数据仓库-学习理解
Posted 21座的胖子
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据仓库-学习理解相关的知识,希望对你有一定的参考价值。
概要:数据仓库是一个过程而不是一个项目;是一个环境而不是一件产品。
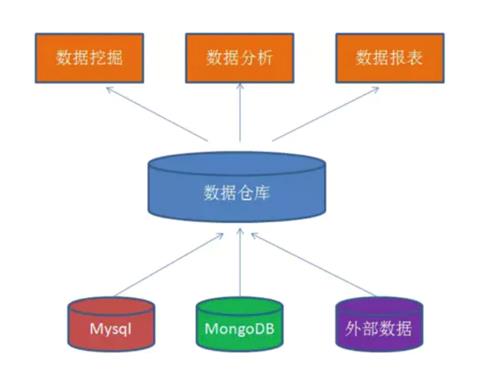
数据仓库将多个数据源的数据按照一定主题集成起来,经过抽取、清洗、转换。整合后的数据不允许随便修改,定期更新,这个过程叫做ETL:抽取(extract)、转换(transform)、加载(load)。
数据仓库大致流程
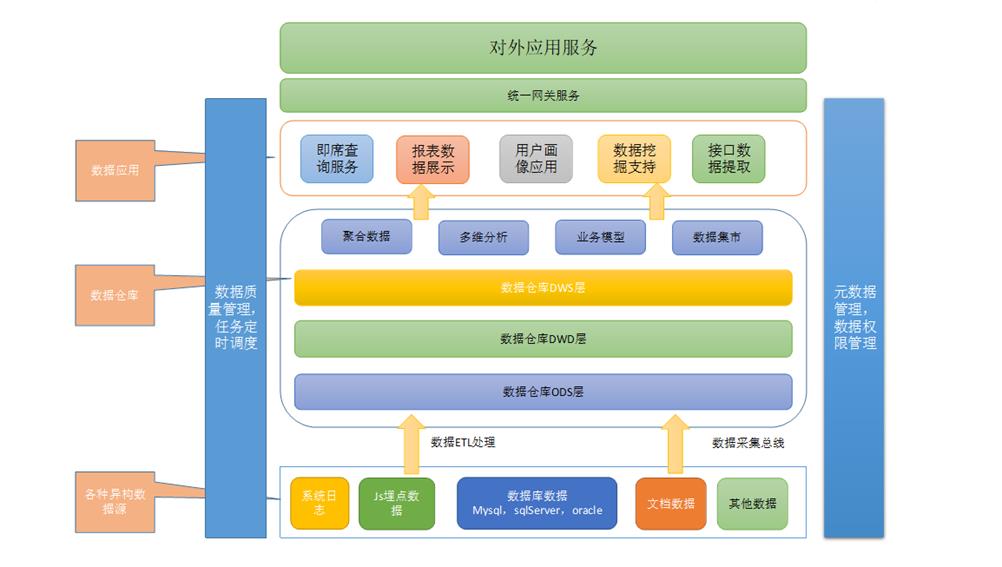
ODS层:外部数据源ETL到数仓里最原始的数据
DWD层:对ODS层中的表按一定主题进行划分和加工,内容还是明细数据
DWS层:对DWD层数据进行汇总
ADS层:数据应用层,分析报表等。
DM层:data mart,数据集市,为特有业务独立提取出数据,针对性强。
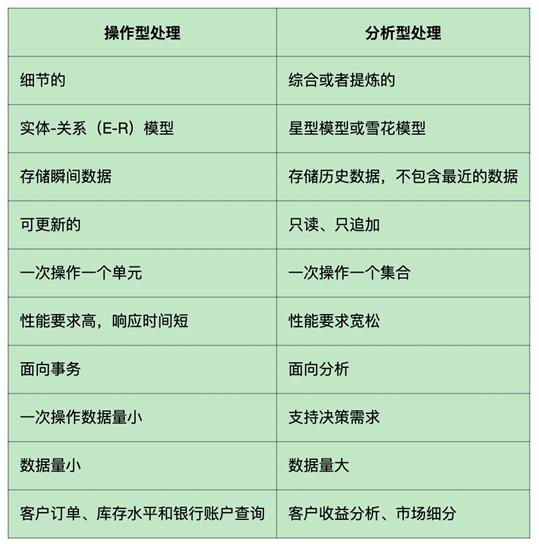
数据库与数据仓库的区别
数据库:操作型处理
数据仓库:分析型处理
hive
hadoop,分布式系统架构,其中一个组件HDFS(hadoop distributed file system)用于分布式高效处理数据。
hive是建立在hadoop上的数据仓库架构,提供一系列工具来进行数据ETL(提取转化加载),定义了hive sql语言,让不懂java的人也可以进行数据处理。
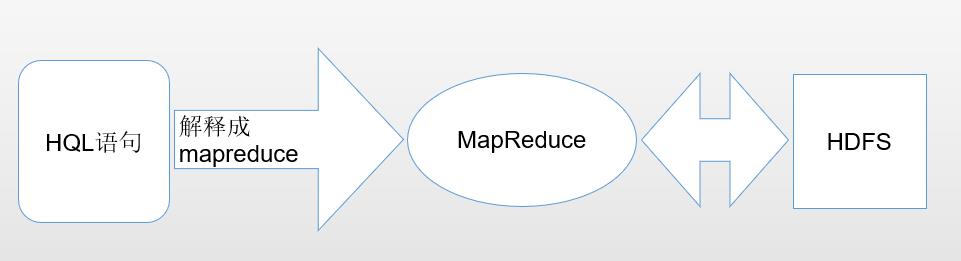
MapReduce
类比:map为老师,负责分配任务,reduce为学生,负责整理结果。
Map方法之后到Reduce方法之前的阶段叫做shuffle机制,Map方法之后,数据首先进入到分区方法,把数据标记好之后进行分区,然后把数据发送到环形缓冲区,默认大小为100M,环形缓冲区大小达到80%时,进行溢写,形成大量溢写文件,按照分区存储到磁盘,等待reduced端拉取。
看到网上几张图,比较通俗易懂:
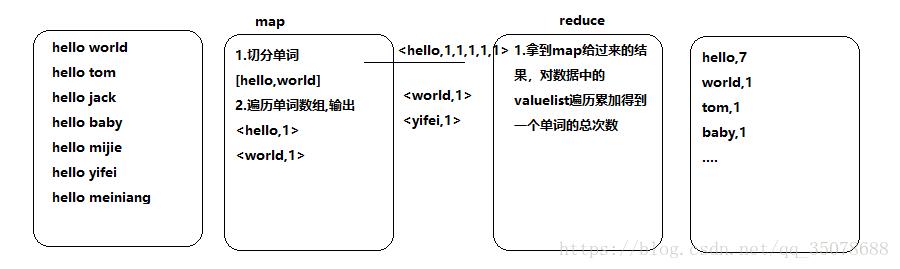
排序
1、order by
hive中的order by和sql中的用法一样,对全局数据进行排序,所有数据都会放到同一个reduce里进行处理,对于大量数据会消耗很长时间去运行,效率较低,不建议使用。
2、sort by
hive中的sort by在每个reduce端进行排序,保证局部有序
3、distribute by和sort by
sort by实现的是局部有序,但是需求是全局有序,在sort by之前加上distribute by可以实现全局有序,并且效率高于直接使用order by。比如以下语句:
select mid, money, name from store distribute by mid sort by mid asc, money asc
实现了order by mid,money的功能,但是效率要高很多
4、cluser by
当distribute by 和 sort by 的参数相同时,且排序为升序排序时可以使用cluser by代替,比如以下语句,功能是一致的:
select * from table1 cluster by id;
select * from table1 distribute by id sort by id;
执行顺序
SQL执行顺序
from→join→on→where→group by→having→select→distinct→order by→limit
from:打开哪个表
join:连接哪个表
on:连接字段
where:条件过滤
group by:分组
having:where不能和聚合函数一起用,having跟在where后面
select:要哪些字段
distinct:去重
order by:排序
limit:取结果
hive执行顺序
from→where→select→group by→having→select→order by→limit
hive的执行顺序本身是MapReduce的执行
Map阶段:
1、from:打开哪个表
2、where:条件过滤
3、select:要哪些字段
4、group by:分组
5、合并发给reduce
Reduce阶段
1、将Map发过来的文件分组
2、select:要哪些字段输出
3、排序输出
hive的优化
hive最大的问题是数据倾斜,一个特征是任务长时间维持在99%或者100%,任务监控页面中只有少量reduce任务未完成。
1、减少数据:条件前置,减少获取列
原语句:
select a.name,b.name
from table1 a
left join table2 b
on a.id = b.id
优化后:
select a.name,b.name
from table1 a
left join(select id,name from table2) b
on a.id = b.id
2、count(distinct)
count(distinct)是最常见的低效率SQL,原因有:
特殊值过多,处理此特殊值的reduce耗时,解决方案:在group by 之前增加distribute by,把相同key的数据分配到同一个reduce上进行处理,提高运行效率。
3、负载不均衡
hive.groupby.skewindata =true
当设定hive.groupby.skewindata为true时,生成的查询计划会有两个MapReduce任务。在第一个MapReduce 中,map的输出结果集合会随机分布到 reduce 中, 每个 reduce 做部分聚合操作,这样处理之后,相同的 Group By Key 有可能分发到不同的 reduce 中,从而达到负载均衡的目的。在第二个 MapReduce 任务再根据第一步中处理的数据按照Group By Key分布到reduce中,(这一步中相同的key在同一个reduce中),最终生成聚合操作结果。
以上是关于数据仓库-学习理解的主要内容,如果未能解决你的问题,请参考以下文章