CartPole环境下的强化学习
Posted HuangDell
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了CartPole环境下的强化学习相关的知识,希望对你有一定的参考价值。
CartPole环境下的强化学习
实验题目
以Cart Pole为环境,实现DQN和PG算法,要求进行可视化(reward, loss, entropy 等)。
实验内容
Deep Q-Network
算法原理
传统的Q Learning强化学习难以处理环境状态极多的情况,在DQN中,使用了深度学习网络代替了Q Table,使之可以计算海量状态所对应动作的Q值,并且具有Q Learning所不具有的泛化能力。这就是DQN与Q Learning的最大不同之处。
既然涉及到深度学习网络,那使用什么作为神经网络的输入和标签呢?下面我将对此展开分析。
首先我们都知道Q值的更新公式: Q t = R t + 1 + γ m a x Q ( S t + 1 , a ) Q_t=R_t+1+\\gamma maxQ(S_t+1,a) Qt=Rt+1+γmaxQ(St+1,a),其中 γ \\gamma γ是未来收益的损失系数。Q值的迭代公式就是如此,那我们就可以把目标Q值作为神经网络的标签用以训练网络,我们的目标就是让神经网络的输出Q值无限接近于目标Q值。
我们也可以顺便得到Q深度学习网络的损失函数:
L ( w ) = E [ ( r e w a r d + γ m a x Q ( S t + 1 , a ′ ) − Q ( S t , a ) ) 2 ] L(w)=E[(reward+\\gamma maxQ(S_t+1,a^')-Q(S_t,a))^2] L(w)=E[(reward+γmaxQ(St+1,a′)−Q(St,a))2]
这里采用均方误差作为损失函数。 Q ( S t , a ) Q(S_t,a) Q(St,a)和 Q ( S t + 1 , a ′ ) Q(S_t+1,a^') Q(St+1,a′)分别对应着当前状态的Q值和下一状态的Q值,均是由神经网络的输出而来。我们需要找出下一状态的最大Q值,和当前动作所得到的reward组合,去作为当前Q值的目标Q值。
但是,在神经网络的训练过程中存在这样一个问题:目标Q值不固定的问题。由于目标Q值依赖与当前的状态和动作,所以是会不断变化的。为了解决这个问题,我们则需要采用两个深度学习网络来训练: t a r g e t target target和 e v a l eval eval两个网络。 t a r g e t target target网络不参与训练,仅用于提供一定时间内不会变化的目标Q值,而 e v a l eval eval网络则用于训练,负责无限逼近 t a r g e t target target网络所给出的目标Q值和reward之和。
就此,Q网络就得到了有效的训练。以上就是最为关键的DQN原理。
伪代码

上述图片清晰地给出了DQN双神经网络训练加记忆池的一个基本流程
来自于:2015版《Human-level control through deep reinforcement learning》
关键代码展示
深度神经网络的创建
class DeepNetwork:
def __init__(self,state_n,action_n,loss,load_path=None):
self.state_n=state_n # 输出状态维度
self.action_n=action_n # 输出状态维度
self.hide1_n=128 # 隐藏层维度
self.hide2_n=128
self.learn_rate=0.01
# 包含两个神经网络
self.target = self._create_net(loss)
if load_path: # 加载之前训练好的网络
self.eval = tf.keras.models.load_model(load_path)
else:
self.eval=self._create_net(loss)
def _create_net(self,loss):
model = tf.keras.models.Sequential([
tf.keras.layers.Input(shape=self.state_n),
# 设置多层隐藏层
tf.keras.layers.Dense(self.hide1_n,activation='relu',name='l1'),
tf.keras.layers.Dense(self.hide2_n, activation='relu',name='l2'),
tf.keras.layers.Dense(self.action_n,name='l3')
])
model.compile(optimizer=tf.optimizers.Adam(learning_rate=self.learn_rate),
loss=loss)
return model
在初始化函数中,定义了神经网络的输入层、隐藏层、输出层和各个权重、阈值,使用了tensorflow来更为快捷地创建深度学习网络。
深度神经网络的训练
# 对深度神经网络进行训练
def learn(self,state,action,reward,next_state,done,batch_size):
if self.study_count==self.update_count:
# 更新target网络,需要逐层更新参数
self.target.get_layer(name='l1').set_weights(self.eval.get_layer(name='l1').get_weights())
self.target.get_layer(name='l2').set_weights(self.eval.get_layer(name='l2').get_weights())
self.target.get_layer(name='l3').set_weights(self.eval.get_layer(name='l3').get_weights())
self.study_count=0
next_state_value = self.target.predict(next_state,verbose=0) # 下一个状态的q值
best_q = tf.reduce_max(next_state_value, axis=1) # 找到最佳Q值
done = tf.cast(done, dtype=tf.float32) # 将done转化为tensor
target = reward + self.gamma * (1.0 - done) * best_q # 计算target
current = self.eval.predict(state, verbose=0)
for i in range(batch_size):
current[i,action[i]]=target[i] # 修改当前神经网络的对应action的Q值
# 训练模型
self.eval.fit(state,current,batch_size=batch_size,epochs=2,verbose=0,callbacks=[self.tensorboard_callback])
self.study_count += 1
训练数据的获取
for e in range(episodes):
state = self.env.reset()
# 尝试500steps
for time in range(500):
action = self.agent.action(state)
next_state, _, done, _ =self. env.step(action)
# 对reward进行修改
x, x_dot, theta, theta_dot = next_state
r1 = (self.env.x_threshold - abs(x)) / self.env.x_threshold - 0.8
r2 = (self.env.theta_threshold_radians - abs(theta)) / self.env.theta_threshold_radians - 0.5
reward = r1 + r2
# 放入记忆池中
self.pool.remember(state, action, reward, next_state, done)
state = next_state
# 将reward写入tensorboard
self.record('reward',reward,time)
# 满足batch_size 进行深度网络学习
if len(self.pool) > batch_size:
batch_state, batch_action, batch_reward, batch_next_state, batch_done \\
= self.pool.sample(batch_size) # 从记忆池中获取一个batch
self.learn(batch_state, batch_action, batch_reward, batch_next_state, batch_done, batch_size)
if done:
print(f"episode: e + 1/episodes, score: time,e: self.agent.e")
self.record('score',time,e)
break
在训练集的获取上,采用了记忆池技巧,只有当数据数量大于一个batch时才开始训练神经网络,避免了因前期数据量不足而导致的过拟合问题。
创新点
更好的奖励
在查阅强化学习的相关资料中可以得知:奖励是强化学习训练的一个十分关键的因子,好的奖励有助于更快地、更好地训练出好的模型。基于这个观念,我开始对Cart-Pole环境所给出的奖励进行调整。
原始的奖励设置是当杆不倒时,每做出一个action就会获得1reward。这时候就会出现这种情况:当杆快要倒下的时候,如果下一步的action加重了杆倒下的趋势,获得的奖励是1reward,而阻止杆倒下的action获得的reward也是1reward。显然,我们并不希望这两个action的reward相同!
那如何对奖励机制进行调整呢?通过简单的观察可以发现,Card-Pole最好的情况就是杆一直保持数值,这样倒下的风险就会小很多。除此之外,保持杠一直处于游戏界面中间的位置,这样滑出屏幕的可能性也会降低。所以我们可以基于杆当前的倾斜角度和杆的坐标来设计相应的奖励。
# 对reward进行修改
pos, _, theta, _ = next_state
# 根据当前位置设置奖励
r1 = (self.env.x_threshold - abs(pos)) / self.env.x_threshold - 0.8
# 根据当前倾斜角度设置奖励
r2 = (self.env.theta_threshold_radians - abs(theta)) / self.env.theta_threshold_radians - 0.5
reward = r1 + r2
这样我们就得到了更好的奖励机制!
运行结果
本次测试提供了数据的可视化,通过tensorboard将训练模型的loss,reward和score进行了可视化。
程序界面
这次程序提供了两个功能:

1是模型的训练,模型训练完成后将以dqn_model+time的命名方式保存在本地
2是对训练好的模型进行测试
训练过程展示
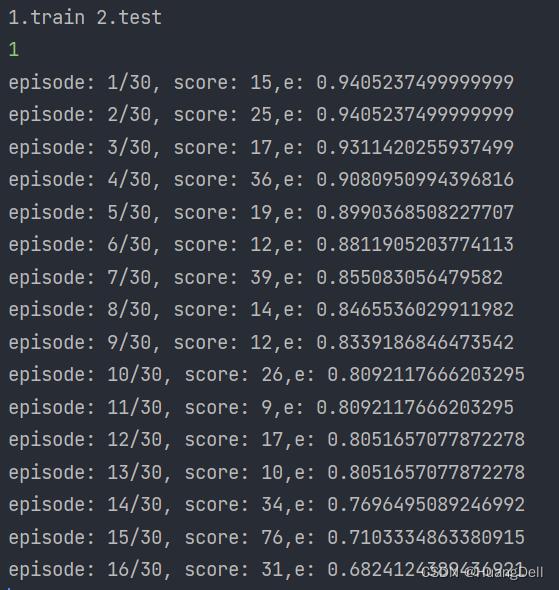
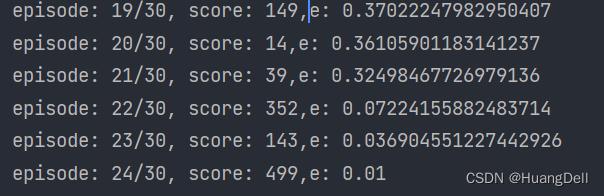
由于本训练模型收敛性较好,只需要训练差不多30代就可以达到满分的(499),故一般设置训练次数为30。
从结果中也可以看出,训练到24代时就已经出现了满分的情况。这也说明此训练模型的优良之处。
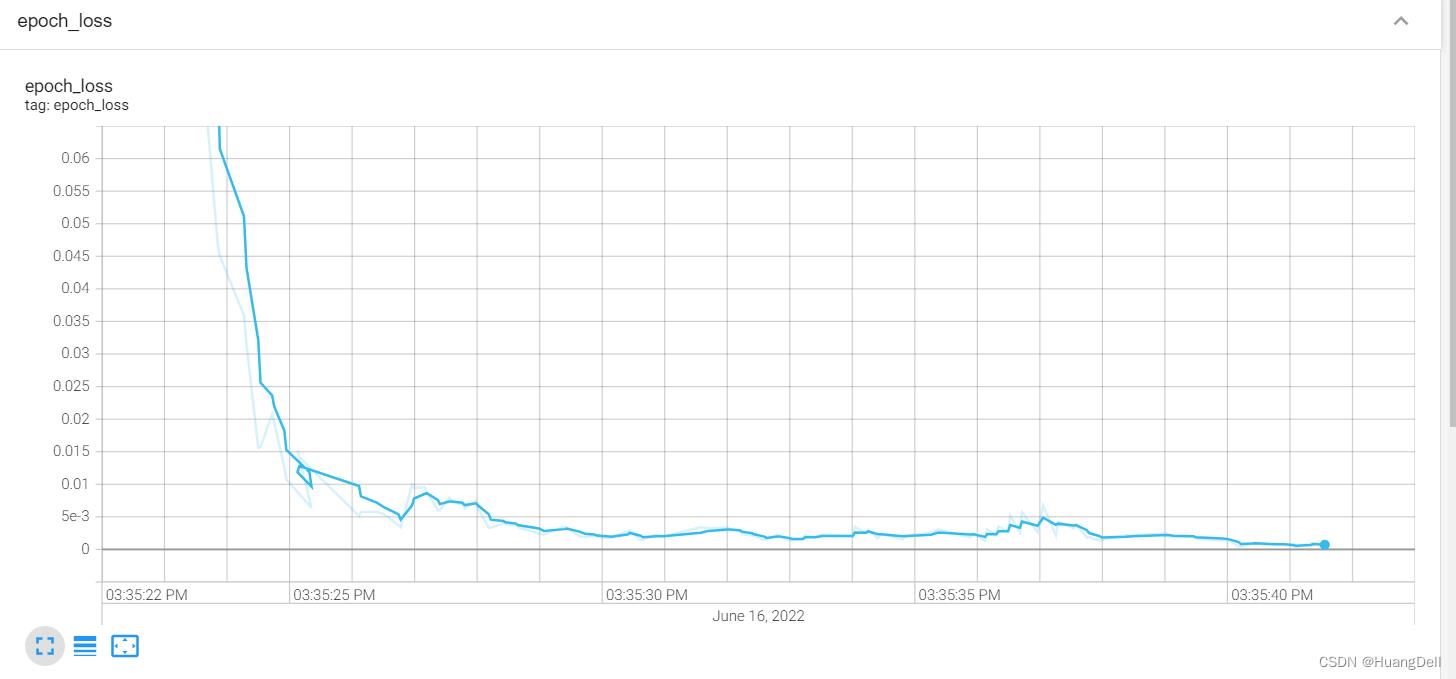
loss可视化
单独一代的损失率变化:
多代训练的损失率变化
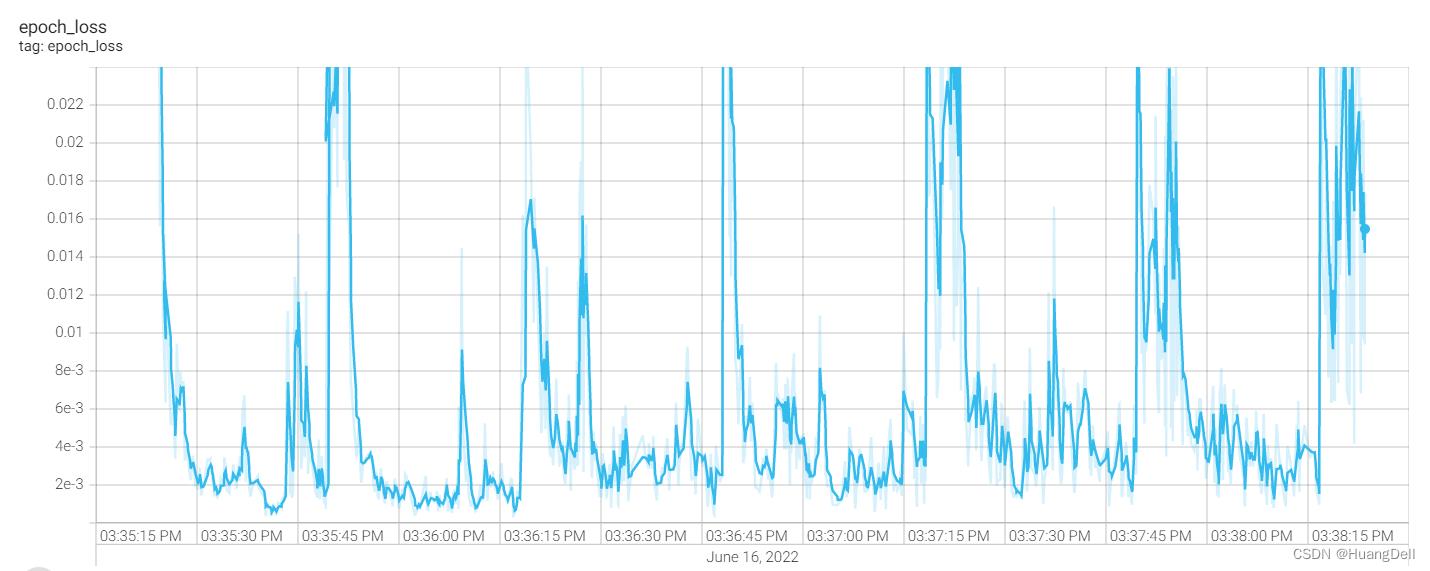
对于每一代的训练,损失率呈现一个周期率的变化并不断地降低。符合机器学习的一般规律。
reward可视化
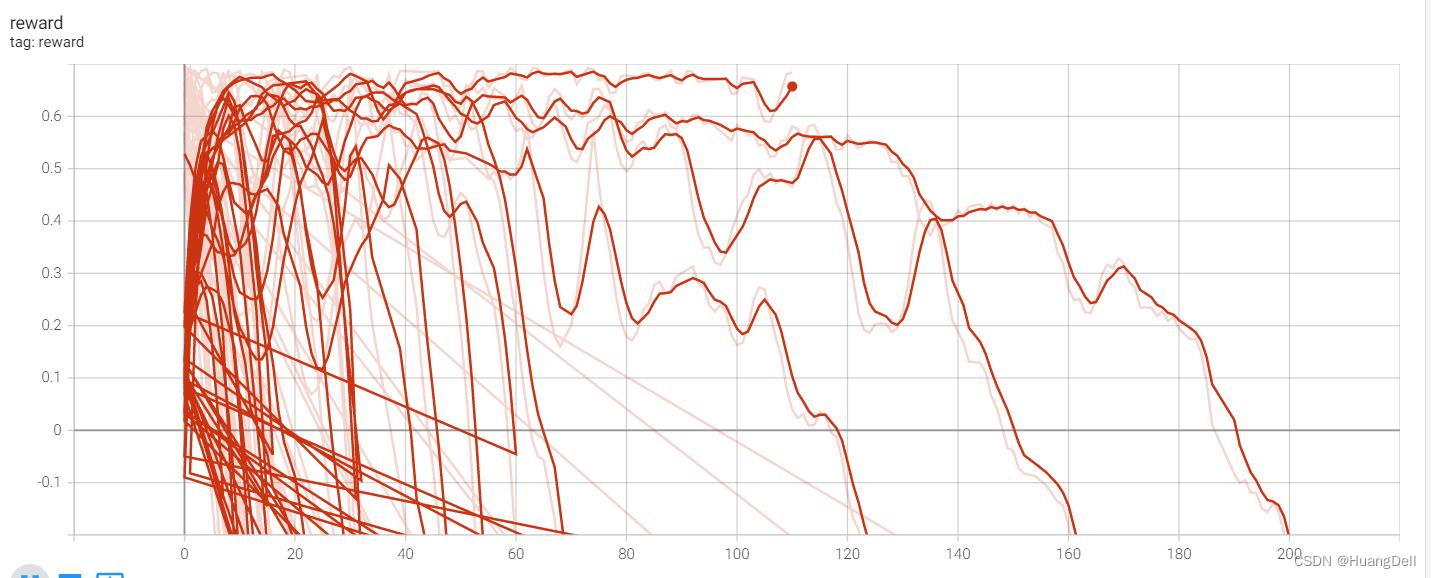
对于reward的可视化中也可以发现,当训练刚开始是选择的action的奖励值一般是>0.2的,当杆快要倒下的时候,奖励值就开始<0。这也证实了修改后的奖励机制的正确性。
对于高分的训练,通过观察曲线也可以看出前后的奖励基本都保持在同一个水平上。
score可视化
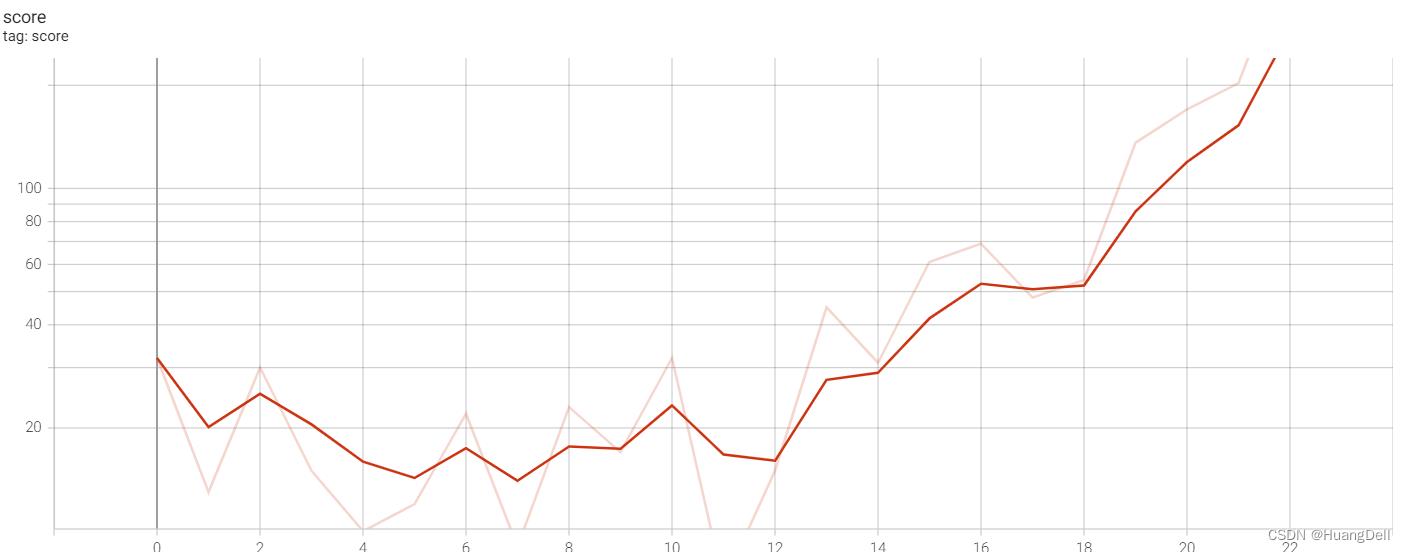
展示了每一代的最后得分。可以发现随着训练的继续,得分不断升高,这表明了此模型的有效性。
实验结果
测试50次,考查平均值和方差
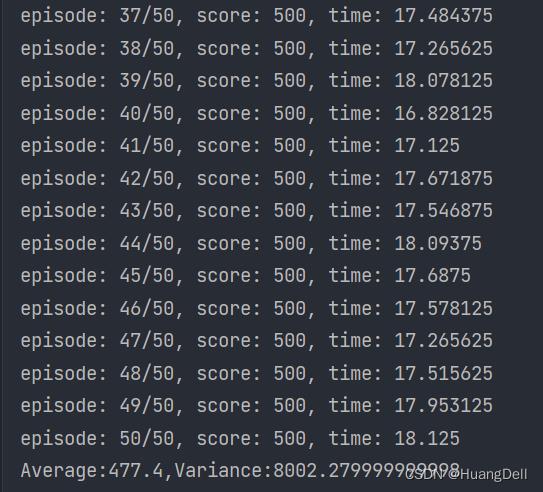
可以看到对于环境Cart-Pole-v1,我们的强化学习模型完成地十分出色,均值来到了478分,多数测试都是满分的结果。由此可以得出次模型的设计是成功的。
Policy Gradient
算法原理
上一个DQN学习的是在状态s下动作a的价值,是属于value-based方法。现在将要介绍的Policy Gradient算法则是policy-based方法,也即学习在状态s下动作a被选择的概率。
由Policy Gradient算法的基本原理我们也可以得到一下关键事实:可以获得越大奖励的动作应该被选择的概率也是越大的。所以我们的训练目的就是提高高奖励动作的被选择概率、降低低奖励动作的被选择概率。
与DQN算法不同的是,我们需要知道每一个动作的奖励的确切值,所以我们必须要完整地执行一整局游戏,记录每一个动作获得的奖励,然后再用于训练我们的神经网络。
由于PG神经网络不再输出Q值,而是直接输出动作的概率,所以我们对应的损失函数也学要做出相应的改变,不能再使用之前的均方误差函数。
在这里我们需要采用交叉熵作为损失函数: l o s s = − Q ( s , a ) l o g π ( a ∣ s ) loss=-Q(s,a)log\\pi(a|s) loss=−Q(s,a)logπ(a∣s)
这个公式的具体含义就是:对于给定状态s下的Q值与神经网络的输出动作之间的交叉熵。当交叉熵越小,说明神经网络的输出越接近Q值的分布。
这时候有一个关键问题:如何获取Q值?
答案其实很简单:就是利用之前保存的每一个动作的奖励计算而来。
Q t = R t + 1 + γ Q ( S t + 1 , a ) Q_t=R_t+1+\\gamma Q(S_t+1,a) Qt=Rt+1+γQ(St+1,a)
这时候的 Q ( S t + 1 , a ) Q(S_t+1,a) Q(St+1,a)的值就不需要神经网络进行近似估计,可以直接读取数据来获取。
PG算法的核心思想就是这些。
伪代码

- 开始一局游戏,记录state,action,reward,直到游戏结束
- 计算出每一个state的Q值
- 计算loss函数
- 重复直至强化学习收敛或达到一定次数
关键代码展示
神经网络的创建
def build_net(self):
model = models.Sequential([
layers.Dense(100, input_dim=self.state_n, activation='relu'),
layers.Dense(self.action_n, activation="softmax")
])
model.compile(optimizer=tf.optimizers.Adam(learning_rate=self.learn_rate),
loss='mse')
return model
注意这里的损失函数并没有采用categorical_crossentropy交叉熵函数,而是使用了均方误差函数。事实上这里的具体实现上我采用了另外一种思路:训练样本权重设置。具体过程可以在创新点中查看。
这里只采用了两层神经网络,因为在测试的过程中发现过多层数的深度学习网络会导致过拟合现象频发,所以减少了神经网络的层数。
计算奖励
def calculate_rewards(self,rewards):
ans = np.zeros_like(rewards)
reward = 0
for i in reversed(range(len(rewards))):
prior = reward * self.gamma + rewards[i]
ans[i] = prior
# 正态标准化
return ans / np.std(ans - np.mean(ans))
训练数据的获取
def train(self,episodes):
for e in range(episodes):
states,actions,rewards=[],[],[]
state=self.env.reset()
for t in range(500):
action=self.predict(state)
next_state,reward,done,_=self.env.step(action)
# 更好的reward
x, x_dot, theta, theta_dot = next_state
r1 = (self.env.x_threshold - abs(x)) / self.env.x_threshold - 0.8
r2 = (self.env.theta_threshold_radians - abs(theta)) / self.env.theta_threshold_radians - 0.5
reward = r1 + r2
# 记录样本
# reward=reward if not done else -1
states.append(state)
actions.append(action)
rewards.append(reward)
state=next_state
if done:
# 进行训练
self.learn(states,actions,rewards)
以上是关于CartPole环境下的强化学习的主要内容,如果未能解决你的问题,请参考以下文章
Actor-critic强化学习方法应用于CartPole-v1
PyTorch强化学习实战——强化学习环境配置与PyTorch基础
DQN 处理 CartPole 问题——使用强化学习,本质上是训练MLP,预测每一个动作的得分