大数据笔记篇数据分层和数据仓库
Posted 开脚本的演员
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据笔记篇数据分层和数据仓库相关的知识,希望对你有一定的参考价值。
我是一个刚毕业就做大数据产品的,还是电商后台供应链这种,理论上我应该被流放去商城中台或者物流的,业务不懂,数据来源不懂,就直接开干,第一个月确实有点痛苦,好在未来都会痛苦,所以就没有什么好说的了。最近闲,呕心泣血地整理了一些大数据的知识,很适合大数据产品看,摘自大量技术博客和文章,被我大幅度改动。
先看一张数据分层图,这是很多大数据产品的一个基本数据架构。理解完这张图,基本就理解了大数据产品的底层数据逻辑。我打算之后的内容全部围绕它讲。
数据为什么要分层?
主要有下面几个原因:
1、清晰数据结构:每一个数据层都有它的作用域,这样我们在使用表的时候能更方便地定位和理解。
2、数据血缘追踪:简单来讲可以这样理解,我们最终给业务呈现的是一张能直接使用的业务表,但是它的来源有很多,如果有一张来源表出问题了,我们希望能够快速准确地定位到问题,并清楚它的危害范围。
3、减少重复开发:规范数据分层,开发一些通用的中间层数据,能够减少极大的重复计算。
4、把复杂问题简单化。将一个复杂的任务分解成多个步骤来完成,每一层只处理单一的步骤,比较简单和容易理解。而且便于维护数据的准确性,当数据出现问题之后,可以不用修复所有的数据,只需要从有问题的步骤开始修复。
5、屏蔽原始数据的异常。
6、屏蔽业务的影响,不必改一次业务就需要重新接入数据,源业务系统的业务规则发生变化会使整个数据清洗过程工作量巨大。
7、用空间换时间,通过大量的预处理来提升应用系统的用户体验(效率),因此数据仓库会存在大量冗余的数据。
数据如何去分层?
数据仓库标准上可以分为四层:ODS(临时存储层)、DW(数据仓库层)、MID(数据集市层)、APP(应用层)
架构师自己搭建不同的系统都会有不同的命名规则,除以上四层外,还会再去细分一些数据层次。例如:源数据层、数据接口层、数据加工层、数据访问层……不用纠结于命名。
源数据层:
数据的来源,一种是由前台的业务系统产生的数据,也就是业务系统会去记录和处理的数据,例如订单量、销售额。另外一种是系统运行产生的日志数据,这种一般需要去埋点,例如UV、PV等。
ODS层:
全称是Operational Data Store,操作数据存储。最接近数据源中数据的一层,数据源中的数据,经过抽取、洗净、传输,也就说传说中的ETL之后,装入本层。其实装入的过程中有些会更复杂,要进行诸如去噪、去重、提脏、业务提取、单位统一、砍字段、业务判别等多项工作。
作为临时存储层,是接口数据的临时存储区域,为后一步的数据处理做准备。一般来说ODS层的数据和源系统的数据是同构的,主要目的是简化后续数据加工处理的工作。从数据粒度上来说ODS层的数据粒度是最细的。ODS层的表通常包括两类,一个用于存储当前需要加载的数据,一个用于存储处理完后的历史数据。历史数据一般保存3-6个月后需要清除,以节省空间。但不同的项目要区别对待,如果源系统的数据量不大,可以保留更长的时间,甚至全量保存;
PDW层:
为数据仓库层,PDW层的数据应该是一致的、准确的、干净的数据,即对源系统数据进行了清洗(去除了杂质)后的数据。这一层的数据一般是遵循数据库第三范式的,其数据粒度通常和ODS的粒度相同。在PDW层会保存BI系统中所有的历史数据,例如保存10年的数据。
MID层:
为数据集市层,这层数据是面向主题来组织数据的,通常是星形或雪花结构的数据。从数据粒度来说,这层的数据是轻度汇总级的数据,已经不存在明细数据了。从数据的时间跨度来说,通常是DW层的一部分,主要的目的是为了满足用户分析的需求,而从分析的角度来说,用户通常只需要分析近几年(如近三年的数据)的即可。从数据的广度来说,仍然覆盖了所有业务数据。
APP层:
为应用层,这层数据是完全为了满足具体的分析需求而构建的数据,也是星形或雪花结构的数据。从数据粒度来说是高度汇总的数据。从数据的广度来说,则并不一定会覆盖所有业务数据,而是MID层数据的一个真子集,从某种意义上来说是MID层数据的一个重复。从极端情况来说,可以为每一张报表在APP层构建一个模型来支持,达到以空间换时间的目的数据仓库的标准分层只是一个建议性质的标准,实际实施时需要根据实际情况确定数据仓库的分层,不同类型的数据也可能采取不同的分层方法。
一般会存放在es、mysql等系统中供线上系统使用,也可能会存在Hive或者Druid中供数据分析和数据挖掘使用。比如我们经常说的报表数据,或者说那种大宽表,一般就放在这里。
数据之间的交互
源数据层-->ODS层
1、 业务库,这里经常会使用sqoop来抽取,比如我们每天定时抽取一次。在实时方面,可以考虑用canal监听mysql的binlog,实时接入即可。
-2、埋点日志,线上系统会打入各种日志,这些日志一般以文件的形式保存,我们可以选择用flume定时抽取,也可以用spark streaming或者storm来实时接入,当然,kafka也会是一个关键的角色。
ODS、PDW --> App层
这里面也主要分两种类型:
- 每日定时任务型:比如我们典型的日计算任务,每天凌晨算前一天的数据,早上起来看报表。 这种任务经常使用Hive、Spark或者生撸MR程序来计算,最终结果写入Hive、Hbase、Mysql、Es或者Redis中。【全量推数】
- 实时数据:这部分主要是各种实时的系统使用,比如我们的实时推荐、实时用户画像,一般我们会用Spark Streaming、Storm或者Flink来计算,最后会落入Es、Hbase或者Redis中。【增量推数】
ODS与DW的区别
1、数据的当前性
ODS包括的是当前或接近当前的数据,ODS反映的是当前业务条件的状态,ODS的设计与用户或业务的需要是有关联的,而DW则是更多的反映业务条件的历史数据。
2、数据的更新或加载
ODS中的数据是可以进行修改的,而DW中的数据一般是不进行更新的。ODS的更新是根据业务的需要进行操作的,而没有必要立即更新,因此它需要一种实时或近实时的更新机制。另外,DW中的数据是按照正常的或预先指定的时间进行数据的收集和加载的。
3、数据的汇总性
ODS主要是包括一些细节数据,但是由于性能的需要,可能还包括一些汇总数据,如果包括汇总数据,可能很难保证数据的当前性和准确性。ODS中的汇总数据生命周期比较短,所以可称作为动态汇总数据,如果细节数据经过了修改,则汇总数据同样需要修改。而DW中的数据可称为静态的汇总数据。
4、数据建模
ODS是站在记录层面访问的角度而设计的,DW或DM则是站在结果集层面访问的角度而设计的。ODS支持快速的数据更新,DW作为一个整体是面向查询的。
5、查询的事务
ODS中的事务操作比较多,可能一天中会不断的执行相同的事务,而DW中事务的到达是可以预测的。
6、用途
ODS用于每一天的操作型决策,是一种短期的;DW可以获取一种长期的合作广泛的决策。ODS是策略型的,DW是战略型的。
7、用户
ODS主要用于策略型的用户,比如保险公司每天与客户交流的客服;而DW主要用于战略型的用户,比如公司的高层管理人员。
8、数据量(主要区别之一)
ODS只是包括当前数据,而DW存储的是每一个主题的历史快照;
数据仓库和数据集市
广义的数据仓库(DW)其实就是指整个数据体系,包括以上四层数据层。
也就是说数仓是存数据的,企业的各种数据往里面塞,主要目的是为了有效分析数据,后续会基于它产出供分析挖掘的数据,或者数据应用需要的数据,如企业的分析性报告和各类报表,为企业的决策提供支持。
关系型数据库被分为两大类:
1. 操作型数据库:主要面向应用,用于业务支撑,支持对实际业务的处理,也可以叫业务型数据库。可以理解为通常意义上的数据库(后端开发同学口中的经常提到的就是这种)。
2. 分析型数据库:主要面向数据分析,侧重决策支持,作为公司的单独数据存储,负责利用历史数据对公司各主题域进行统计分析。
由于分析型数据库中的操作都是查询,因此也就不需要严格满足关系型数据库一些设计规范,这样的情况下再将它归为数据库不太合适,也容易不引起混淆,所以称之为数据仓库。
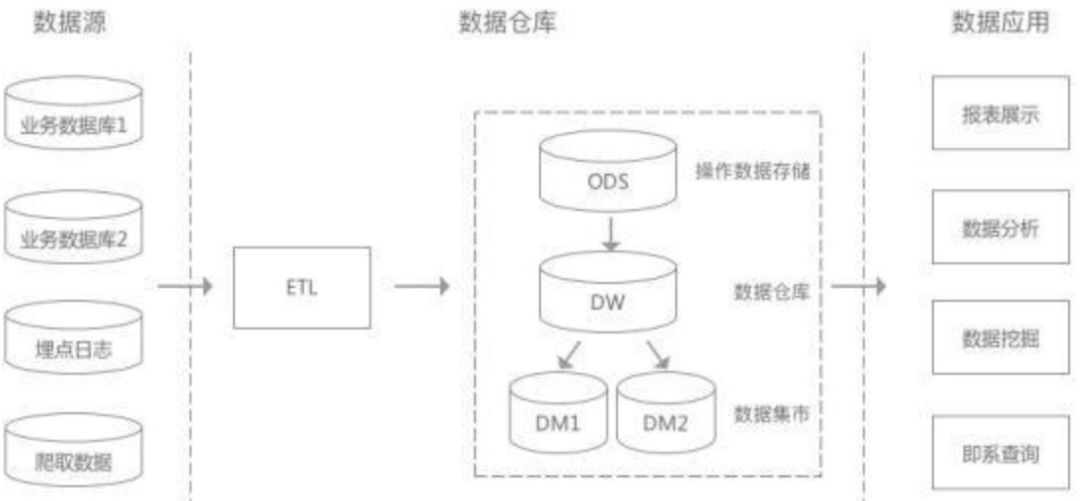
数据仓库的结构
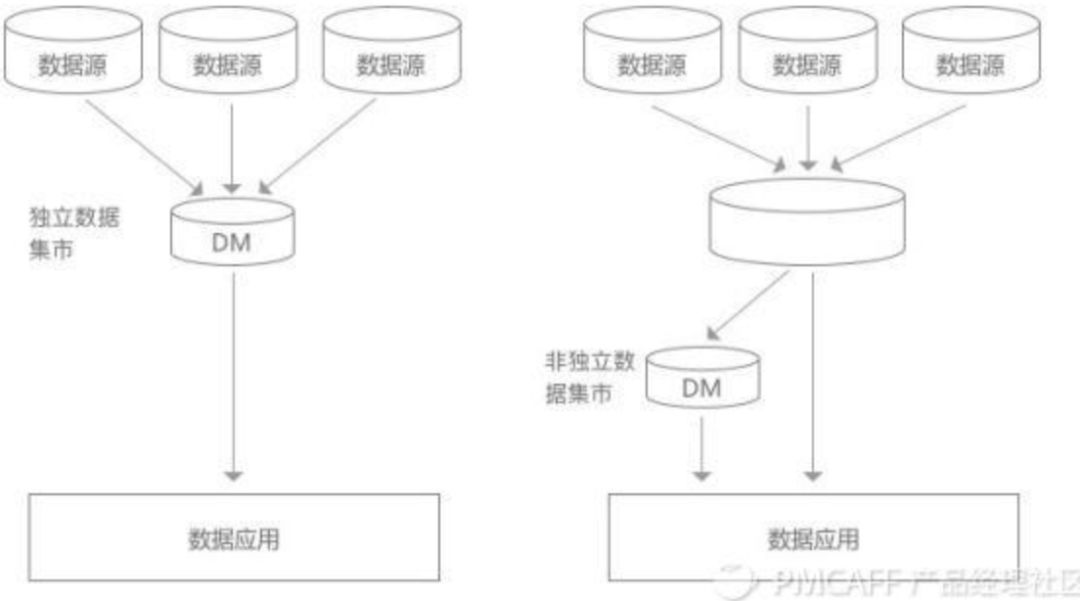
数据集市(DM)可以理解为是一种“小型数据仓库”,一般面向部门、单个主题或特定应用,且之间互不影响。可以分为以下两种:
独立数据集市:有自己的源数据库和ETL架构;
非独立数据集市:没有自己的源数据,它的数据来自数据仓库。当用户或者应用程序不需要/不必要/不允许访问整个数仓数据时,就可以直接访问数据集市,为用户提供一个数据仓库的“子集”。
下一篇讲ETL
以上是关于大数据笔记篇数据分层和数据仓库的主要内容,如果未能解决你的问题,请参考以下文章