Apache Flink从入门到放弃——Flink简介
Posted ╭⌒若隐_RowYet——大数据
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Apache Flink从入门到放弃——Flink简介相关的知识,希望对你有一定的参考价值。
目 录
1. 计算引擎的发展历史
随着大数据的发展,大数据的存储、计算、运用百花齐放;而大数据的计算中最重要的就是计算引擎,时至今日,很多人将大数据引擎分为四代,分别是:
-
第一代,Hadoop承载的MapReduce,将计算分为Map和Reduce两个阶段,同时采用Hadoop集群的分布式计算原理来实现数据的计算,但是MapReduce存在很明显的缺点
1)针对多个迭代计算只能用多个Job的多次MapReduce串联完成
2)大量的中间结果要溢写到磁盘,因此存在大量的磁盘交互,效率十分低下; -
第二代,带有DAG(Directed Acyclic Graph 有向无环图)框架的计算引擎,如Tez以及调度的Oozie,在第一代的基础上增加了DAG,但是运算效率还是达不到许多需求的要求;
-
第三代,以Spark为代表的内存计算引擎,赢得了内存计算的飞速发展,第三代计算引擎的特点是主要不仅DAG(有向无环图),也以内存为赌注,强调计算的实时性型,是目前批处理的佼佼者,给用户十分友好的体验,一度被人认为要在计算引擎上一统天下的;
-
随着实时计算需求的迫切性,各种迭代计算的性能以及对流式计算和SQL的支持,以Spark Streming为例也支持流式计算,而且能解决99%的流式计算要求,但是Spark Streaming设计理念里面认为流是批的极限,即微批(micro-batch)就是流式,所以有个致命的缺点就是攒批;因为这个缺点的存在,剩下的1%的流式运算并不太适合Spark,而Flink就很好的规避了这个缺点,认为批是流的特例,把数据计算归为有界和无界的,有界的数据就是批处理,无界的数据就是流式,而且以流批一体为终极计算目标,Flink就被归在第四类内,从这里开始时就正式揭开Flink的面纱!
2. 什么是Flink
2.1 概念
Apache Flinkis a framework and distributed processing engine for stateful computations over unbounded and bounded data streams. Flink has been designed to run in all common cluster environments, perform computations at in-memory speed and at any scale.
Apache Flink是一个分布式大数据计算引擎,可以对有界的数据和无界的数据进行有状态的计算,可部署在各种集群环境中,对各种大小数据规模进行快速计算,整个Flink的框架如图2.1;

2.2 什么是有界的数据流和无界数据流
在Flink的设计理念中,将数据分为有界数据和无界数据,如图2.2;
有界数据(Bounded data):定义了数据的开始和结束,也就是批处理的本质;无界数据(Unbounded data): 数据定义了开始,但是没有结束,因此需要连续不断的处理计算,如基于事件的有序驱动。

2.3 Fink的历史
- 前生是
Stratosphere,是一个研究性项目,其目标是开发下一代大数据分析平台。该项目由德国的几所大学和机构共同研究; - 2014年4月,贡献给Apache软件基金会,更名为Apache Flink;
- 2014年8月,Flink第一个版本0.6正式发布,与此同时Fink的几位核心开发者创办了Data Artisans公司;
- 2014年12月,Flink项目完成孵化,成为Apache顶级项目;
- 2015年4月,Flink发布了里程碑式的重要版本0.9.0;
- 2019年1月,长期对Flink投入研发的阿里巴巴,以9000万欧元的价格收购了Data Artisans公司;
- 2019年8月,阿里巴巴将内部版本Blink开源,合并入Flink1.9.0版本;
- 2020年5月,Apache Flink 1.10.0发布;
- 2020年7月,Apache Flink 1.11.0发布;
- 2020年12月,Apache Flink 1.12.0发布
- 2021年4月,Apache Flink 1.13.0发布;
- 2021年9月,Apache Flink 1.14.0发布;
- ……
目前2022年,生产上使用的Flink以1.12.X和1.13.X为主,看时间序列也可以知道Flink发展十分迅速,而且常年在在github的活跃度、访问量名列前茅。
2.4 Flink的特点
- 支持
java(主)和scala api(真香),新版本支持python api; - 流(dataStream)批(dataSet)一体化,支持事件处理和无序处理通过DataStreamAPI,基于DataFlow数据流模型,在不同的时间语义(事件时间,摄取时间、处理时间)下支持灵活的窗口(时间,滑动、翻滚,会话,自定义触发器;
- 支持有状态计算的Exactly-once(仅处理一次)容错保证,支持基干轻量级分布式快照checkpoint机制实现的容错,支持savepoints机制,一般手动触发,在升级应用或者处理历史数据是能够做到无状态丢失和最小停机时间
- 兼容hadoop的mapreduce,集成YARN、HDFS、Hbase和其它hadoop生态系统的组件,支持大规模的集群模式,支持yarn、mesos。可运行在成千上万的节点上;
- 在dataSet(批处理)API中内置支持迭代程序
- 图处理(批)机器学习(批)复杂事件处理(流)
- 自动反压机制
- 高效的自定义内存管理
- 健壮的切换能力在in-memory和out-of-core中
2.5 Flink的应用
- 批处理和流处理
- 流数据更真实地反应了我们的生活方式
- 低延时、高吞吐、结果准确和良好的容错性
- 流批一体的终极目标
基于以上优点,Flink在目前的大数据计算中简直是大红大紫,如图2.5.1,许多大厂公司的宠儿,都会用到Flink;

Flink有很多用途,目前而言,最佳的使用场景有哪些呢,如图2.5.2;

2.6 流批架构的演变
- 传统关系型数据的系统架构,如mysql、SQL Server为后台数据库的OLTP系统;
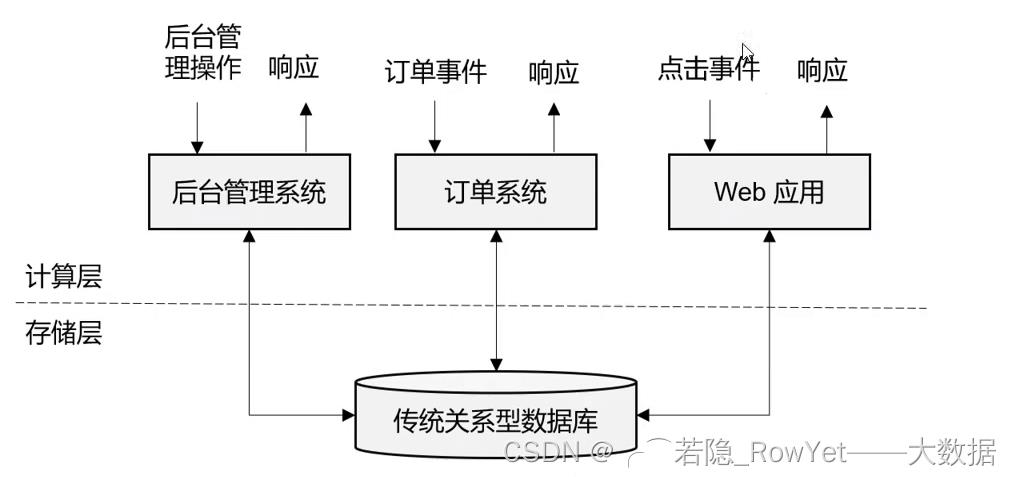
- 有状态的流处理,因为传统的OLTP不太好满足OLAP的数据分析而诞生,即将应用逻辑和本地状态存在内存,同时定期存盘持久化,保证数据的不被丢失,此种框架以storm为代表,但是也存在必然缺陷,那就是数据在分布式的机器下,因为网络等不稳定因素,无法保证有序和精准的一次性消费。

- lambda架构,即用每一段时间的批处理数据刷新最新的数据,而当时最新的数据用流处理来做增量,可以理解为批处理做一次覆盖,流处理做实时增量,因为有批处理的保证,数据最终一致性得到保证,缺点是维护两套架构,工程量比较大;
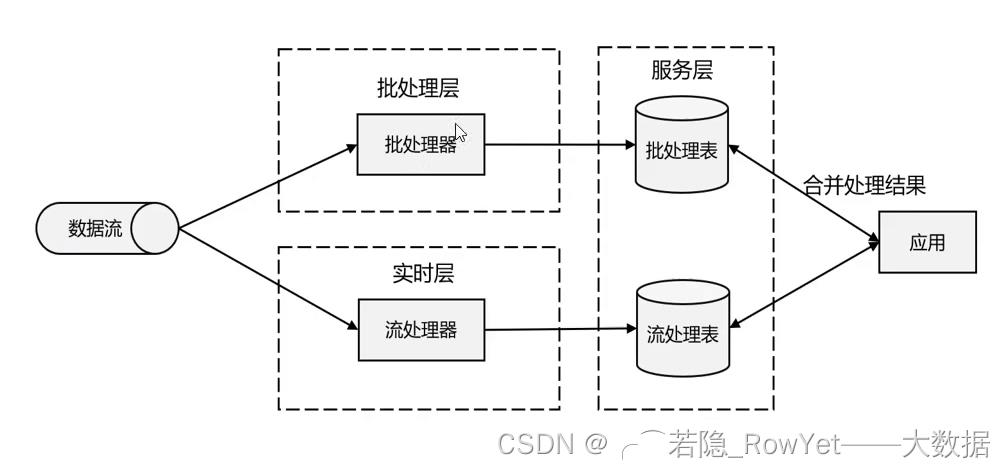
- 实时数仓框
1)事件驱动型实时数仓,如图2.6.4,前端运用的事件触发(如点击按钮、扫码等)将关键性的数据变化写入消息队列(kafka,RabbitMQ等),然后利用Flink消费消息队列的数据进行处理,处理后的数据可以持久化存储到各大存储组件内(hive,hbase,hdfs等),也可以重新写回到消息队列内供下一个运用使用;

2) 数据分析实时数仓型,如图2.6.5,主要就是通过根据OLTP系统后端数据库的change log,来实时定期更新至数据数仓的存储媒介(HDFS、Hbase、ElasticSearch、KuDu、ClickHouse)等内,再外接可视化报(apache superset)表实时呈现数据;

2.7 Flink的分层API
- 越顶层越抽象,表达含义越简明,使用越方便
- 越底层越具体,表达能力越丰富,使用越灵活
- Flink版本更新迭代最主要原因之一:丰富上层API的内容,让Flink越来越容易的被使用;

3. Flink VS Spark
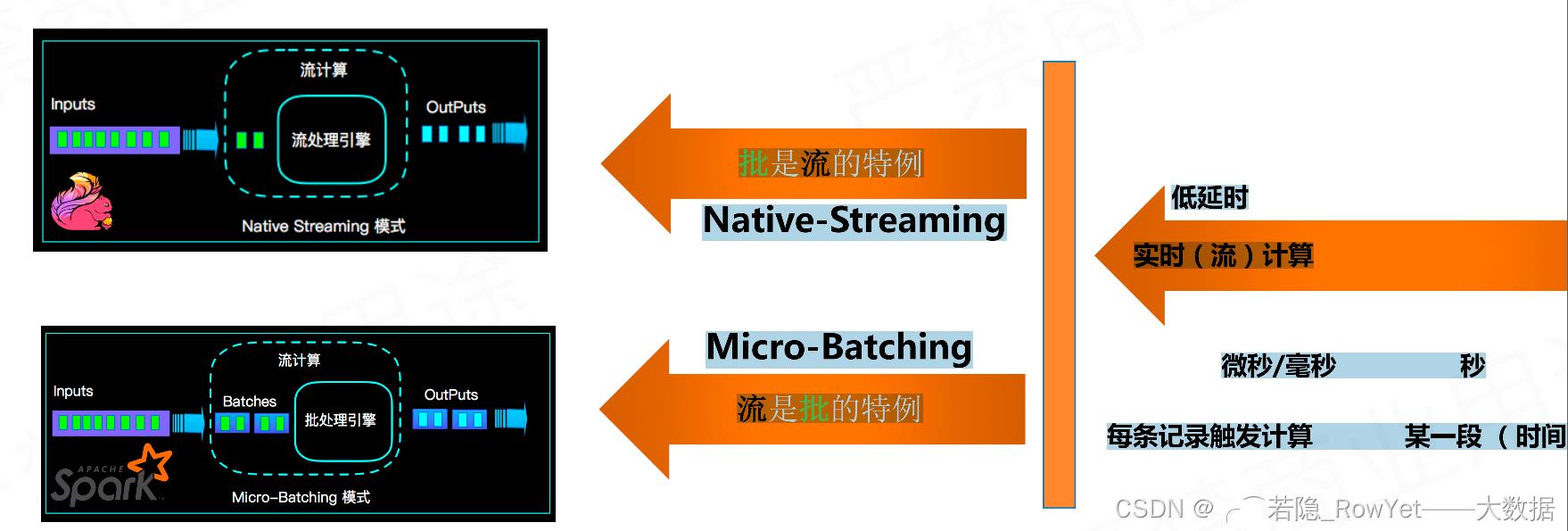
- 三观
1)Spark认为流是批的特例,采用微批的概念,输入数据流进来后Spark Stream将数据切割成一个个微批(Micro-batch)处理;
2)Flink将数据分为有界数据和无界数据,有界的数据就是批处理,无界的数据就是流计算;
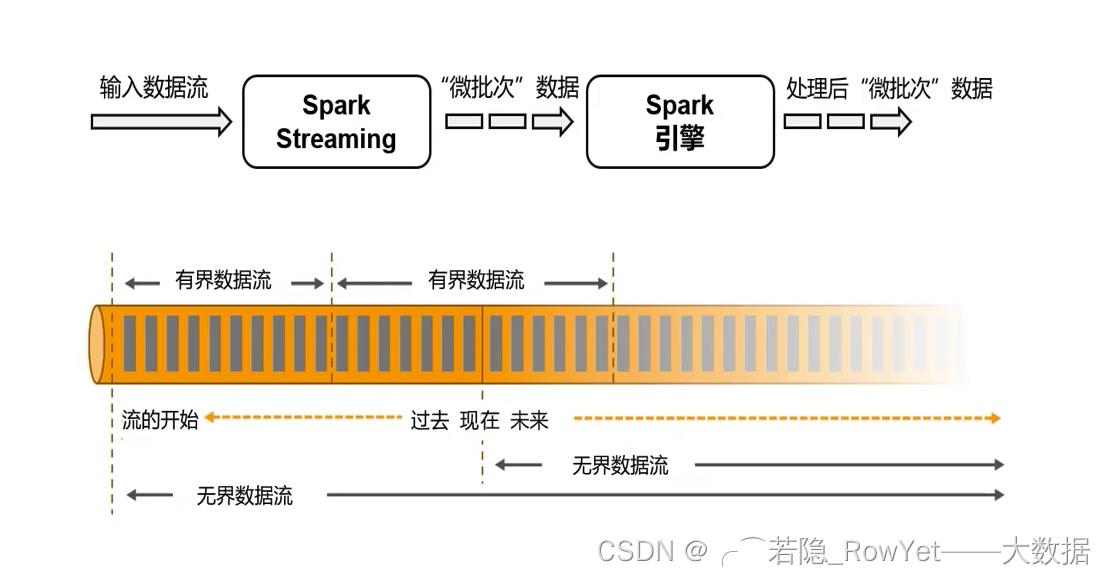
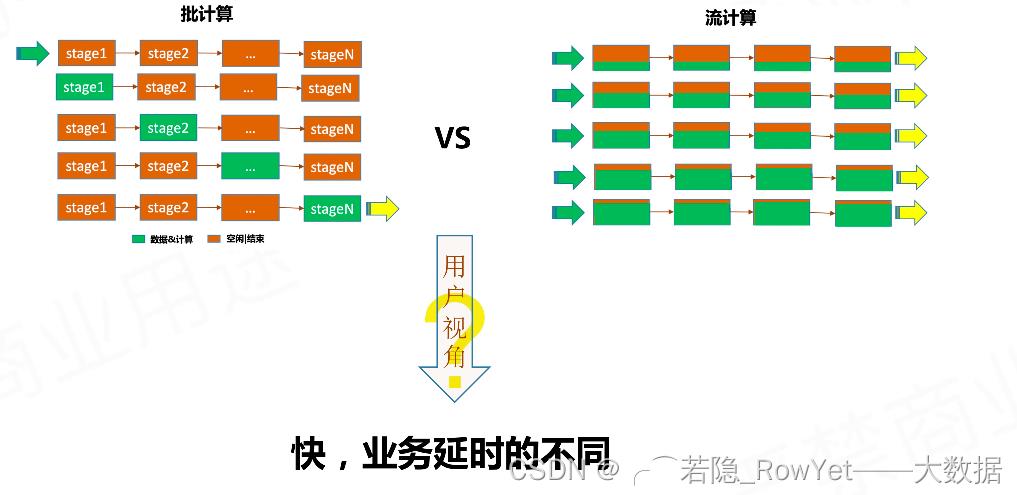
- 运行时框架
1)Spark是批计算,将DAG划分为不同的stage,一个完成后才可以计算下一个;
2)Flink是标准的流执行模式,一个事件在一个节点处理完后可以直接发往下一个节点进行处理。
以上是关于Apache Flink从入门到放弃——Flink简介的主要内容,如果未能解决你的问题,请参考以下文章