CVPR2020论文解读:手绘草图卷积网络语义分割
Posted wujianming-110117
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了CVPR2020论文解读:手绘草图卷积网络语义分割相关的知识,希望对你有一定的参考价值。
CVPR2020论文解读:手绘草图卷积网络语义分割
Sketch GCN: Semantic Sketch Segmentation with Graph Convolutional Networks

论文链接:https://arxiv.org/pdf/2003.00678.pdf
摘要
介绍了一种用于手绘草图语义分割和标注的图形卷积神经网络SketchGCN。我们将输入草图视为二维点集,并将笔划结构信息编码为图形节点/边缘表示。为了预测每个点的标签,我们的SketchGCN使用图卷积和全局分支网络结构来提取笔划内和笔划间的特征。SketchGCN显著提高了语义草图分割的最新方法的准确性(在基于像素的度量中提高了11.4%,在基于组件的度量中提高了18.2%,在大规模具有挑战性的SPG数据集上),并且比基于图像和基于序列的方法具有更少的参数。
1. Introduction
随着数字触摸设备(如智能手机、平板电脑)和各种基于草图的界面的不断迭代,手绘草图正成为人与机器之间常见的交互手段之一。然而,由于用户草图中固有的模糊性和稀疏性,草图的解释对于计算机来说仍然是困难的,因为草图通常是以不同的抽象层次、艺术形式和绘图风格创建的。虽然许多以前的工作试图解释整个草图(例如,用于草图分类和基于草图的检索[6,7,39,27]),但在多个草图应用中,部件级草图分析越来越需要,包括草图标题[28]、草图生成[24,31]、基于草图的三维建模[38],以及三维草图重建[18]。在本文中,我们主要关注草图对象的语义分割和标记,这是内部草图分析的一个基本任务。
我们提出了一个双分支网络:一个使用原始稀疏结构的分支,另一个使用动态边缘,以平衡正确性和效率。我们的主要贡献如下:
(1) 提出了第一种基于GCN的草图对象语义分割和标注方法;
(2) 与基于图像的方法和基于序列的方法相比,我们的方法显著地提高了最新技术的准确性,并且具有更少的参数。
2. Related Work
Sketch Grouping.
草图分组将笔划划分为多个簇,每个簇对应于一个对象零件。
Semantic Sketch Segmentation.
语义草图分割方法将数据标记成语义组。
Graph Convolutional Networks.
图卷积网络(GCNs)在许多应用中得到了应用,例如处理社交网络[32]、推荐引擎[20,40]和自然语言处理[1]。GCN也适用于处理二维和三维点云数据。
为了更好地捕捉全局和局部特征,我们将采用两分支网络,并使用静态和动态图形卷积。最近,李等人 [14] 利用残余连接、稠密连接和扩张卷积来解决GCN中的梯度消失和过光滑问题[19,13,37]。我们的方法在构建多层gcn时也利用了类似的思想。
3. Overview
图1显示了我们网络的管道。给定一个输入草图,我们首先从基本笔划结构构造一个图形,并使用信息中的绝对坐标作为图形节点的特征(第4.1节)。然后将图和节点特征输入两个分支(第4.2节):局部分支由多个静态图卷积单元组成;全局分支由动态图卷积单元和混合池块(第4.3节)组成,包括最大池操作和笔划池操作。将两个分支的学习特征串接到多层感知器(MLP)中进行最终的分割和标记。两个分支结构根据草图结构的独特性进行裁剪,学习草图的笔划内特征和笔划间特征。在局部分支中,信息只在单个笔划中流动,因为不同笔划在输入图中没有连接。与全局分支相比,我们增加了与扩张的KNN函数发现的节点的额外连接。我们使用两个池操作来聚合草图级信息和笔划级信息,以提供层次化的全局特征。在我们的实验中,使用笔划水平聚合的笔划池操作被证明对任务有很大好处(第5.3节)。
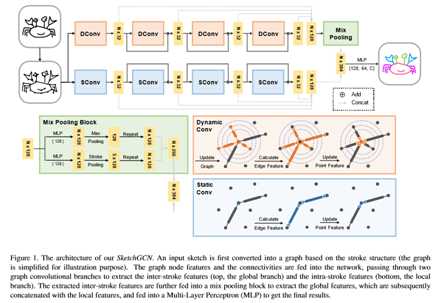
4. Methodology
在本节中,我们首先解释基于图形的草图表示作为网络的输入。然后介绍了在两个分支中分别使用的两个图卷积单元,然后描述了我们在全局分支的混合池块中的新的笔划池操作。
4.1. Input Representation
将一个素描表示为n点集P= {PI=(Xi,Yi)} I=1,2,……,n,其中席席和Yi是点PI的2D绝对坐标。
4.2. Graph Convolutional Unit
在我们的网络中,我们使用两种类型的图卷积单元:用于局部分支的静态图卷积单元(简称SConv)和用于全局分支的动态图卷积单元(简称DConv)。两个单元使用相同的图卷积运算。
Graph Convolution Operation.
我们使用与[34]中相同的图形卷积操作,为了便于阅读,brie fley在这里解释了该操作。给定第l层的图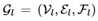
,其中Vl和El分别是图Gl中的顶点和边,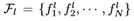
是一组节点特征,每个特征都在第l层的顶点处定义。
Graph Updating Strategy.
4.3. Mix Pooling Block
混合池块设计用于通过最大池操作学习草图级特征,并通过草图池操作学习笔划级特征。在应用两种合并操作之前,我们分别使用具有可学习权重的不同多层感知器来转换全局特征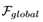
。我们使用max pooling操作来聚合草图级别的特征,类似于三维点云分析中使用的许多现有方法[2,30],

对于笔划级别的特征,我们提出了一个新的池操作,称为笔划池,来聚合每个笔划上的特征,
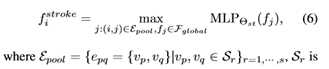
Sr是草图中的第r个笔划,s是草图中的笔划数。注:对于同一笔划内的点,笔划池产生相同的fstroke。最终MLP层中使用的全部特性是混合池块输出(即笔划级特性Fstroke和草图级特性Fsketch)和本地分支输出(即本地特性fslocal)的连接:

5. Experiments Results
如图1所示,我们的网络在本地分支和全局分支中都使用L=4的图卷积单元。每个图形卷积单元通过首先连接点特征,然后使用隐藏大小为32的多层感知器,从连接点对计算边缘特征。然后,它通过聚集相邻的边缘特征来更新点特征。在全局分支中,我们分别使用最近邻数K=8和层0到3的扩张率d=1,4,8,16的有向KNN函数找到的动态边。在混合池块中,我们在每个池操作之前应用隐藏大小为128的多层感知器。将全局特征与局部特征合并并重复后,输入隐藏大小为[128,64,C]的多层感知器,得到最终的预测结果。
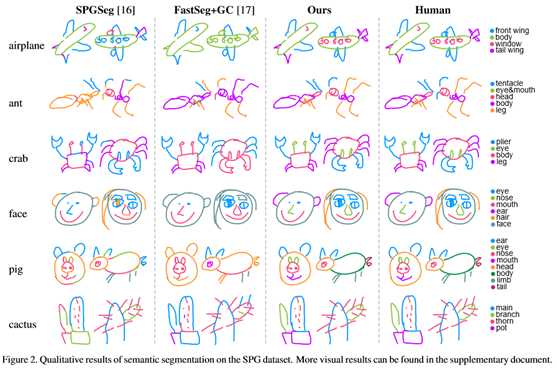
表1和表2列出了SPG和SketchSeg-150K数据集上不同方法的定量结果。我们使用与[16,36]中相同的数据分割集。我们的方法在很大程度上优于其他方法:在像素度量方面平均比FastSeg+GC[17]高11.4%,在SPG数据集上平均比FastSeg+GC[17]高18.2%,后者在现有方法中表现最好,在SketchSeg150K数据集上,像素度量平均提高3%,组件度量平均提高6%。SketchSeg-150K数据集的性能增益较小,主要是因为该数据集的标记粗糙,每个类别的语义标签较少(SketchSeg-150K中每个类别有2-4个标签,而SPG中每个类别有3-7个标签),因此对现有方法的挑战较小。
图2显示了我们的方法与[16]和[17]的方法之间的一些有代表性的视觉比较。基于序列的表示[16]使用点绘制顺序及其相对坐标,忽略了笔划之间的接近性,导致结果不令人满意(图2,第一列)。基于图像的方法[17]不知道笔划结构,因此主要依赖于局部图像结构,这也导致较差的结果。
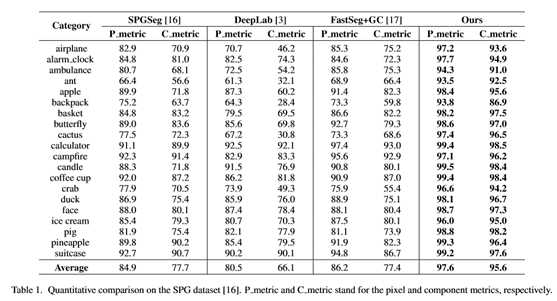
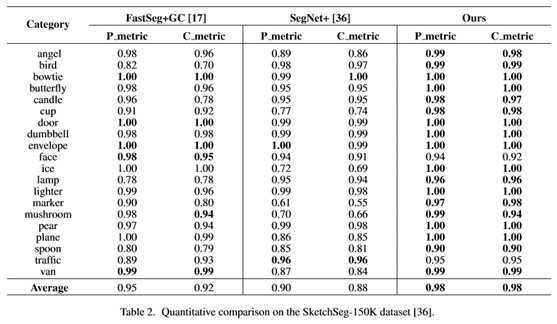
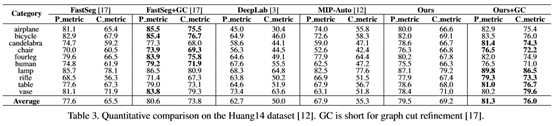
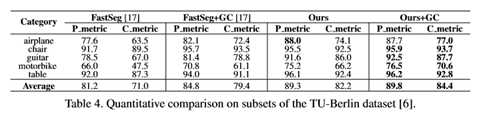
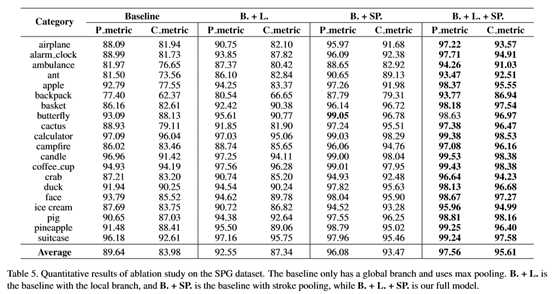
表3和表4显示了各自的定量结果。在Huang14数据集中,独立行程通常包含许多宽敞的小段(如图3,顶行)。

总的来说,我们的方法+GC在Huang14数据集上的像素度量平均提高了0.7%,分量度量平均提高了2.2%(比FastSeg+GC),在TU Berlin数据集上的像素度量平均提高了5.0%,分量度量平均提高了5.0%。
在黄14数据集上,我们的结果只是稍微好一点比基于CNN的方法FastSeg+GC[17]更糟(在某些类别中,甚至更糟,见表3)。
这主要是由于从3D模型渲染的合成数据与真实的手绘数据之间存在较大的域间隙,如图3所示。对于基于GCN的方法来说,大的域间隙可能会导致较大的结构噪声,从而完全捕获笔划结构。然而,我们的方法仍然能够达到最先进的性能。
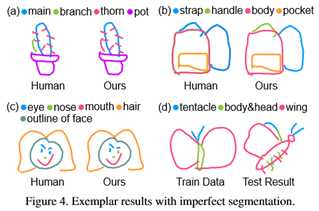
图4示出了具有分割误差的若干分割结果。我们方法的不完善主要是由两个因素引起的。首先,由于手绘草图在零件位置和形状上固有的模糊性,我们的模型可能会给笔划指定错误的标签。例如,在图4(a)中,仙人掌的树枝被错误地指定为刺,(b)袋子顶部的带子被标记为把手。其次,列车数据和测试数据之间的巨大差异也可能误导我们的模型(图4(d)):列车数据中的黄油味总是展开机翼,而本图中的测试示例中黄油味折叠其机翼,视角不同。我们认为领域差距是当前基于学习的方法的一个共同问题。然而,图2中的可视化结果以及黄14和图柏林数据集的统计数据(表3和表4)表明了我们模型的泛化能力。最后,由于我们的图形表示只扭曲节点位置和邻近度等特征,因此我们的模型不知道一些高级语义,例如“人脸只能有一个鼻子”(见图4(c))。我们相信这个问题可以通过在我们的图形表示中加入更多的语义特征而得到缓解,我们将留待以后的工作。
6. Conclusion
在这项工作中,我们提出了第一个用于语义草图分割和标记的图形卷积网络。我们的SketchGCN使用静态图形卷积单元和动态图形卷积单元,分别使用两个分支架构来提取笔划内和笔划间的特征。通过一种新的笔划池操作,使得笔划内标记更加一致,我们的方法在多个草图数据集中的参数显著减少的情况下,比最新的方法获得更高的精度。在我们目前的实验中,我们只使用绝对位置作为图形节点的特征,而忽略了笔划的顺序、方向、空间关系等信息,未来我们将以更加灵活的图形结构来开发这些信息。另一种可能是利用递归模块来学习完整的图形表示。最后,为场景级草图分割和草图识别任务重塑我们的体系结构可能是一个有趣的方向。
以上是关于CVPR2020论文解读:手绘草图卷积网络语义分割的主要内容,如果未能解决你的问题,请参考以下文章