]/div/div[2]/table/tbody/tr[2]/td[2]/text()')
caigoudanwei1 = tree.xpath('/html/body/div[2]/div/div[2]/div/div[2]/table/tbody/tr[4]/td[2]/text()')
xingzhengqu = tree.xpath('/html/body/div[2]/div/div[2]/div/div[2]/table/tbody/tr[5]/td[2]/text()')
shijian = tree.xpath('/html/body/div[2]/div/div[2]/div/div[2]/table/tbody/tr[5]/td[4]/text()')
zhuanjia1 = None
jine1 = tree.xpath('/html/body/div[2]/div/div[2]/div/div[2]/table/tbody/tr[7]/td[4]/text()')
dizhi1 = tree.xpath('/html/body/div[2]/div/div[2]/div/div[2]/table/tbody/tr[12]/td[2]/text()')
caigou_lianxifangshi1 = tree.xpath(
'/html/body/div[2]/div/div[2]/div/div[2]/table/tbody/tr[13]/td[2]/text()')
daili_name1 = tree.xpath('/html/body/div[2]/div/div[2]/div/div[2]/table/tbody/tr[14]/td[2]/text()')
daili_dizhi1 = tree.xpath('/html/body/div[2]/div/div[2]/div/div[2]/table/tbody/tr[15]/td[2]/text()')
daili_lianxifangshi1 = tree.xpath('/html/body/div[2]/div/div[2]/div/div[2]/table/tbody/tr[16]/td[2]/text()')
a = [bianhao1, zhongbiaodanwei1, name, caigoudanwei1, xingzhengqu, shijian, zhuanjia1, jine1, dizhi1,
caigou_lianxifangshi1, daili_name1, daili_dizhi1, daili_lianxifangshi1,
url] # 拼凑数据,依次为:项目编号、中标单位、项目名称、采购单位、行政区、时间、评审专家、项目金额、采购单位地址、采购单位联系方式、代理单位名称、代理单位地址、代理单位联系方式、URL地址
else:
a = ['网页格式有误', '网页格式有误', '网页格式有误', '网页格式有误', '网页格式有误', '网页格式有误',
'网页格式有误', '网页格式有误', '网页格式有误', '网页格式有误',
'网页格式有误', '网页格式有误', '网页格式有误', url]
print(a)
rongqi.append(a)
out = open(save_name, 'a', newline='', encoding='gbk')
try:
csv_write = csv.writer(out, dialect='excel')
csv_write.writerow(rongqi[0])
finally:
out.close()
rongqi = []
csv_path = 'link_js.csv' # 前文生成的存放URL地址的CSV文件
save_name = 'link_result.csv' # 生成爬取结果的CSV文件
get_message(csv_path, save_name)
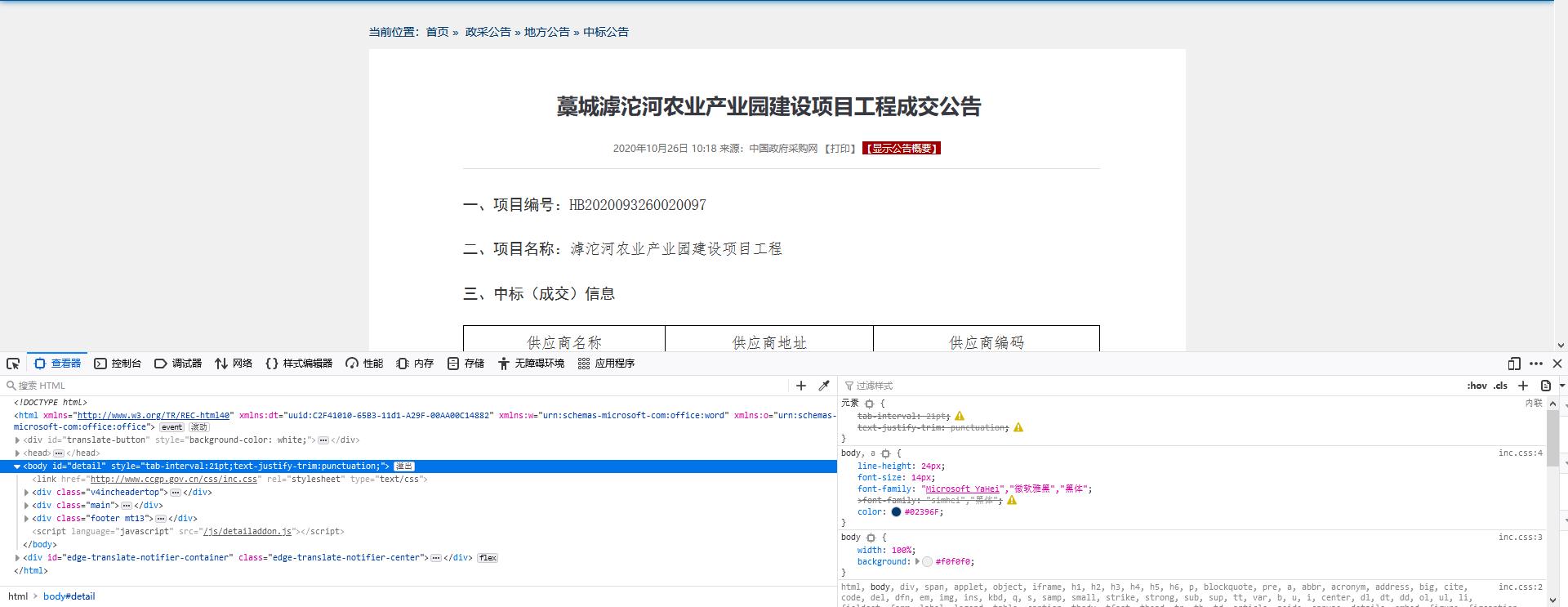
代码运行之前,需要在上一步生成的存放链接的CSV文件添加“name”作为首行。再说一下有效信息的提取吧,其他的也没有什么特别的,就提取网页,往CSV里写入数据之类的。网页信息的定位提取方式有多种,其中一种是使用XPath定位,也就是代码中使用的这种方法。打开目标网页,按下F12,就能够获得网页的HTML格式(姑且就这么叫吧),如下图所示。之后就手动数一数,看目标信息在什么位置,然后就可以拼写出来了。当然也可以使用搜索,找到信息之后右键-复制-XPath。还有一种获取地址的方法就是使用“查看器”左边的那个,点击网页中想提取的信息,然后右键-复制-XPath,这种方法没有上一个鲁棒。这两种方法只能保证当前网页是有效的,至于其他的网页,就只能听天由命了。另外还可以通过正则表达式什么的进行信息提取,我目前还没有研究过。
另外,搜索资料看到有人这么进行信息定位,感觉更好一些,不容易出现信息错乱,分享一下。
import requests
def get_detail_page(url):
try:
response = requests.get(url)
if response.status_code == 200:
html = response.content.decode('utf-8', 'ignore').replace(u'\\xa9', u'')
return html
except requests.ConnectionError:
return None
html = get_detail_page(url)
table_list = html.xpath('//div[@class="table"]//tr')
# print(table_list)
all_info =
for table in table_list:
if len(table.xpath('td[@class="title"]/text()')) > 0:
title = ''.join(table.xpath('td[@class="title"]/text()'))
value = ''.join(table.xpath('td[@colspan="3"]/text()'))
if (title.find('附件') == 0):
value = 'http://www.ccgp.gov.cn/oss/download?uuid=' + ''.join(table.xpath('td[@colspan="3"]/a/@id'))
# print(title+value)
if ('公告时间' in title):
title = '公告时间'
value = table.xpath('td[@width="168"]/text()')[1]
district_key = '行政区域'
district_value = (table.xpath('td[@width="168"]/text()'))[0]
all_info[district_key] = district_value
if '本项目招标公告日期中标日期' in title:
title = '本项目招标公告日期'
value = table.xpath('td[@width="168"]/text()')[0]
zhongbiaoriqi_key = '中标日期'
zhongbiaoriqi_value = table.xpath('td[@width="168"]/text()')[1]
all_info[zhongbiaoriqi_key] = zhongbiaoriqi_value
# print('中标日期'+zhongbiaoriqi_value)
if '本项目招标公告日期成交日期' in title:
title = '本项目招标公告日期'
value = table.xpath('td[@width="168"]/text()')[0]
zhongbiaoriqi_key = '中标日期'
zhongbiaoriqi_value = ''.join(table.xpath('td[@width="168"]/text()'))[11:]
# print('zhongbiaoriqi_value:'+zhongbiaoriqi_value)
all_info[zhongbiaoriqi_key] = zhongbiaoriqi_value
all_info[title] = value
all_info['插入时间'] = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')这样,网页信息爬取的任务就完成了。由于博主第一次接触这方面的东西,难免有疏漏之处,欢迎批评指正。
参考
以上是关于网页数据爬取初探的主要内容,如果未能解决你的问题,请参考以下文章
Python爬虫初探 - selenium+beautifulsoup4+chromedriver爬取需要登录的网页信息