「大数据程序员开发工具」日志收集系统——Flume的功能与架构
Posted 广东互动学堂
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了「大数据程序员开发工具」日志收集系统——Flume的功能与架构相关的知识,希望对你有一定的参考价值。

Flume是一种分布式,可靠和可用的服务,用于高效收集,聚合和移动大量日志数据。它具有基于流数据流的简单灵活的架构。它具有可靠的可靠性机制和许多故障转移和恢复机制的强大和容错能力。它使用一个简单的可扩展数据模型,允许在线分析应用程序。
Flume架构
其设计的原理是基于将数据流,如日志数据从各种网站服务器上汇集起来存储到HDFS、HBase等集中存储器中。除了可以收集日志数据外,还可以收集其他数据。由于Flume的数据源是可定制的,因此可以用来传输大量的Event Data,Event Data可以是网络流量数据、社会媒体产生的数据、电子邮件以及其他数据源产生的数据。
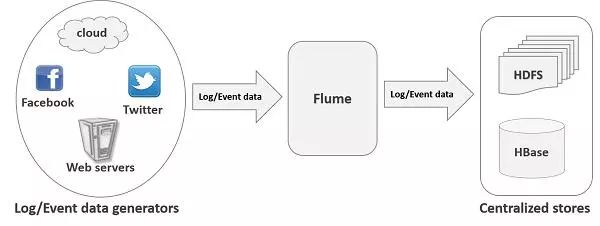
基本流程结构
Flume架构的核心概念

Flume核心概念
数据流模型(Data flow model)
Flume的数据流由Event贯穿始终。Event是Flume的基本数据流单位,Event由消息内容(a byte payload)和可选的消息头组成,消息头一系列字符串属性。Agent是Flume的最小的独立运行单位,由Source、Sink和Channel三大组件构成。
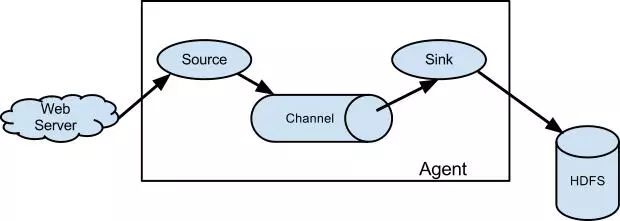
Flume组件
使用场景
多个Agent顺序连接(Multi-Agent Flow)
将多个Agent顺序连接起来,将最初的数据源经过收集、整理,存储到最终的存储系统中。一般情况下,应该控制这种顺序连接的Agent的数量,因为数据流经的路径变长了,如果不考虑failover的话,出现故障将影响整个Flow上的Agent收集服务。

顺序连接
多个Agent汇集到一个Agent(Consolidation)
这种情况应用的场景比较多,比如要收集上千个网站(网站集群)的日志,可以为这些网站配置多个Agent来收集日志,每个Agent收集一个或多个网站的日志,然后把这些Agent的数据汇集到统一的Agent中,最后由这个统一的Agent把数据持久化,如保存到HDFS。
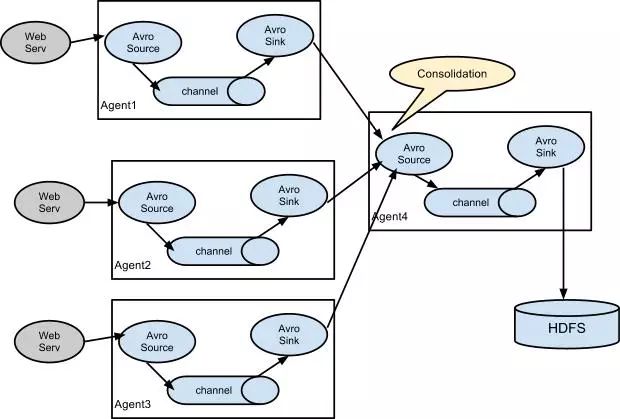
汇集
多路复用(Multiplexing Flow)
Flume支持通过复用把Event数据分发到多个Channel中,Sink再把不同Channel中的数据保存到不同的地方。Flume多路复用有两种方式,一种是复制(Replicating),一种是Multiplexing。复制就是把Event数据复制多份,然后给每个Channel都发送,每个Channel接收到的数据都是相同的。以下图为例,Event数据会被复制成3份,然后分发给3个Channel。Multiplexing方式就是对Event数据进行过滤,根据消息头属性把Event分发到不同的Channel中。

多路复用
Flume Source 详解

Flume内置Source
Avro Source
Avro Source监听Avro端口,接收外部Avro客户端发送过来的Avro Event数据。在多级流中,Avro Source可以和前一个Flume Agent的Avro Sink配对,建立分层收集拓扑。

Avro Source配置项
Thrift Source
Thrift Source监听Thrift端口,接收外部Thrift客户端发送过来的Thrift Event数据。在多级流中,Thrift Source可以和前一个Flume Agent的Thrift Sink配对,建立分层收集拓扑。Thrift Source支持基于Kerberos身份验证的安全模式。

Thrift Source配置项
Exec Source
Exec Source在启动时调用的Unix命令,该命令进程会持续地把标准日志数据输出到Exec Source,如果命令进程关闭,Exec Source也会关闭。Exec Source支持cat [named pipe]或者tail -F [file]命令。Exec Source最大的问题就是数据有可能丢失,因为当Channel接收Exec Source数据出错时或者抛出异常时,Exec Client并不能捕获到该错误。建议使用Spooling Directory Source代替。

Exec Source配置项
JMS Source
JMS Source从队列或者Topic中读取数据,目前只在ActiveMQ中测试。在使用JMS Source时,必须在Flume ClassPath中添加JMS JAR包。
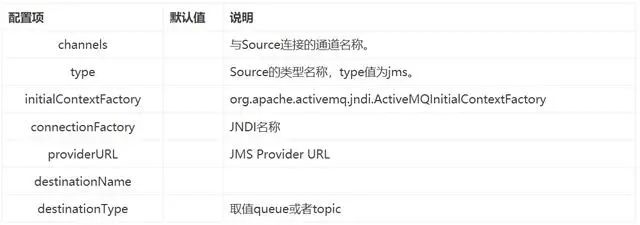
JMS Source配置项
Spooling Directory Source
Spooling Directory Source监听系统上的指定目录,当目录中有新的文件创建时,Spooling Directory Source会把新文件的内容读取并推送到Channel中,并且把已读取的文件重命名成指定格式或者把文件删除。由于数据是以文件的形式存放的系统中,Spooling Directory Source的可靠性非常高,即使是Flume Agent崩溃或者重启,数据也可以恢复。

Spooling Directory Source配置项
Kafka Source
Kafka Source从消息队列Kafka Topic中读取日志消息,Kafka Source相当于消息队列的Consumer。可以把多个Kafka Source配置到同一个分组里面,这样每个Source都可以读取同一个Topic中的数据,从而提高性能。

Kafka Source配置项
NetCat Source
NetCat Source监听指定的端口,把接收到的数据按行划分,每行文本都封装成一个Event数据发送给Channel。

NetCat Source配置项
HTTP Source
HTTP Source接收POST和GET发送的Event数据,其中GET主要用户测试,不建议生产环境使用。HTTP数据通过handler(实现HTTPSourceHandler接口)转换成Event,该handler接收HttpServletRequest并返回Event数组。如果handler出现异常,HTTP Source返回400错误。如果Channel满了或者Channel无法接收Event,HTTP Source返回503错误。

HTTP Source配置项
Flume Channel 详解

Flume内置Channel
Memory Channel
Memory Channel把Event保存在内存队列中,该队列能保存的Event数量有最大值上限。由于Event数据都保存在内存中,Memory Channel有最好的性能,不过也有数据可能会丢失的风险,如果Flume崩溃或者重启,那么保存在Channel中的Event都会丢失。同时由于内存容量有限,当Event数量达到最大值或者内存达到容量上限,Memory Channel会有数据丢失。

Memory Channel配置项
File Channel
File Channel把Event保存在本地硬盘中,比Memory Channel提供更好的可靠性和可恢复性,不过要操作本地文件,性能要差一些。

File Channel配置项
Kafka Channel
Kafka Channel把Event保存在Kafka集群中,能提供比File Channel更好的性能和比Memory Channel更高的可靠性。

Kafka Channel配置项
Spillable Memory Channel
Spillable Memory Channel把Event保存到内存队列和本地文件中,数据优先存储在内存队列中,当内存队列满了以后会保存到文件中。Spillable Memory Channel在保持较高性能的同时,又能兼顾可靠性。

Spillable Memory Channel配置项
Flume Sink详解
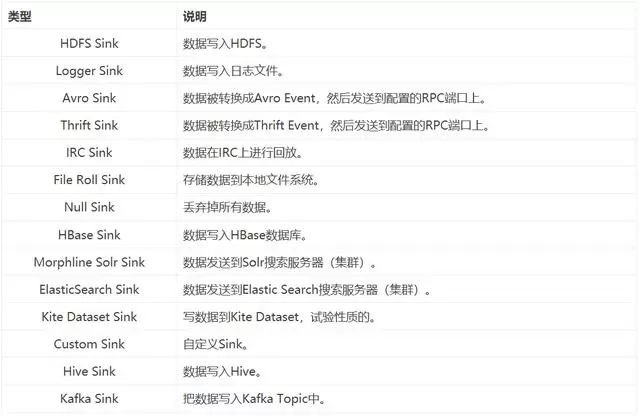
Flume内置Sink
HDFS Sink
HDFS Sink直接把Event数据写入Hadoop Distributed File System(HDFS)。HDFS Sink支持输出文本文件(text file)和序列文件(sequence file),同时还可以对数据进行压缩。数据文件可以根据固定时间间隔、文件大小或者Event数据数量创建。HDFS Sink需要Hadoop支持。

HDFS Sink配置项
Kafka Sink
Kafka Sink是Flume内置的Sink,只要稍微做配置,就可以把Event直接输出到Kafka Topic中。

Kafka Sink配置项
Avro Sink
把数据转成Avro Event格式,并发送到指定Avro端口,Event数据会批量发送,每次发送的数量可以在batch-size中设置。

Avro Sink配置项
Thrift Sink
Thrift Sink和Avro Sink类似,把数据转成Thrift Event格式,并发送到指定Thrift端口,Event数据会批量发送,每次发送的数量可以在batch-size中设置。Thrift Sink支持安全模式,可以在配置文件中设置。
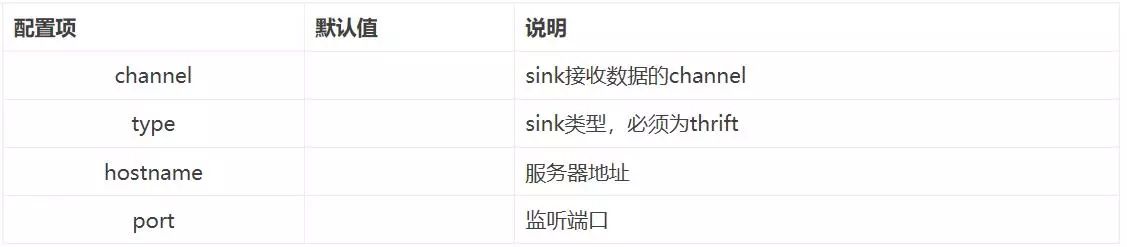
Thrift Sink配置项
Flume的选择器与拦截器
Channel Selector
Channel有两种选择器,分别是Replicating和Multiplexing,如果不指定选择器,默认使用Replicating选择器。
Replicating Selector
Replicating选择器把Event复制多份,每个Channel都会接收到相同的Event。如果Source与3个Channel关联,那么这3个Channel都会收到同样数量的Event。Source默认使用Replicating选择器。
Multiplexing Selector
Multiplexing是分流选择器,对Event数据进行过滤,根据消息头属性把Event分发到不同的Channel中。Multiplexing不是默认选择器,需要配置。下面的配置根据Event的Header属性state进行分流,如果state是CZ就发送到Channel c1中,如果state是US就发送到Channel c2和Channel c3中,如果都不是就发送到Channel c4中。
Sink Processors
Sink支持分组,可以把多个Sink放到一个分组里面,作为一个整体对外服务。Sink分组有三种类型的处理器,分别是default、failover和load_balance。
default处理器只支持单个Sink,如果分组里只有一个Sink,那么这个分组的处理器可以设置为default。通常情况下没有必要为单个Sink创建分组。
failover处理器维护一个优先级列表Sink,列表中有多个Sink,从而保证Event数据能够得到及时的处理。failover的机制是每个Sink都有个连续失败计数器,当Sink连续失败次数达到阀值时,该Sink会被降低优先级并放到冷却池中,Sink在冷却池中冷却一段时间后再启用。如果Sink成功发送一个Event,则会被恢复到活动池中。每个Sink都有优先级,优先级越高,数值越大,例如100优先级高于80优先级。如果一个Sink发送Event失败,拥有最高优先级的Sink会尝试发送失败的Event。
Flume Interceptors
Flume支持拦截器链,拦截器可以修改和丢弃Event数据(功能类似Java Web的过滤器或者Spring MVC的拦截器)。Flume自定义拦截器只要实现org.apache.flume.interceptor.Interceptor接口即可。拦截器调用的顺序在配置文件中配置,每个拦截器在调用完成后都要返回Event数据列表,如果想抛弃Event数据,只要把数据从列表中移除即可。
Flume Interceptors
以上是关于「大数据程序员开发工具」日志收集系统——Flume的功能与架构的主要内容,如果未能解决你的问题,请参考以下文章