Flume日志收集系统架构详解
Posted 大数据和云计算技术
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Flume日志收集系统架构详解相关的知识,希望对你有一定的参考价值。
任何一个生产系统在运行过程中都会产生大量的日志,日志往往隐藏了很多有价值的信息。在没有分析方法之前,这些日志存储一段时间后就会被清理。随着技术的发展和分析能力的提高,日志的价值被重新重视起来。在分析这些日志之前,需要将分散在各个生产系统中的日志收集起来。本节介绍广泛应用的Flume日志收集系统。
Flume是Cloudera公司的一款高性能、高可用的分布式日志收集系统,现在已经是Apache的顶级项目。同Flume相似的日志收集系统还有Facebook Scribe、Apache Chuwka。
Flume 初始的发行版本目前被统称为Flume OG(Original Generation),属于Cloudera。但随着 Flume 功能的扩展,Flume OG 代码工程臃肿、核心组件设计不合理、核心配置不标准等缺点逐渐暴露出来,尤其是在 Flume OG 的最后一个发行版本0.94.0中,日志传输不稳定现象尤为严重。为了解决这些问题,2011 年 10 月 22日,Cloudera 完成了 Flume-728,对Flume进行了里程碑式的改动:重构核心组件、核心配置及代码架构,重构后的版本统称为 Flume NG(Next Generation);改动的另一原因是将 Flume 纳入Apache 旗下,Cloudera Flume 更名为 Apache Flume。
当节点出现故障时,日志能够被传送到其他节点上而不会丢失。Flume提供了三种级别的可靠性保障,从强到弱依次为:end-to-end(收到数据后,Agent首先将事件写到磁盘上,当数据传送成功后,再删除;如果数据发送失败,则重新发送)、Store on Failure(这也是Scribe采用的策略,当数据接收方崩溃时,将数据写到本地,待恢复后继续发送)、Best Effort(数据发送到接收方后,不会进行确认)。
Flume采用了三层架构,分别为Agent、Collector和Storage,每一层均可以水平扩展。其中,所有的Agent和Collector均由Master统一管理,这使得系统容易被监控和维护。并且Master允许有多个(使用ZooKeeper进行管理和负载均衡),这样就避免了单点故障问题。
当有多个Master时,Flume利用ZooKeeper和Gossip保证动态配置数据的一致性。用户可以在Master上查看各个数据源或者数据流执行情况,并且可以对各个数据源进行配置和动态加载。Flume提供了Web和Shell Script Command两种形式对数据流进行管理。
用户可以根据需要添加自己的Agent、Collector或Storage。此外,Flume自带了很多组件,包括各种Agent(如File、Syslog等)、Collector和Storage(如File、HDFS等)。
如图所示是Flume OG的架构。
Flume NG的架构如下图所示。Flume采用了分层架构,分别为Agent、Collector和Storage。其中,Agent和Collector均由Source和Sink两部分组成,Source是数据来源,Sink是数据去向。
Flume使用了两个组件:Master和Node。Node根据在Master Shell或Web中的动态配置,决定其是作为Agent还是作为Collector。
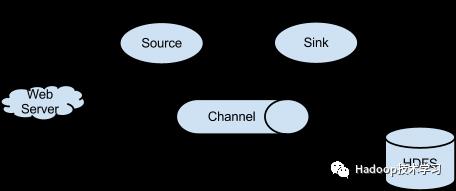
Agent的作用是将数据源的数据发送给Collector。Flume自带了很多直接可用的数据源(Source),如下。
text("filename"):将文件filename作为数据源,按行发送。
tail("filename"):探测filename新产生的数据,按行发送。
fsyslogTcp(5140):监听TCP的5140端口,并将接收到的数据发送。
tailDir("dirname"[,fileregex=".*"[,startFromEnd=false[,recurseDepth=0]]]):监听目录中的文件末尾,使用正则表达式选定需要监听的文件(不包含目录),recurseDepth为递归监听其下子目录的深度,同时提供了很多Sink,如console[("format")],直接将数据显示在console上。
text("txtfile"):将数据写到文件txtfile中。
dfs("dfsfile"):将数据写到HDFS上的dfsfile文件中。
syslogTcp("host",port):将数据通过TCP传递给host节点。
agentSink[("machine"[,port])]:等价于agentE2ESink,如果省略machine参数,则默认使用flume.collector.event.host与flume.collector.event.port作为默认collectro。
agentDFOSink[("machine"[,port])]:本地热备Agent。Agent发现Collector节点故障后,不断检查Collector的存活状态以便重新发送Event,在此期间产生的数据将缓存到本地磁盘中。
agentBESink[("machine"[,port])]:不负责的Agent。如果Collector出现故障,将不作任何处理,它发送的数据也将被直接丢弃。
agentE2EChain:指定多个Collector,以提高可用性。当向主Collector发送Event失效后,将转向第二个Collector发送;当所有的Collector都失效后,它还会再发送一遍。
Collector的作用是将多个Agent的数据汇总后,加载到Storage中。它的Source和Sink与Agent类似。
Source如下。
collectorSource[(port)]:Collector Source,监听端口汇聚数据。
autoCollectorSource:通过Master协调物理节点自动汇聚数据。
logicalSource:逻辑Source,由Master分配端口并监听rpcSink。
Sink如下。
collectorSink("fsdir","fsfileprefix",rollmillis):collectorSink,数据通过Collector汇聚之后发送到HDFS,fsdir是HDFS目录,fsfileprefix为文件前缀码。
customdfs("hdfspath"[,"format"]):自定义格式DFS。
Storage是存储系统,可以是一个普通File,也可以是HDFS、Hive、HBase、分布式存储等。
Master负责管理、协调Agent和Collector的配置信息,是Flume集群的控制器。
在Flume中,最重要的抽象是Data Flow(数据流)。Data Flow描述了数据从产生、传输、处理到最终写入目标的一条路径,如下图所示。
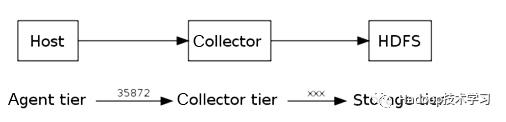
对于Agent数据流配置,就是从哪里得到数据,就把数据发送到哪个Collector。
对于Collector,就是接收Agent发送过来的数据,然后把数据发送到指定的目标机器上。
注:Flume框架对Hadoop和ZooKeeper的依赖只存在于JAR包上,并不要求Flume启动时必须将Hadoop和ZooKeeper服务同时启动。
本文所说的Flume基于1.4.0版本。
路径:apache-flume-1.4.0-src\flume-ng-clients。
操作最初的数据,把数据发送给Agent。在Client与Agent之间建立数据沟通的方式有两种。
第一种方式:创建一个iclient继承Flume已经存在的Source,如AvroSource或者SyslogTcpSource,但是必须保证所传输的数据Source可以理解。
第二种方式:写一个Flume Source通过IPC或者RPC协议直接与已经存在的应用通信,需要转换成Flume可以识别的事件。
Client SDK:是一个基于RPC协议的SDK库,可以通过RPC协议使应用与Flume直接建立连接。可以直接调用SDK的api函数而不用关注底层数据是如何交互的,提供append和appendBatch两个接口,具体的可以看看代码apache-flume-1.4.0-src\flume-ng-sdk\src\main\java\org\apache\ flume\api\RpcClient.java。
Avro是默认的RPC协议。NettyAvroRpcClient和ThriftRpcClient分别对RpcClient接口进行了实现,具体实现可以看下代码apache-flume-1.4.0-src\flume-ng-sdk\src\main\java\org\apache\flume\api\ NettyAvroRpcClient.java和apache-flume-1.4.0-src\flume-ng-sdk\src\main\java\org\apache\flume\api\ ThriftRpcClient.java。
下面给出一个使用SDK与Flume建立连接的样例如下,实际使用中可以参考实现:
import org.apache.flume.Event;
import org.apache.flume.EventDeliveryException;
import org.apache.flume.api.RpcClient;
import org.apache.flume.api.RpcClientFactory;
import org.apache.flume.event.EventBuilder;
import java.nio.charset.Charset;
public class MyApp {
public static void main(String[] args) {
MyRpcClientFacade client = new MyRpcClientFacade();
// Initialize client with the remote Flume agent's host and port
client.init("host.example.org",41414);
// Send 10 events to the remote Flume agent. That agent should be
// configured to listen with an AvroSource.
String sampleData = "Hello Flume!";
for (int i = 0; i < 10; i++) {
client.sendDataToFlume(sampleData);
}
client.cleanUp();
}
}
class MyRpcClientFacade {
private RpcClient client;
private String hostname;
private int port;
public void init(String hostname,int port) {
// Setup the RPC connection
this.hostname = hostname;
this.port = port;
this.client = RpcClientFactory.getDefaultInstance(hostname,port);
// Use the following method to create a thrift client (instead of the above line):
// this.client = RpcClientFactory.getThriftInstance(hostname,port);
}
public void sendDataToFlume(String data) {
// Create a Flume Event object that encapsulates the sample data
Event event = EventBuilder.withBody(data,Charset.forName("UTF-8"));
// Send the event
try {
client.append(event);
} catch (EventDeliveryException e) {
// clean up and recreate the client
client.close();
client = null;
client = RpcClientFactory.getDefaultInstance(hostname,port);
// Use the following method to create a thrift client (instead of the above line):
// this.client = RpcClientFactory.getThriftInstance(hostname,port);
}
}
public void cleanUp() {
// Close the RPC connection
client.close();
}
}
为了能够监听到关联端口,需要在配置文件中增加端口和Host配置信息(配置文件apache-flume- 1.4.0-src\conf\flume-conf.properties.template)。
client.type = default (for avro) or thrift (for thrift)
hosts = h1 # default client accepts only 1 host
# (additional hosts will be ignored)
hosts.h1 = host1.example.org:41414 # host and port must both be specified
# (neither has a default)
batch-size = 100 # Must be >=1 (default:100)
connect-timeout = 20000 # Must be >=1000 (default:20000)
request-timeout = 20000 # Must be >=1000 (default:20000)
除了以上两类实现外,FailoverRpcClient.java和LoadBalancingRpcClient.java也分别对RpcClient接口进行了实现。
该接口主要实现了主备切换,采用<host>:<port>的形式,一旦当前连接失败,就会自动寻找下一个连接。
该接口在有多个Host的时候起到负载均衡的作用。
Flume允许用户在自己的Application里内嵌一个Agent。这个内嵌的Agent是一个轻量级的Agent,不支持所有的Source Sink Channel。
Flume的三个主要组件——Source、Sink、Channel必须使用Transaction来进行消息收发。在Channel的类中会实现Transaction的接口,不管是Source还是Sink,只要连接上Channel,就必须先获取Transaction对象,如下图所示。
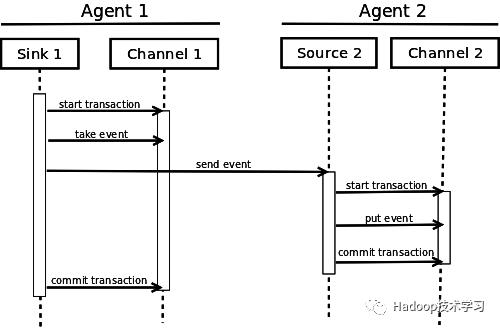
具体使用实例如下,可以供生成环境中参考:
Channel ch = new MemoryChannel();
Transaction txn = ch.getTransaction();
txn.begin();
try {
Event eventToStage = EventBuilder.withBody("Hello Flume!",Charset.forName ("UTF-8"));
ch.put(eventToStage);
txn.commit();
} catch (Throwable t) {
txn.rollback();
if (t instanceof Error) {
throw (Error)t;
}
} finally {
txn.close();
}
Sink的一个重要作用就是从Channel里获取事件,然后把事件发送给下一个Agent,或者把事件存储到另外的仓库内。一个Sink会关联一个Channel,这是配置在Flume的配置文件里的。SinkRunner.start()函数被调用后,会创建一个线程,该线程负责管理Sink的整个生命周期。Sink需要实现LifecycleAware接口的start()和stop()方法。
Sink.start():初始化Sink,设置Sink的状态,可以进行事件收发。
Sink.stop():进行必要的cleanup动作。
Sink.process():负责具体的事件操作。
Sink使用参考代码实例如下:
public class MySink extends AbstractSink implements Configurable {
private String myProp;
@Override
public void configure(Context context) {
String myProp = context.getString("myProp","defaultValue");
// Process the myProp value (e.g. validation)
// Store myProp for later retrieval by process() method
this.myProp = myProp;
}
@Override
public void start() {
// Initialize the connection to the external repository (e.g. HDFS) that
// this Sink will forward Events to ..
}
@Override
public void stop () {
// Disconnect from the external respository and do any
// additional cleanup (e.g. releasing resources or nulling-out
// field values) ..
}
@Override
public Status process() throws EventDeliveryException {
Status status = null;
// Start transaction
Channel ch = getChannel();
Transaction txn = ch.getTransaction();
txn.begin();
try {
// This try clause includes whatever Channel operations you want to do
Event event = ch.take();
// Send the Event to the external repository.
// storeSomeData(e);
txn.commit();
status = Status.READY;
} catch (Throwable t) {
txn.rollback();
// Log exception,handle individual exceptions as needed
status = Status.BACKOFF;
// re-throw all Errors
if (t instanceof Error) {
throw (Error)t;
}
} finally {
txn.close();
}
return status;
}
}
Source的作用是从Client端接收事件,然后把事件存储到Channel中。PollableSourceRunner.start()用于创建一个线程,管理PollableSource的生命周期。同样也需要实现start()和stop()两种方法。需要注意的是,还有一类Source,被称为EventDrivenSource。区别是EventDrivenSource有自己的回调函数用于捕捉事件,并不是每个线程都会驱动一个EventDrivenSource。
以下是一个PollableSource的例子:
public class MySource extends AbstractSource implements Configurable, PollableSource {
private String myProp;
@Override
public void configure(Context context) {
String myProp = context.getString("myProp","defaultValue");
// Process the myProp value (e.g. validation,convert to another type,...)
// Store myProp for later retrieval by process() method
this.myProp = myProp;
}
@Override
public void start() {
// Initialize the connection to the external client
}
@Override
public void stop () {
// Disconnect from external client and do any additional cleanup
// (e.g. releasing resources or nulling-out field values) ..
}
@Override
public Status process() throws EventDeliveryException {
Status status = null;
// Start transaction
Channel ch = getChannel();
Transaction txn = ch.getTransaction();
txn.begin();
try {
// This try clause includes whatever Channel operations you want to do
// Receive new data
Event e = getSomeData();
// Store the Event into this Source's associated Channel(s)
getChannelProcessor().processEvent(e)
txn.commit();
status = Status.READY;
} catch (Throwable t) {
txn.rollback();
// Log exception,handle individual exceptions as needed
status = Status.BACKOFF;
// re-throw all Errors
if (t instanceof Error) {
throw (Error)t;
}
} finally {
txn.close();
}
return status;
}
}
Flume的数据流由事件(Event)贯穿始终。事件是Flume的基本数据单位,它携带日志数据(字节数组形式)并且携带有头信息,这些Event由Agent外部的Source,比如上图中的Web Server生成。当Source捕获事件后会进行特定的格式化,然后Source会把事件推入(单个或多个)Channel中。你可以把Channel看作是一个缓冲区,它将保存事件直到Sink处理完该事件。Sink负责持久化日志或者把事件推向另一个Source。
很直白的设计,其中值得注意的是,Flume提供了大量内置的Source、Channel和Sink类型。不同类型的Source,Channel和Sink可以自由组合。多Agent串联,如下图所示。
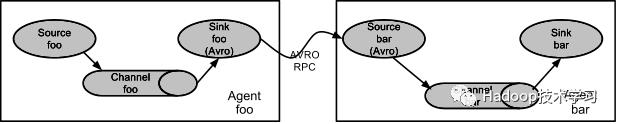
或者多Agent合并,如下图所示。
如果你以为Flume就这些能耐那就大错特错了。Flume支持用户建立多级流,也就是说,多个agent可以协同工作,并且支持Fan-in、Fan-out、Contextual Routing、Backup Routes。如下图所示。
参考http://www.aboutyun.com/thread-7848-1-1.html官网用户手册,http://flume.apache.org/FlumeUserGuide.html。
参考http://flume.apache.org/FlumeUserGuide.html。
以上是关于Flume日志收集系统架构详解的主要内容,如果未能解决你的问题,请参考以下文章