从Hadoop框架来入门学习数据仓库概念
Posted Nborh
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了从Hadoop框架来入门学习数据仓库概念相关的知识,希望对你有一定的参考价值。
前言:
我了解数据仓库的时间很短, 所写的内容是一个初学者对数据仓库的理解, 所写的目的是以此作为自己梳理数据仓库概念的方法. 文中所用的图均来源于其他, 只是为了方便阅读的理解, 我也不太清楚怎么能把CSDN自动添加的本人水印去掉.
你可能想要了解的内容:
- 数据仓库和数据库解决的问题有什么不一样?
- 数据仓库架构的发展历史
- 从Hadoop框架的角度来理解数据仓库
- 从Hive来更深入理解: 数据仓库和数据库解决的问题有什么不一样?
数据仓库和数据库:
数据仓库和数据库这方面的术语很多, 对初学者来说也很混乱, 我首先认识到的是: 数据仓库和数据库不是同一个东西.
数据库和数据仓库都是解决方案, 我们关注它们的真正落地, 才能更轻松地理解这两个术语.
数据库的应用可以理解为OLTP(联机事务处理), 而数据仓库的应用可以理解为OLAP(联机分析处理). 换个角度来说, 数据库是为了查询数据而设计的, 数据仓库是为了分析数据而设计的.
比如说, 你在手机上去查自己银行卡的余额, 这就是查询数据, 要简单要快. 银行想分析你是不是新理财产品的潜在用户, 就是分析数据, 银行一般通过分析你的历史数据就能满足分析的要求, 对于数据及时更新的要求没有那么迫切.
分析数据的要求再高一点就涉及到实时性的问题, 比如人们想让空调根据现在的室内环境和室外天气自动分析运行, 数据及时更新的要求就很迫切了.
数据仓库概念的发展历史:

简单理解数据仓库就是: 原始的数据经过ETL的处理, 就来到了数据仓库. 数据仓库经过几层的处理(比如ODS层, DWD层, DWS层, ADS层), 就走出了数据仓库, 来到了需要对数据各种应用的步骤.
离线大数据仓库: 原始的数据通过离线的方式, 导入到数据仓库中. 就像我们之前说的, 银行想要拿用户的历史数据来看是不是新产品的潜在客户, 使用离线大数据就能够满足要求.
Lambda数据仓库可以理解为: 在离线大数据仓库的基础上, 增加了一个为实时数据设计的通道. 想要实现智能化空调根据室内环境和室外天气自动分析运行, 不仅需要历史数据进行训练, 还需要现在的实时数据才能进行预测.
Kappa数据仓库就是把离线数据和实时数据的两个通道, 设计为一个更好的通道.
目前涉及实时数据的架构对于企业来说成本很高, 如果没有业务的实际需要, 离线数据架构的成本优势是企业选择的很重要的因素.
流行的Hadoop框架:
让数据仓库真正落地的工具有很多很多, 不同的思路, 同一种思路的解决方案都远不止一种, 但是Hadoop的确很流行.
我在学习的时候, 第一个问题是: 框架怎么理解? 我觉得就是解决方案的意思. Hadoop框架解决的问题是: 不仅使得数据量可以较容易地变大, 还能保证高效的处理速度.
数据大量增长之后, 虽然计算机硬盘的容量可以扩大, 但是性能却跟不上容量的变化, 就需要把数据分布到多块硬盘, 简单地说就是老师不再一个人改试卷了, 把卷子分给若干个学生, 每个学生只需要改老师分配的那部分试卷, 改完之后大家统一交给老师.
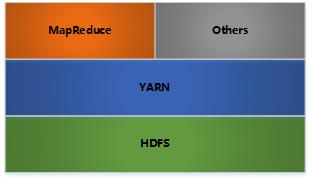
Hadoop框架核心是: HDFS为海量数据提供了存储, MapReduce为海量数据提供了计算框架(现在大家认为Spark计算框架已经赶超了它), YARN作为独立出来的资源管理框架.
Hadoop已经发展成了拥有20多个, 包括HBase实时分布数据库, Zookeeper分布式协作服务, Mahout数据挖掘库, 以及Hive数据仓库工具.
基于Hadoop的数据仓库工具Hive:
我的第一个问题是: Hive在Hadoop框架的哪个位置呢?
可以理解为: Hive是连接开发人员和MapReduce的中介, 开发人员用相对简单的类SQL语法输入之后, Hive将命令处理成优化后的MapReduce语句.
Hive利用HDFS存储数据, 利用MapReduce查询分析数据, 但是大大降低了开发人员的学习成本.
第二个问题是: Hive在数据仓库概念发展历史的哪个位置呢?
Hive是离线大数据仓库架构的落地工具, Spark和Flink主要是针对实时计算的工具.
第三个问题是: 我们用Hive数据仓库, 再来理解一下数据仓库和数据库的区别.
1. Hive数据仓库不支持对数据的改写和添加, 数据库可以用INSERT, UPDATE进行改写和添加. 原因在于数据仓库为的是读多写少, 数据在加载的时候就确定好了. 但是数据库的数据是经常需要修改的.
2. Hive数据仓库不对加载过程中的数据进行任何处理, 既不像数据库那样需要把数据以特定的格式和组织存储, 也不会像数据库那样添加索引方便查询. Hive引入MapReduce, 可以并行访问大量数据 , 但是相比于数据库的查询功能仍然有很高的延迟, 所以说数据仓库是为了分析数据而设计的, 数据库是为了查询数据而设计的.
3. Hive数据仓库可以支持很大规模的数据. 数据库能够支持的数据规模较小.
以上是关于从Hadoop框架来入门学习数据仓库概念的主要内容,如果未能解决你的问题,请参考以下文章