python3爬虫初探之从爬取到保存
Posted 不秩稚童
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python3爬虫初探之从爬取到保存相关的知识,希望对你有一定的参考价值。
想一想,还是写个完整的代码,总结一下前面学的吧。
import requests import re # 获取网页源码 url = \'http://www.ivsky.com/tupian/xiaohuangren_t21343/\' data = requests.get(url).text #正则表达式三部曲 #<img src="http://img.ivsky.com/img/tupian/t/201411/01/xiaohuangren-009.jpg" width="135" height="135" alt="卑鄙的我小黄人图片"> regex = r\'<img src="(.*?.jpg)"\'#匹配网址 pa = re.compile(regex)#转为pattern对象 ma = re.findall(pa, data)#findall 方法找到所有的符合pa的对象,添加到一个列表中并返回 #print(ma)#图片网址列表 print(\'本次爬取共获取图片\'+str(len(ma))+\'张\')#列表长度,即找到图片个数 i = 0#这里的i, 只是为了给图片命名。。。 for imgurl in ma: i += 1 print(\'正在爬取\'+imgurl) imgdata = requests.get(imgurl).content with open(str(i)+\'.jpg\', \'wb\') as f: f.write(imgdata) print(\'爬取完毕!\')
放几张程序输出的图。

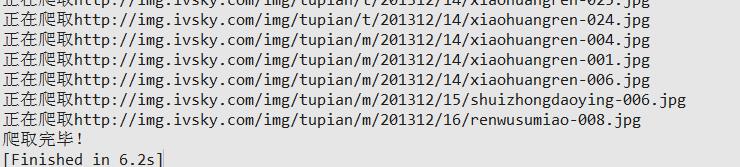
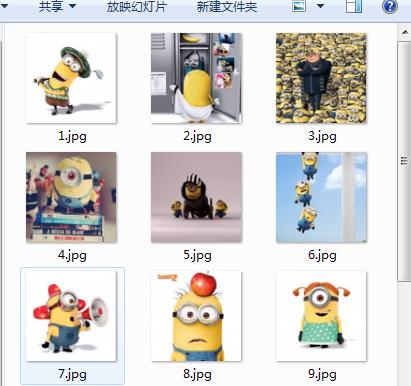
以上是关于python3爬虫初探之从爬取到保存的主要内容,如果未能解决你的问题,请参考以下文章