在windows中实现Flume日志收集
Posted wpfphp
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了在windows中实现Flume日志收集相关的知识,希望对你有一定的参考价值。
一、flume的简介
任何一个系统在运行的时候都会产生大量的日志信息,我们需要对这些日志进行分析,在分析日志之前,我们需要将分散在生产系统中的日志收集起来。Flume就是这样的日志采集系统。
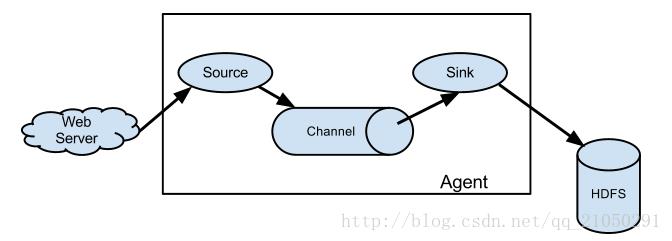
1.主要有三个组件:
Source:消费web系统这样的外部数据源中的数据(一般就是web系统产生的日志),外部数据源会向flume发送某种能被flume识别的格式的事件,有以下几种类型:avro 、exec、jms、spooling directory source、kafka、netcat等
Channel:当flume source从外部source读取到数据的时候,flume会将数据先存放在一个或多个channel中,这些数据将会一直被存放在channel中直到它被sink消费了为止,channel的主要类型有:memory、jdbc、kafka、file等
Sink:消费channel中的数据,然后将其存放进外部持久化的文件系统中,Sink的类型主要有HDFS、Hive、Avro、File Roll、kafka、HBase、ElasticSearch。
2.Agent的多级相连:
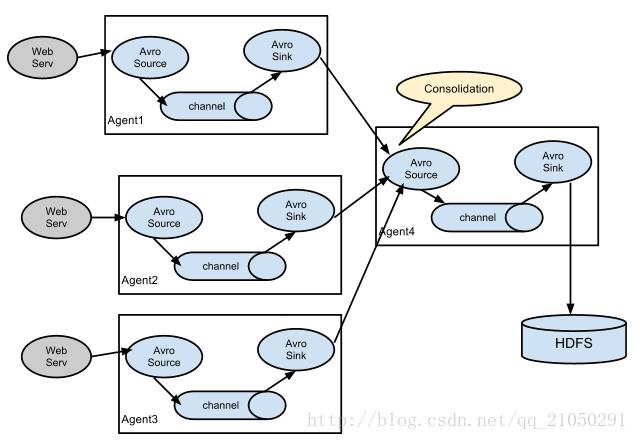
有些情况下,可能会有很多的服务器产生大量的日志文件,此时我们需要先准备一些第一层级的一些flume收集系统,这些flume日志收集系统需要有一个类型为avro的sink,这个sink采集到数据后,会将数据发送出去,具体发送到哪,需要在配置文件里面进行配置,然后再下一层极的flume收集系统中,采用avro类型的source,收集上一级发送过来的日志信息,然后再在这一层集中将数据沉入到hdfs文件系统中。
二、windows环境搭建
1. 下载安装
准备flume的安装包,请在官网进行下载:http://flume.apache.org/download.html
下载文件tail.exe,下载地址http://files.cnblogs.com/hantianwei/tail.zip
下载后解压,把tail.exe 复制到 目录:C:\\Windows\\System32 下
2.测试
测试flume
1.解压下载后的文件,进入conf目录,复制flume-conf.properties文件,并修改文件名称为:example.conf,编写内容如下:
| # 指定Agent的组件名称 a1.sources = r1 a1.sinks = k1 a1.channels = c1
# 指定Flume source(要监听的路径) a1.sources.r1.type = netcat a1.sources.r1.bind = localhost a1.sources.r1.port = 44444
# 指定Flume sink a1.sinks.k1.type = logger
# 指定Flume channel a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100
# 绑定source和sink到channel上 a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1 |
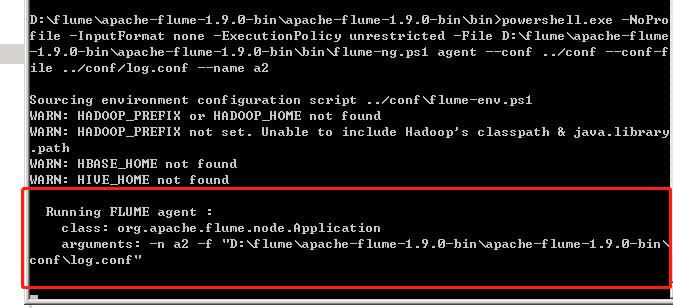
2. 使用cmd命令进入flume的bin目录,在命令行输入如下命令启动flume:
| flume-ng.cmd agent -conf conf -conf-file ../conf/example.conf --name a1 |
成功如下:
3.重新打开一个cmd窗口输入命令:
| telnet localhost 44444 |
然后进入了一个可编辑输入的窗口,我们在窗口输入“nihao”,然后在 flume 启动的窗口可以看见打印的信息。
测试通过,flume安装成功!!!
测试tail.exe
打开一个cmd窗口:
效果和liunx中的扫描文件尾命令一样
tail -f
三、搭建多个agent采集tomcat日志
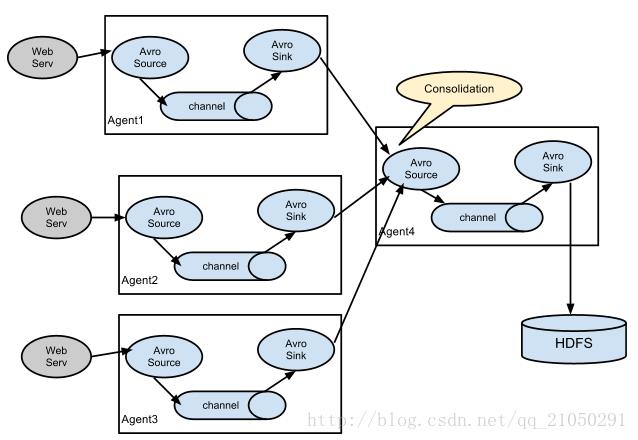
1.实现与准备:
实现:采集十台tomcat的日志文件
准备:在十台web服务器中搭建flume环境做第一层日志采集(服务器集群),一台最后收集的服务器中搭建flume环境做第二层采集(主服务器)。
3. Windows下Tomcat修改配置:
在服务器集群的十台web服务器中
1. 修改startup.bat文件内容把文件中的倒数第二行中的
| call "%EXECUTABLE%" start %CMD_LINE_ARGS% 改为: call "%EXECUTABLE%" run %CMD_LINE_ARGS% |
2. 修改catalina.bat文件内容查找catalina.bat含有%ACTION%的4行内容(在文件末),在后面添加
| >> %CATALINA_HOME%\\logs\\catalina.txt |
这样就会在 tomcat下的logs文件中生成一个catalina.txt。 控制台中的内容就会输入到文件中了。
3.第一层tomcat日志采集
在10台web服务器集群的flume安装目录下的conf文件夹下创建tomcat_log.conf文件内容如下:
| # 指定Agent的组件名称 a1.sources = r1 a1.sinks = k1 a1.channels = c1
# 指定Flume source(要监听的路径) a1.sources.r1.type = exec #在windows中要执行的命令, D:/tomcat7/logs/catalina.txt 是要监控文件的绝对路径 a1.sources.r1.command=tail -f D:/tomcat7/logs/catalina.txt
#可以添加静态拦截器用作区分是哪一个agent发送的日志 #a1.sources.r1.interceptors = i1 #a1.sources.r1.interceptors.i1.type = static ## static拦截器的功能就是往采集到的数据的header中插入自己定## 义的key-value对,也可以不使用 #a1.sources.r1.interceptors.i1.key = type #a1.sources.r1.interceptors.i1.value = web1
# 指定Flume sink 将本机监控的日志源catalina.txt通过内存通道发送到第二层收集日志的web服务器 a1.sinks.k1.type = avro a1.sinks.k1.channel = c1 a1.sinks.k1.hostname = ip #(第二层收集日志的web服务器ip) a1.sinks.k1.port = 44444 #(第二层收集日志的web服务器的随机一个没有被使用的端口)
# 指定Flume channel a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100
# 绑定source和sink到channel上 a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1
|
4.第二层采集
在最后一台主web服务器的flume安装目录下的conf文件夹下创建tomcat_log.conf文件内容如下:
| # 指定Agent的组件名称 a2.sources = r1 a2.sinks = k1 a2.channels = c1
# 指定Flume source(监听第一层收集agent中发送的ip和端口) a2.sources.r1.type = avro a2.sources.r1.channels = c1 a2.sources.r1.bind = 0.0.0.0 本机ip(跟第一层sink中的ip一致,可以用0.0.0.0代替) a2.sources.r1.port = 44444 #添加时间拦截器,也可以不使用 #a1.sources.r1.interceptors = i1 #a1.sources.r1.interceptors.i1.type=#org.apache.flume.interceptor.TimestampInterceptor$Builder
|
#下边的sink配置二选其一
# 第一种file_roll指定Flume sink(接收来自通过44444端口发送过来的日志)
| a2.sinks.k1.type = file_roll a2.sinks.k1.sink.directory = D://log//sink 日志保存的位置 a2.sinks.k1.sink.rollInterval = 0 |
#第二种hdfs接收到日志之后上传到hdfs中(注意hdfs需要安装hadoop)
| a2.sinks.k1.type = hdfs a2.sinks.k1.hdfs.path=hdfs://localhost:9000/test/%Y%m%d/%H/%type#通过拦截器接收header中的key,也可以不用 #上传文件的前缀 a2.sinks.k1.hdfs.filePrefix = agent2- #上传文件的后缀 a2.sinks.k1.hdfs.fileSuffix = .log #写 sequence 文件的格式。包含:Text, Writable(默认) a2.sinks.k1.hdfs.writeFormat = TEXT #间隔多长将临时文件滚动成最终目标文件,单位:秒,如果设置成0,则表示不根据时间来滚动文件 a2.sinks.k1.hdfs.rollInterval = 0 #当临时文件达到多少(单位:bytes)时,滚动成目标文件,10240bytes=10KB a2.sinks.k1.hdfs.rollSize = 10240 #是否使用当地时间 a2.sinks.k1.hdfs.useLocalTimeStamp = true #当 events 数据达到该数量时候,将临时文件滚动成目标文件,如果设置成0,则表示不根据events数据来滚动文件 a2.sinks.k1.hdfs.rollCount = 0 #文件格式,包括:SequenceFile, DataStream,CompressedStre,当使用DataStream时候,文件不会被压缩,不需要设置hdfs.codeC;当使用CompressedStream时候,必须设置一个正确的hdfs.codeC值; a2.sinks.k1.hdfs.fileType = DataStream |
| # 指定Flume channel a2.channels.c1.type = memory a2.channels.c1.capacity = 1000 a2.channels.c1.transactionCapacity = 100
# 绑定source和sink到channel上 a2.sources.r1.channels = c1 a2.sinks.k1.channel = c1
|
5.上传到hdfs需要安装hadoop
1.下载JDK,并设置JAVA_HOME。(使用不带空格的路径,比如Program Files,将在后面的配置中报错!如果带有空格可以设置软链接在后边的配置中会用到)
2.下载hadoop。下载地址:http://hadoop.apache.org/releases.html
如果在当前页中没找到2.8.3版本,可以到所有版本的下载列表中去找:https://archive.apache.org/dist/hadoop/common/
这里下载使用的是2.8.3的二进制版本文件,解压到d:/hadoop-2.8.3

3.下载winutils。这个是别人编译好的hadoop的windows版本二进制文件,不需要我们自己进行编译。下载下来然后将hadoop-2.8.3进行bin目录!覆盖!即可。
下载地址:https://github.com/steveloughran/winutils
4.在路径D:\\hadoop-2.8.3\\etc\\hadoop下修改文件
①core-site.xml(配置默认hdfs的访问端口,下边tmp目录可以手动创建)
| <configuration> <property> <name>fs.defaultFS</name> <value>hdfs://localhost:9000</value> </property> <property> <name>hadoop.tmp.dir</name> <value>D:\\hadoop\\tmp</value> </property> </configuration> |
②hdfs-site.xml(设置复制数为1,即不进行复制。namenode文件路径以及datanode数据路径。下边namenode,datanode两个地址目录可以手动创建,注意路径斜线的如果使用/可能会无效)
| <configuration> <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>D:\\hadoop\\data\\dfs\\namenode</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>D:\\hadoop\\data\\dfs\\datanode</value> </property> </configuration> |
③将mapred-site.xml.template 名称修改为 mapred-site.xml 后再修改内容(设置mr使用的框架,这里使用yarn)
| <configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration> |
④yarn-site.xml(这里yarn设置使用了mr混洗)
| <configuration> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name> <value>org.apache.hadoop.mapred.ShuffleHandler</value> </property></configuration>
|
⑤hadoop-env.cmd
设置JAVA_HOME的值(如果这里使用了带空格的Program Files路径将会报错!如果有空格可以设置软链接,下边用的就是软链接)
| set JAVA_HOME=D:\\tools\\java |
4. 进入D:\\hadoop-2.8.3\\bin目录,格式化hdfs在cmd中运行命令:
hdfs namenode -format
如果设置了hadoop的环境变量可以直接使用 :
hadoop namenode -format
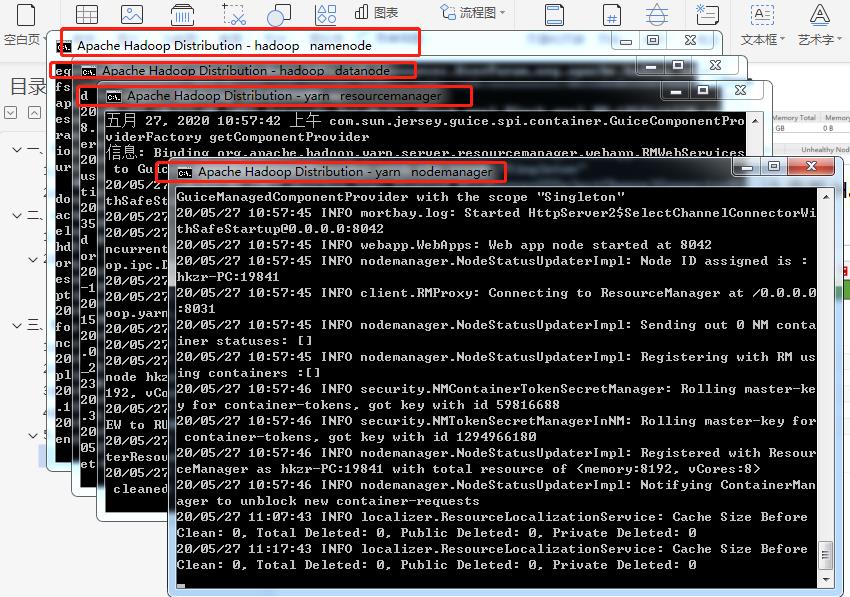
5.进入D:\\hadoop-2.8.3\\sbin目录
在cmd中运行命令start-all.cmd 出现下图中的四个cmd窗口
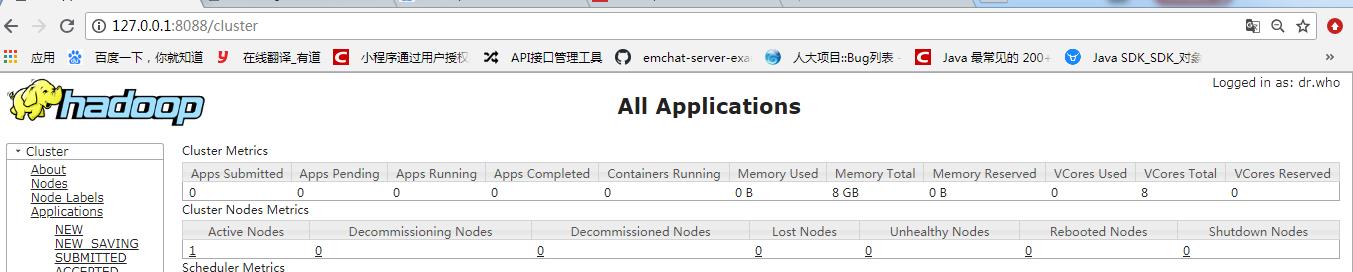
7. 在浏览器地址栏中输入:http://localhost:8088查看集群状态。
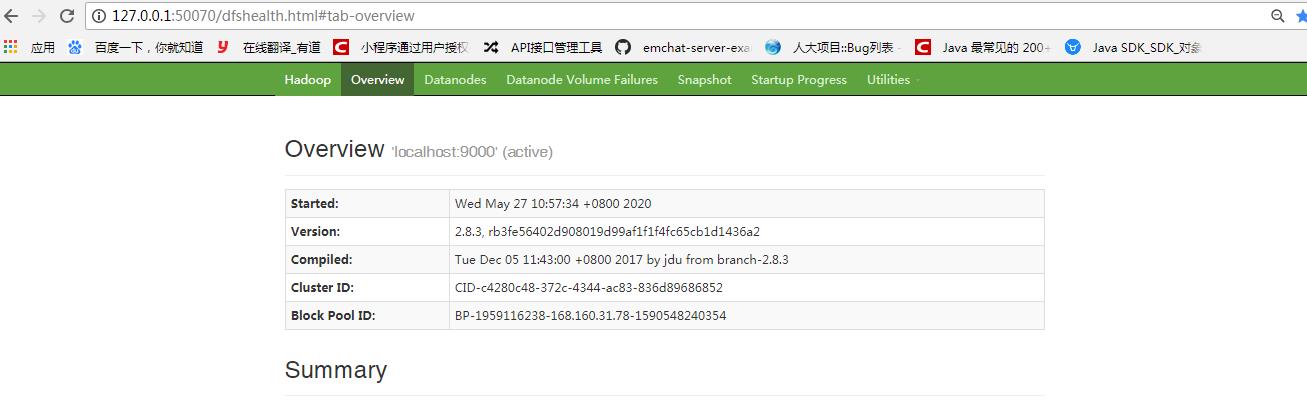
8.在浏览器地址栏中输入:http://localhost:50070查看Hadoop状态。
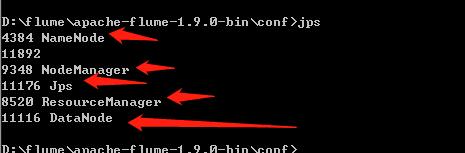
9.在cmd中使用jps查看状态
Hadoop启动成功。
四、Flume的启动及实现效果
1.首先启动主服务器的flume,进入flume安装目录下的bin目录(注意如果第二层采集中接收器使用的hdfs,则启动主服务器的flume之前先启动hadoop):
| flume-ng.cmd agent --conf ../conf --conf-file ../conf/tomcat_log.conf --name a2 |
2.启动十台web服务器集群的flume,进入flume安装目录下的bin目录(需要采集几台就启动几台):
| flume-ng.cmd agent --conf ../conf --conf-file ../conf/tomcat_log.conf --name a1 |
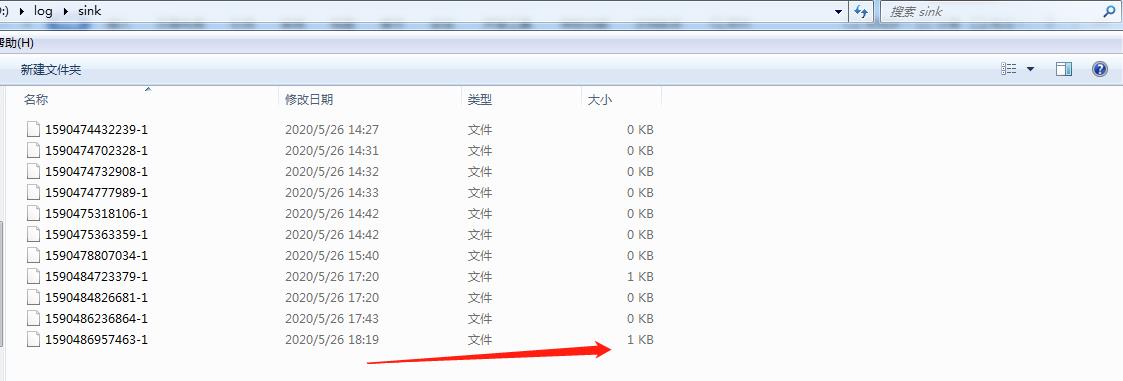
3.效果
使用第一种file_roll接收的效果
使用第二种hdfs接收的效果
以上是关于在windows中实现Flume日志收集的主要内容,如果未能解决你的问题,请参考以下文章