3.经典语义分割网络U-Net论文解读
Posted 恒友成
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了3.经典语义分割网络U-Net论文解读相关的知识,希望对你有一定的参考价值。
欢迎访问个人网络日志🌹🌹知行空间🌹🌹
文章目录
1.基础介绍
论文:U-Net: Convolutional Networks for Biomedical Image Segmentation
工程:https://lmb.informatik.uni-freiburg.de/people/ronneber/u-net/
这是德国弗赖堡大学2015年05月份发表的论文,最早接触U-Net是2017年的时候,现在再回过头来看下这些经典全卷积语义分割网络。截至2023年03月份,这篇文章的引用已经达到了57800多次,从这里可以看出这篇文章在语义分割方向的地位,也能看出AI+CV的热度之高。
U-Net网络的提出是为了对医学领域细胞电镜的图像进行分割,这个任务特殊之处在于医学图像获取比较困难,因此只能从小样本数据中学习。作者通过对训练数据进行增强来学习,医学细胞图像多样性没有那么多,但更多的是旋转,尺度,形变和亮度这些。作者提出的端到端训练的全卷积网络包括特征提取的压缩路径和上采样的扩展路径,比较早的采用了这种编解码结构的模型。医学图像中特殊的地方还有一处就是,细胞虽然属于同个类别,但不是同个细胞时还需要把细胞间的间隔背景给识别出来,为此作者提出了一种加权的损失函数,增大了间隔背景的损失权重,更利于模型的学习。
总结这篇文章的主要工作有以下几点:
- 包含压缩路径和扩展路径的编解码结构的全卷积分割模型,实现了端到端训练
- 提出了一种加权损失函数,更利于学习个体之间的间隔背景
- 基于数据增强的小样本学习及一种利于边缘像素预测的
Overlap-tile strategy
2.Overlap-tile strategy
为了避免在分割的边沿产生了类似于padding的黑边,文中作者提出了Overlap-tile strategy,原理就是沿着边沿取图像的一部分,然后将其沿着边镜像,通过这中方式将原图的size进行扩大,避免在训练时对图像原图的边沿进行填充。
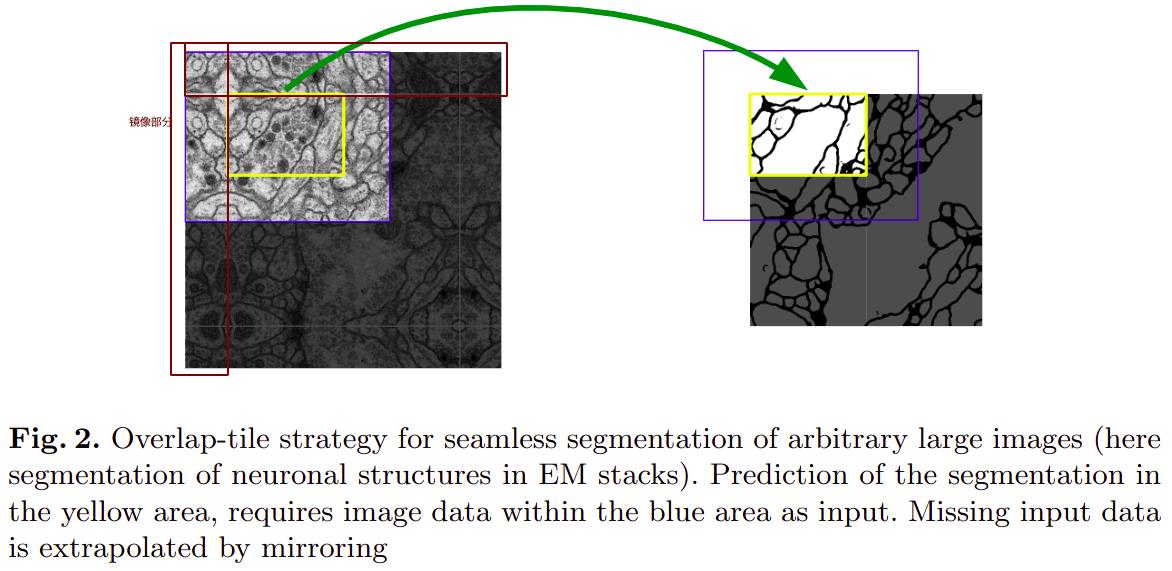
如上图,原来输入图的大小是388,左右上下取原图像上92像素镜像扩展得到输入图像的大小为572。
3.网络模型
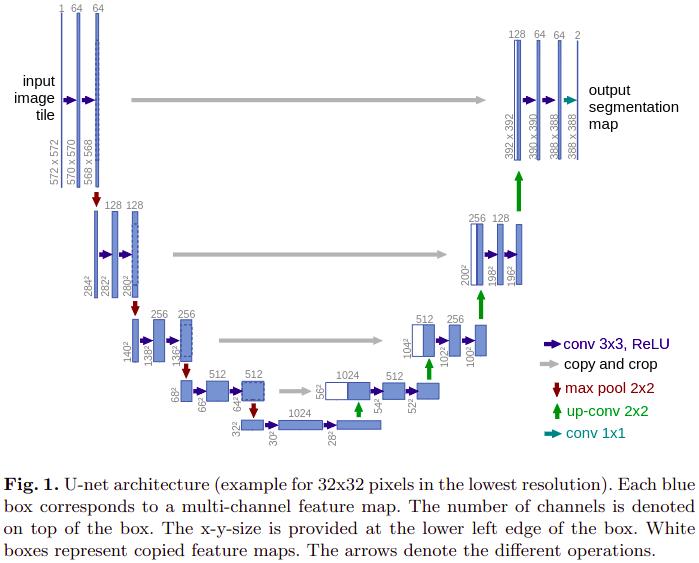
与之前介绍的FCN中不同,这里特征融合使用的是,低层特征图和高层特征图直接在通道方向上concatenate后得到。
压缩路径,2个uppadded的3x3卷积层, 后跟ReLU和2x2的stride=2的最大值池化层
每下采样一次,卷积的通道数翻倍
扩展路径,2x2的转置卷积,2倍上采样,通道数减半,与压缩路径中对应大小的feature map concatenate,再使用两个conv3卷积层使通道数减半,最后使用1x1的卷积在通道上输出每个像素位置所属类别的结果。
论文中,只需要分割出是否是细胞,因此最后卷积输出的通道数即类别数是2.
4.损失函数
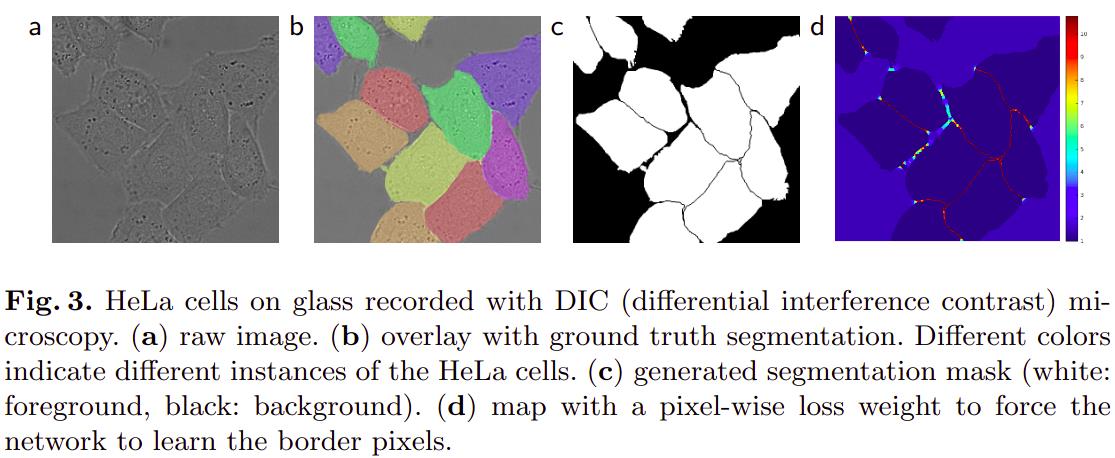
如上图中 b , c b,c b,c,细胞之间的间隙背景非常小,但又非常重要,如果不采取特殊的方式,小部分的背景将很难分割出来,为此,作者提出了加权损失函数。
最后一层卷积的输出在通道方向上使用SOFTMAX函数可以得到类别概率图,
p k ( x ) = e x p ( a k ( x ) ) ∑ k ′ K e x p ( a k ′ ( x ) ) p_k(x) = \\fracexp(a_k(x))\\sum\\limits_k'^Kexp(a_k'(x)) pk(x)=k′∑Kexp(ak′(x))exp(ak(x))
a k ( x ) a_k(x) ak(x)表示在卷积特征图位置$x\\in\\Omega 通道 通道 通道k 上经过激活函数后的输出。 上经过激活函数后的输出。 上经过激活函数后的输出。\\Omega \\subset \\mathbbZ^2 , 其中 ,其中 ,其中\\mathbbZ 表示自然数。 表示自然数。 表示自然数。K 是总的类别数。 是总的类别数。 是总的类别数。p_k(x) 表示的是 s o f t m a x 后类别为 表示的是softmax后类别为 表示的是softmax后类别为k$的概率。
交叉熵损失函数的定义:
E = ∑ x ∈ Ω w ( x ) l o g ( p l ( x ) ( x ) ) E = \\sum\\limits_x\\in\\Omegaw(x)log(p_\\mathscrl(x)(x)) E=x∈Ω∑w(x)log(pl(x)(x))
l : Ω ⟶ 1 , . . , K \\mathscrl:\\Omega\\longrightarrow \\1,..,K\\ l:Ω⟶1,..,K是每个像素的真实标签, w ∈ Ω → R w\\in \\Omega\\rightarrow\\mathbbR w∈Ω→R是权重图,为了指定某些像素在训练时更重要,这里是细胞间隔背景。这个权重图是根据标签分割图生成的。
w ( x ) = w c ( x ) + w 0 ⋅ e x p ( − ( d 1 ( x ) + d 2 ( x ) ) 2 2 σ 2 ) w(x) = w_c(x) + w_0\\cdot exp(-\\frac(d_1(x)+d_2(x))^22\\sigma^2) w(x)=wc(x)+w0⋅exp(−2σ2(d1(x)+d2(x))2)
w c : Ω → R w_c:\\Omega\\rightarrow \\mathbbR wc:Ω→R表示 w c w_c wc是与标签分割图大小相同的实数权重图。 d 1 : Ω → R d_1:\\Omega\\rightarrow \\mathbbR d1:Ω→R表示当前位置距离最近细胞边沿的像素距离, d 2 : Ω → R d_2:\\Omega\\rightarrow \\mathbbR d2:Ω→R表示当前位置距离次最近细胞边沿的像素距离,在论文中 w 0 = 10 , σ ≈ 5 w_0=10,\\sigma\\approx 5 w0=10,σ≈5。
获取权重图的一个pytorch实现的代码示例如下:
class CellDataset(Dataset):
...
def _get_boundary_weight(self, target, w0=10, sigma=5):
"""This implementation is very computationally intensive!
about 30 minutes per 512x512 image
"""
print('Calculating boundary weight...')
n, H, W = target.shape
weight = torch.zeros(n, H, W)
ix, iy = np.meshgrid(np.arange(H), np.arange(W))
ix, iy = np.c_[ix.ravel(), iy.ravel()].T
for i, t in enumerate(tqdm(target)):
boundary = find_boundaries(t, mode='inner')
bound_x, bound_y = np.where(boundary is True)
# broadcast boundary x pixel
dx = (ix.reshape(1, -1) - bound_x.reshape(-1, 1)) ** 2
dy = (iy.reshape(1, -1) - bound_y.reshape(-1, 1)) ** 2
d = dx + dy
# distance to 2 closest cells
d2 = np.sqrt(np.partition(d, 2, axis=0)[:2, ])
dsum = d2.sum(0).reshape(H, W)
weight[i] = torch.Tensor(w0 * np.exp(-dsum**2 / (2 * sigma**2)))
return
代码引用自2
欢迎访问个人网络日志🌹🌹知行空间🌹🌹
参考资料
引用量超1400的经典语义分割方法BiSeNet解读
今天给大家分享语义分割领域非常经典的一篇论文:BiSeNet,该论文发表在了ECCV2018上,引用量超过1400。
开源代码地址:https://github.com/ycszen/TorchSeg

1.动机
语义分割任务,即为图片的每个像素分配一个标签,是计算机视觉中的一个重要任务,被广泛应用于增强现实、自动驾驶、视频监控等领域,这些领域通常需要算法具有很强的实时性。
为了满足实时性需求,通常使用以下方法提高语义分割算法运行速度:
(1)使用比较小的图片作为网络输入;
(2)使用比较小的网络。
这些方法都会使得算法的性能明显下降。作者提出了Bilateral Segmentation Network(简称BiSeNet)来兼顾运行速度和网络性能。
2.BiSeNet基本结构
BiSeNet主要分为2部分:
- Spatial Path(SP):保留丰富的空间特征。
- Context Path(CP):增加感受野,提取全局特征。
BiSeNet的总体结构如下图所示:
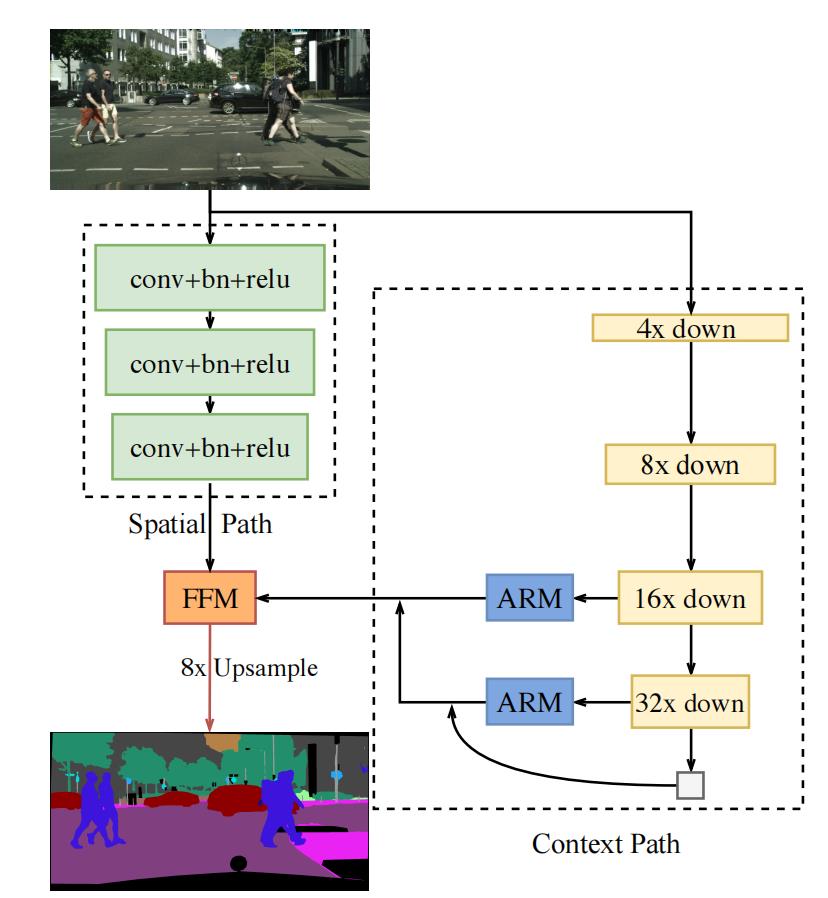
2.1 Spatial Path
Spatial Path的目的是提取图片的空间特征,保留更多的细节信息。Spatial Path包含3层,每层的结构都是Conv(stride=2)+BN+ReLU。因此,Spatial Path的输出feature map的尺寸是网络输入图片尺寸的1/8。
相比于Context Path,Spatial Path能够输出尺寸比较大的feature map,因此能保留更丰富的空间细节信息。
2.2 Context Path
Context Path能够提供比较大的感受野,因此能提取全局信息。Context Path包含1个Xception39以及global average pooling(全局平均池化)。
根据图1可以看到,在Context Path中,还有2个ARM(全称为Attention Refinement Module)模块。ARM模块的具体结构如下图所示:

在ARM内部,有1个global pool操作用于提取全局特征,global pool以及后续的卷积、BN、sigmoid会生成1个attention vector(注意力向量),用于精炼输出特征。从图2中可以看出,ARM的结构比较小,因此使用ARM不会引入太大的计算负担。
2.3 使用FFM融合Spatial Path和Context Path的输出
在融合Spatial Path和Context Path的输出特征时,直接将2个特征相加不是一个很好的方法,因为两者的特征层次不一致:Sptaial Path的输出有很多空间细节信息,特征层次较低;Context Path的输出主要是全局特征,特征层次较高。
为了融合这2个feature map,作者设计了Feature Fusion Module(简称FFM),FFM的结构如下图所示:
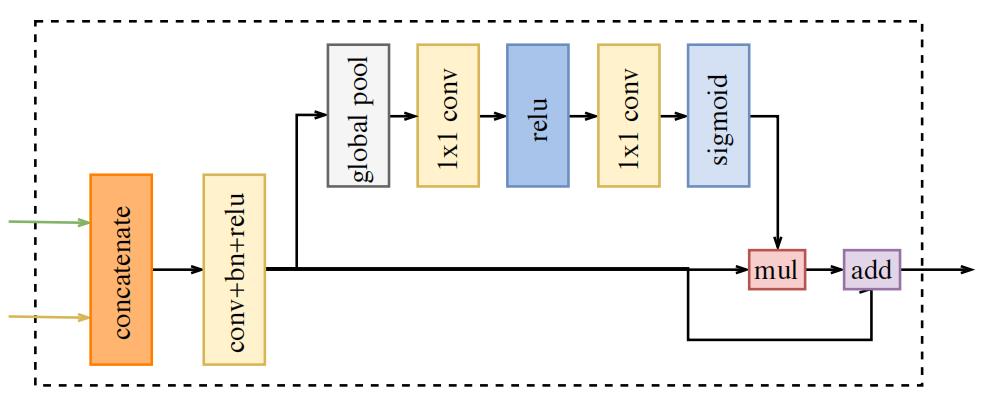
从上图中可以看出,FFM先对Spatial Path和Context Path的输出特征进行concat操作,然后使用Conv+BN+ReLU对特征进行平滑。作者借鉴SENet的思路,紧接着使用了global pool以及后面的一系列操作,计算vector,用于特征选择和融合。
2.4 BiSeNet的优势
BiSeNet有较小的计算量 尽管Spatial Path中的feature map尺寸较大,但是它只有3个卷积层,因此计算量较小;而Context Path使用的是轻量级的Xception结构,且feature map尺寸较小,也不会引入较大的计算量。
BiSeNet有较好的性能 Spatial Path提取空间信息,Context Path提取全局信息,两个结构特性互补,因此BiSeNet有较好的性能。
3.损失函数
在训练BiSeNet时,作者使用了2个辅助损失函数去监督Context Path的输出,使用主损失函数监督整个BiSeNet的输出。
这3个损失函数都是交叉熵损失,公式如下:
l o s s = 1 N ∑ i L i = 1 N ∑ i − log ( e p i ∑ j e p j ) l o s s=\\frac1N \\sum_i L_i=\\frac1N \\sum_i-\\log \\left(\\frace^p_i\\sum_j e^p_j\\right) loss=N1∑iLi=N1∑i−log(∑jepjepi)
使用参数 α \\alpha α平衡主损失和辅助损失,总损失函数如下:
L ( X ; W ) = l p ( X ; W ) + α ∑ i = 2 K l i ( X i ; W ) L(X ; W)=l_p(X ; W)+\\alpha \\sum_i=2^K l_i\\left(X_i ; W\\right) L(X;W)=lp(X;W)+α∑i=2Kli(Xi;W)
上式中, l p l_p lp是主损失, X X X表示BiSeNet的输出结果; l i l_i li是辅助损失, X i X_i Xi是Xception结构的中间特征,这里取 K = 3 K=3 K=3; L L L是总损失。
4.实验结果
4.1 训练
如图1所示,BiSeNet的最终输出的尺寸是输入图片的1/8。
超参数设置 使用SGD优化器,batch size设置为16,momentum为0.9,weight decay为 1 e − 4 1e^-4 1e−4,初始学习率为 2.5 e − 2 2.5e^-2 2.5e−2。使用poly学习率衰减策略,每次迭代的学习率是初始学习率乘以 ( 1 − iter max_iter ) power \\left(1-\\frac\\text iter \\text max\\_iter \\right)^\\text power (1− max_iter iter )power ,power的值为0.9。
数据增强 在训练时使用了随机翻转、随机缩放和随机裁剪,裁剪的结果是固定尺寸图片,将其输入网络用于训练。
4.2 结果
在Cityscapes数据集上的一些可视化的结果如下图所示,图中的(b)、(c)、(d)分别表示在Context Path中使用ResNet18、Xception39和ResNet101这3种结构。

BiSeNet与其他网络的速度、精度比较分别如下面2个图所示:


关于实验设置细节、消融实验的详细内容,请参考原文。
-
如果你对计算机视觉领域的目标检测、跟踪、分割、轻量化神经网络、Transformer、3D视觉感知、人体姿态估计兴趣,欢迎关注公众号【CV51】一起学习交流~
-
欢迎关注我的个人主页,这里沉淀了计算机视觉多个领域的知识:https://www.yuque.com/cv_51
以上是关于3.经典语义分割网络U-Net论文解读的主要内容,如果未能解决你的问题,请参考以下文章
使用 TensorRT 部署语义分割网络(U-Net)(不支持上采样)