强化学习基于tensorflow2.x 的 PPO2(离散动作情况) 训练 CartPole-v1
Posted 昵称已被吞噬~‘(*@﹏@*)’~
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了强化学习基于tensorflow2.x 的 PPO2(离散动作情况) 训练 CartPole-v1相关的知识,希望对你有一定的参考价值。
算法流程

代码
import matplotlib.pyplot as plt
import tensorflow as tf
import numpy as np
import gym
import copy
def build_actor_network(state_dim, action_dim):
model = tf.keras.Sequential([
tf.keras.layers.Dense(units=128, activation='relu'),
tf.keras.layers.Dense(units=action_dim, activation='softmax')
])
model.build(input_shape=(None, state_dim))
return model
def build_critic_network(state_dim):
model = tf.keras.Sequential([
tf.keras.layers.Dense(units=128, activation='relu'),
tf.keras.layers.Dense(units=1, activation='linear')
])
model.build(input_shape=(None, state_dim))
return model
class Actor(object):
def __init__(self, state_dim, action_dim, lr):
self.action_dim = action_dim
self.old_policy = build_actor_network(state_dim, action_dim)
self.new_policy = build_actor_network(state_dim, action_dim)
self.update_policy()
self.optimizer = tf.keras.optimizers.Adam(learning_rate=lr)
def choice_action(self, state):
policy = tf.stop_gradient(self.old_policy(
np.array([state])
)).numpy()[0]
return np.random.choice(
self.action_dim,
p=policy
), policy
def update_policy(self):
self.old_policy.set_weights(
self.new_policy.get_weights()
)
def learn(self, batch_state, batch_action, batch_policy, advantage, epsilon=0.2):
advantage = np.reshape(advantage, newshape=(-1))
batch_action = np.array([[1 if a == i else 0 for i in range(self.action_dim)] for a in batch_action])
with tf.GradientTape() as tape:
new_policy = self.new_policy(batch_state)
ratio = tf.reduce_sum((new_policy / batch_policy) * batch_action, axis=-1)
surr1 = ratio * advantage
surr2 = tf.clip_by_value(ratio, clip_value_min=1.0 - epsilon, clip_value_max=1.0 + epsilon) * advantage
loss = - tf.reduce_mean(tf.minimum(surr1, surr2))
grad = tape.gradient(loss, self.new_policy.trainable_variables)
self.optimizer.apply_gradients(zip(grad, self.new_policy.trainable_variables))
class Critic(object):
def __init__(self, state_dim, lr):
self.value = build_critic_network(state_dim)
self.optimizer = tf.keras.optimizers.Adam(learning_rate=lr)
def learn(self, batch_state, batch_raward):
with tf.GradientTape() as tape:
value_predict = self.value(batch_state)
loss = tf.keras.losses.mean_squared_error(batch_raward, value_predict)
grad = tape.gradient(loss, self.value.trainable_variables)
self.optimizer.apply_gradients(zip(grad, self.value.trainable_variables))
advantage = tf.stop_gradient(batch_raward - value_predict).numpy()
return advantage
if __name__ == '__main__':
episodes = 200
env = gym.make("CartPole-v1")
A_learning_rate = 1e-3
C_learning_rate = 1e-3
actor = Actor(4, 2, A_learning_rate)
critic = Critic(4, C_learning_rate)
gamma = 1.0
K_epoch = 10
assert K_epoch > 1, "K_epoch必须大于1,不然计算的重要性采样没有意义"
plot_score = []
for e in range(episodes):
state = env.reset()
S, A, R, P = [], [], [], []
score = 0.0
while True:
# env.render()
action, policy = actor.choice_action(state)
next_state, reward, done, _ = env.step(action)
score += reward
S.append(state)
A.append(action)
R.append(reward)
P.append(policy)
state = copy.deepcopy(next_state)
if done:
discounted_r = []
tmp_r = 0.0
for r in R[::-1]:
tmp_r = r + gamma * tmp_r
discounted_r.append(np.array([tmp_r]))
discounted_r.reverse()
bs = np.array(S, dtype=np.float)
ba = np.array(A)
br = np.array(discounted_r, dtype=np.float)
bp = np.array(P, dtype=np.float)
advantage = critic.learn(bs, br)
for k in range(K_epoch):
actor.learn(bs, ba, bp, advantage)
actor.update_policy()
print("episode: /, score: ".format(e + 1, episodes, score))
break
plot_score.append(score)
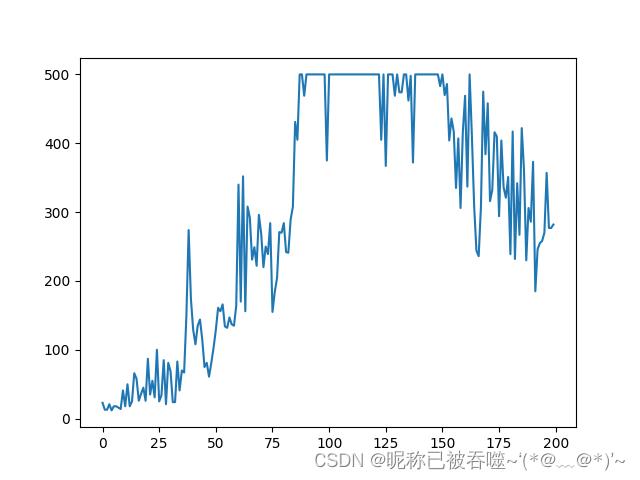
plt.plot(plot_score)
plt.show()
训练200轮奖励(reward)变化
以上是关于强化学习基于tensorflow2.x 的 PPO2(离散动作情况) 训练 CartPole-v1的主要内容,如果未能解决你的问题,请参考以下文章