Apache Flink从入门到放弃——快速上手(Java版)
Posted ╭⌒若隐_RowYet——大数据
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Apache Flink从入门到放弃——快速上手(Java版)相关的知识,希望对你有一定的参考价值。
目 录
1. 环境准备和创建项目
1.1 软件准备及版本
Java(JDK) 1.8Flink 1.3.0IDEACentOS 7 Or MacOSScala 2.12sfl4j 1.7.30
1.2 IDEA下创建Java项目FlinkTutorial
利用IDEA创建Java的Maven项目FlinkTutorial,创建项目时的一些参数填写;
<name>FlinkTutorial</name>
<groupId>com.rowyet</groupId>
<artifactId>FlinkTutorial</artifactId>
<version>1.0-SNAPSHOT</version>
最终的项目如图1.1;
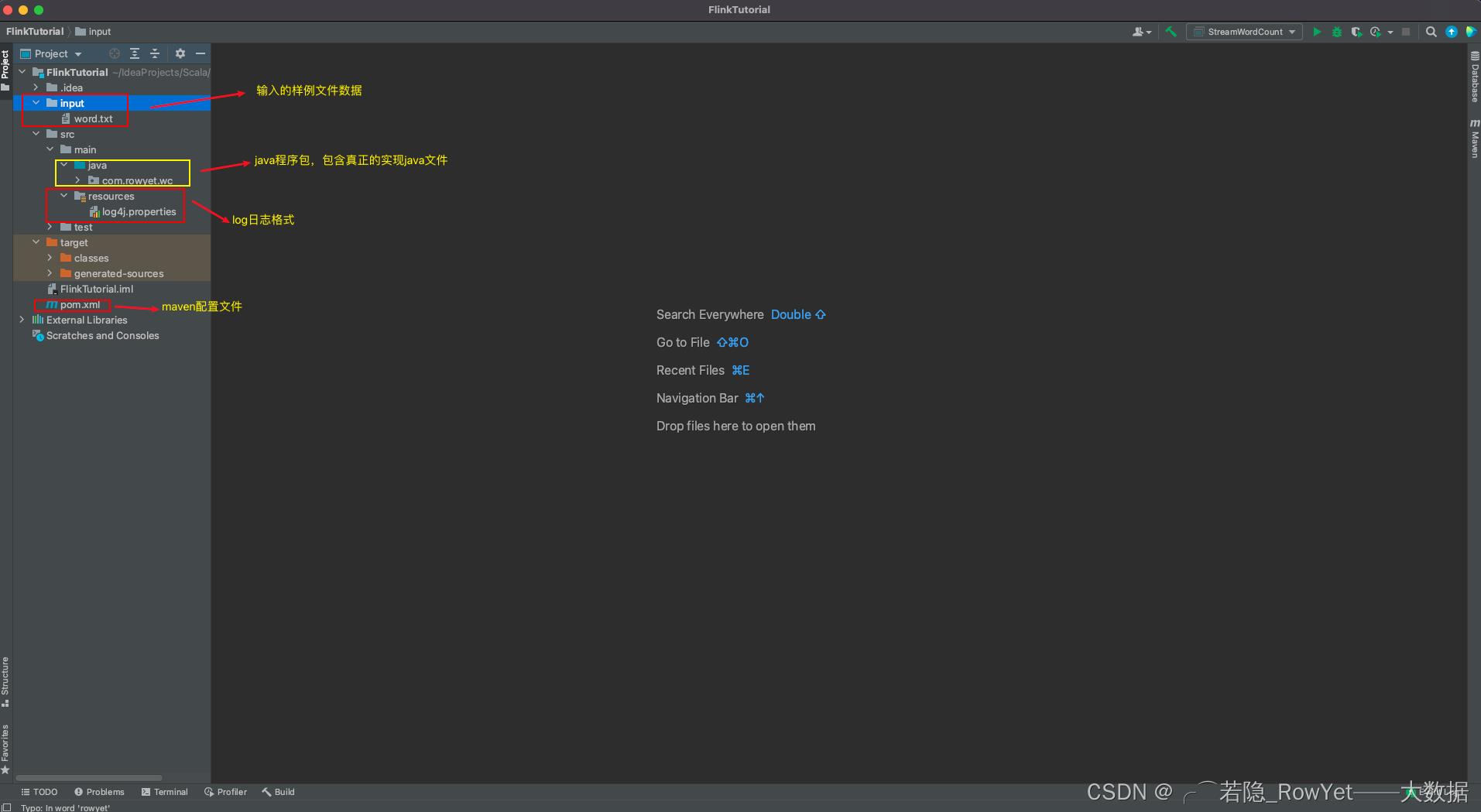
输入的样例文件:项目目录下新建文件夹input,新建一个txt文件word.txt,内容如下:
hello world
hello flink
hello java
hello rowyet
maven配置文件:pom.xml内容如下:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.rowyet</groupId>
<artifactId>FlinkTutorial</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
<flink.version>1.13.0</flink.version>
<java.version>1.8</java.version>
<scala.banary.version>2.12</scala.banary.version>
<slf4j.version>1.7.30</slf4j.version>
</properties>
<dependencies>
<!--引入Flink相关的依赖-->
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-java -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>$flink.version</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-streaming-java -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_$scala.banary.version</artifactId>
<version>$flink.version</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-clients -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_$scala.banary.version</artifactId>
<version>$flink.version</version>
</dependency>
<!--引入日志相关的依赖-->
<!-- https://mvnrepository.com/artifact/org.slf4j/slf4j-api -->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>$slf4j.version</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.slf4j/slf4j-log4j12 -->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>$slf4j.version</version>
<type>pom</type>
<scope>test</scope>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.logging.log4j/log4j-to-slf4j -->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>$slf4j.version</version>
</dependency>
</dependencies>
</project>
log日志格式:在resources下新建日志文件log4j.propertries,内容如下:
### 设置###
log4j.rootLogger = error,stdout
### 输出信息到控制抬 ###
log4j.appender.stdout = org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout = org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern = %-4r [%t] %-5p %c %x -%m%n
- 最后,在
src/main/java下新建Java包com.rowyet.wc,开始编写Flink的练手项目;
2. DataSet API 批处理实现word count
com.rowyet.wc包下创建Java class文件BatchWorldCount,内容如下:
package com.rowyet.wc;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.operators.AggregateOperator;
import org.apache.flink.api.java.operators.DataSource;
import org.apache.flink.api.java.operators.FlatMapOperator;
import org.apache.flink.api.java.operators.UnsortedGrouping;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.util.Collector;
public class BatchWorldCount
public static void main(String[] args) throws Exception
// 1. 创建执行环境
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
// 2. 从文件中读取数据
DataSource<String> lineDataSource = env.readTextFile("input/word.txt");
// 3. 将每行数据进行分词,转换成二元组类型,利用java lambda表达式实现flatMap
FlatMapOperator<String, Tuple2<String, Long>> wordAndOneTuple = lineDataSource.flatMap((String line, Collector<Tuple2<String, Long>> out) ->
String[] words = line.split(" ");
for (String word : words)
out.collect(Tuple2.of(word, 1L));
).returns(Types.TUPLE(Types.STRING, Types.LONG));
// 4. 按照word进行分组,利用word的索引0,即第一个元素进行分组
UnsortedGrouping<Tuple2<String, Long>> wordAndOneGroup = wordAndOneTuple.groupBy(0);
// 5. 分组内进行聚合统计,根据word分组后的索引1,即第二个元素进行求和
AggregateOperator<Tuple2<String, Long>> sum = wordAndOneGroup.sum(1);
// 6. 打印结果
sum.print();
运行结果,如图2.1;

3. DataSet API VS DataStream API
在Flink 1.12版本开始,官方就推荐使用DataSteam API,在提交任务时只需要通过以下shell参数指定模式为BATCH即可;
bin/flink run -Dexecution.runtime-mode=BATCH BatchWorldCount.jar
如此一来,DataSet API就已经处于软弃用(soft deprecated)的状态,而且实际应用中只需要维护一套DataStream API即可,真正的向流批一体迈进。
4. DataStream API 流处理实现word count
4.1 有界的流处理
com.rowyet.wc包下创建Java class文件BoundedStreamWordCount,内容如下:
package com.rowyet.wc;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
public class BoundedStreamWordCount
public static void main(String[] args) throws Exception
// 1. 创建流式的执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 2. 读取文件
DataStreamSource<String> lineDataStreamSource = env.readTextFile("input/word.txt");
// 3. 转化计算
SingleOutputStreamOperator<Tuple2<String, Long>> wordAndOneTuple = lineDataStreamSource.flatMap((String line, Collector<Tuple2<String, Long>> out) ->
String[] words = line.split(" ");
for (String word : words)
out.collect(Tuple2.of(word, 1L));
).returns(Types.TUPLE(Types.STRING, Types.LONG));
// 4. 分组
KeyedStream<Tuple2<String, Long>, String> wordAndOneKeyedStream = wordAndOneTuple.keyBy(data -> data.f0);
// 5. 求和
SingleOutputStreamOperator<Tuple2<String, Long>> sum = wordAndOneKeyedStream.sum(1);
// 6. 打印
sum.print();
// 7. 启动执行
env.execute();
运行结果,如图2.2,发现跟之前图2.1的运行结果有些不一样,具体区别在哪呢?
- 数据出现无序了,而且是来一条处理一条,最终的结果才是准确的结果;
- 结果前面有一个序号,而且相同的word序号相同,这是因为
Flink最终运行在分布式的集群内,而这个序号是IDEA模拟分布式集群,代表你的CPU的核数的一个CPU序号,博主的CPU是8核的(可以理解为有CPU8个),所以序号不会大于8,以此类推自己的CPU总核数和运行结果,至于为什么相同的word序号是一样的,是因为相同的word作为分区的key,最终肯定要在同一个处理器上才可以进行后续的sum统计呢。

4.2 无界的流处理
这里利用linux的netcat命令监听端口7777的连续不断输入的word为例,实现无界的流处理word count的统计;
com.rowyet.wc包下创建Java class文件StreamWordCount,内容如下:
package com.rowyet.wc;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.api.java.utils.ParameterTool;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
public class StreamWordCount
public static void main(String[] args) throws Exception
// 1. 创建流式环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 2. 读取文本流
// DataStreamSource<String> lineDataSource = env.socketTextStream("127.0.0.1", 7777); //测试可以写死参数
//生产中一般,通过main函数后接参数实现
ParameterTool parameterTool = ParameterTool.fromArgs(args);
String host = parameterTool.get("host");
int port = parameterTool.getInt("port");
// 运行时在菜单栏Run—>Edit Configuration—>Program arguments文本框内填入 --host "127.0.0.1" --port 7777
DataStreamSource<String> lineDataSource = env.socketTextStream(host, port);
// 3. 转换处理
SingleOutputStreamOperator<Tuple2<String, Long>> wordOneTuple = lineDataSource.flatMap((String line, Collector<Tuple2<String, Long>> out) ->
String[] words = line.split(" ");
for (String word : words)
out.collect(Tuple2.of(word, 1L));
).returns(Types.TUPLE(Types.STRING, Types.LONG));
// 4. 分组
KeyedStream<Tuple2<String, Long>, String> wordAndOneKeyedStream = wordOneTuple.keyBy(data -> data.f0);
// 5. 求和
SingleOutputStreamOperator<Tuple2<String, Long>> sum = wordAndOneKeyedStream.sum(1);
// 6. 输出
sum.print();
// 7. 启动执行
env.execute();
写完代码后接下来的操作顺序很重要,要注意!!!
写完代码后接下来的操作顺序很重要,要注意!!!
写完代码后接下来的操作顺序很重要,要注意!!!
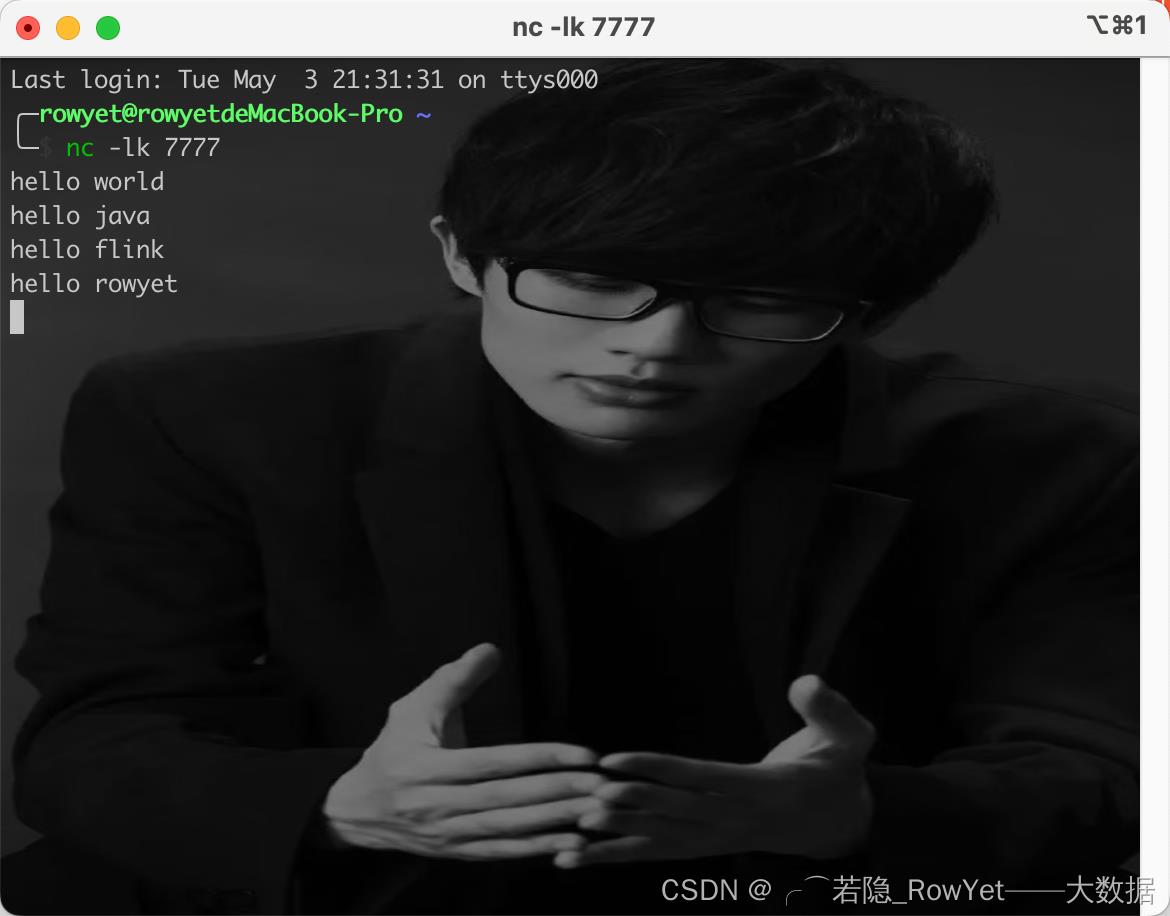
- 在某一台Linux或者MacOS开启
netcat命令监听本地7777端口,博主的是本地的MacOS终端,指令是:
nc -lk 7777
# 回车启动,先不要输入内容
- 启动刚刚写好的Java Class文件
StreamWordCount,暂时看不到任何东西,一直等待输出的空白输出框,如图2.3;

- 如图2.4,在步骤1的MacOS终端启动的
netcat环境内输入一些聊天消息;
- 最中在IDEA的运行结果内会实时得到运算结果,如图2.5

5. 试炼项目代码链接
以上就是以经典的大数据word count统计为例,讲述传统Apache Flink DataSet API(批处理API)和新的流式DataStream API的两种实现,从代码动手开始揭开Apache Flink的神秘面纱,整个试炼项目代码链接如下:
以上是关于Apache Flink从入门到放弃——快速上手(Java版)的主要内容,如果未能解决你的问题,请参考以下文章