引用量超1400的经典语义分割方法BiSeNet解读
Posted CV51
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了引用量超1400的经典语义分割方法BiSeNet解读相关的知识,希望对你有一定的参考价值。
今天给大家分享语义分割领域非常经典的一篇论文:BiSeNet,该论文发表在了ECCV2018上,引用量超过1400。
开源代码地址:https://github.com/ycszen/TorchSeg

1.动机
语义分割任务,即为图片的每个像素分配一个标签,是计算机视觉中的一个重要任务,被广泛应用于增强现实、自动驾驶、视频监控等领域,这些领域通常需要算法具有很强的实时性。
为了满足实时性需求,通常使用以下方法提高语义分割算法运行速度:
(1)使用比较小的图片作为网络输入;
(2)使用比较小的网络。
这些方法都会使得算法的性能明显下降。作者提出了Bilateral Segmentation Network(简称BiSeNet)来兼顾运行速度和网络性能。
2.BiSeNet基本结构
BiSeNet主要分为2部分:
- Spatial Path(SP):保留丰富的空间特征。
- Context Path(CP):增加感受野,提取全局特征。
BiSeNet的总体结构如下图所示:
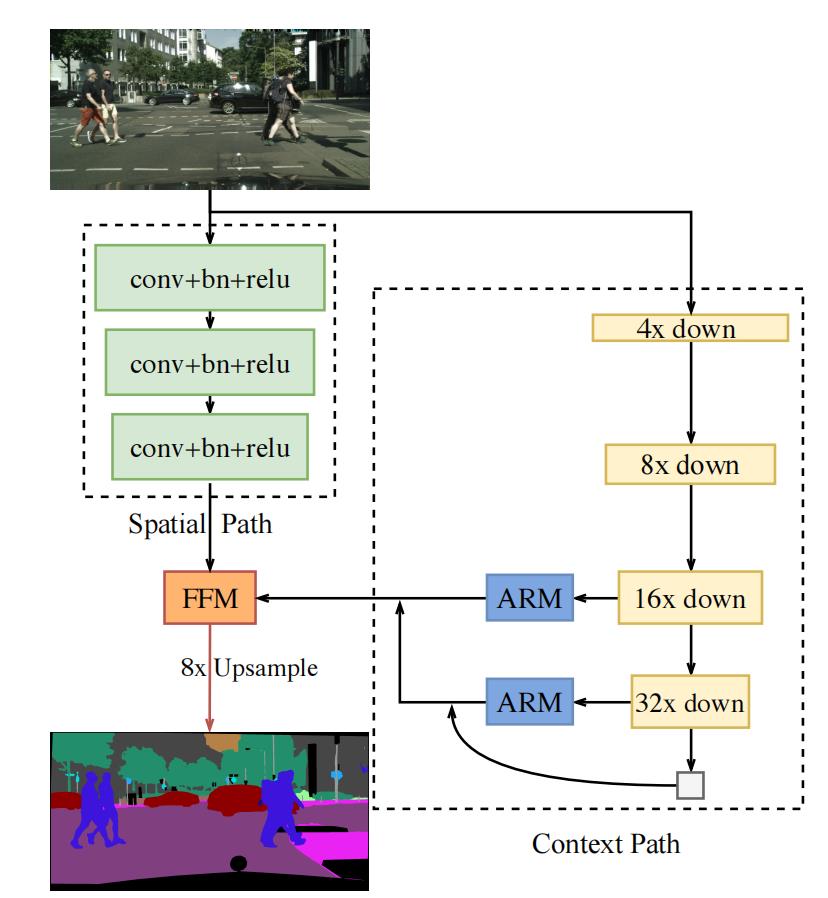
2.1 Spatial Path
Spatial Path的目的是提取图片的空间特征,保留更多的细节信息。Spatial Path包含3层,每层的结构都是Conv(stride=2)+BN+ReLU。因此,Spatial Path的输出feature map的尺寸是网络输入图片尺寸的1/8。
相比于Context Path,Spatial Path能够输出尺寸比较大的feature map,因此能保留更丰富的空间细节信息。
2.2 Context Path
Context Path能够提供比较大的感受野,因此能提取全局信息。Context Path包含1个Xception39以及global average pooling(全局平均池化)。
根据图1可以看到,在Context Path中,还有2个ARM(全称为Attention Refinement Module)模块。ARM模块的具体结构如下图所示:

在ARM内部,有1个global pool操作用于提取全局特征,global pool以及后续的卷积、BN、sigmoid会生成1个attention vector(注意力向量),用于精炼输出特征。从图2中可以看出,ARM的结构比较小,因此使用ARM不会引入太大的计算负担。
2.3 使用FFM融合Spatial Path和Context Path的输出
在融合Spatial Path和Context Path的输出特征时,直接将2个特征相加不是一个很好的方法,因为两者的特征层次不一致:Sptaial Path的输出有很多空间细节信息,特征层次较低;Context Path的输出主要是全局特征,特征层次较高。
为了融合这2个feature map,作者设计了Feature Fusion Module(简称FFM),FFM的结构如下图所示:
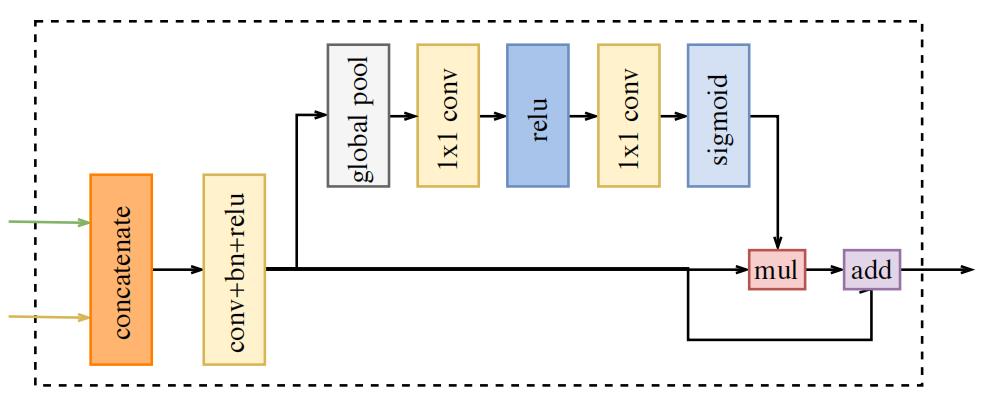
从上图中可以看出,FFM先对Spatial Path和Context Path的输出特征进行concat操作,然后使用Conv+BN+ReLU对特征进行平滑。作者借鉴SENet的思路,紧接着使用了global pool以及后面的一系列操作,计算vector,用于特征选择和融合。
2.4 BiSeNet的优势
BiSeNet有较小的计算量 尽管Spatial Path中的feature map尺寸较大,但是它只有3个卷积层,因此计算量较小;而Context Path使用的是轻量级的Xception结构,且feature map尺寸较小,也不会引入较大的计算量。
BiSeNet有较好的性能 Spatial Path提取空间信息,Context Path提取全局信息,两个结构特性互补,因此BiSeNet有较好的性能。
3.损失函数
在训练BiSeNet时,作者使用了2个辅助损失函数去监督Context Path的输出,使用主损失函数监督整个BiSeNet的输出。
这3个损失函数都是交叉熵损失,公式如下:
l o s s = 1 N ∑ i L i = 1 N ∑ i − log ( e p i ∑ j e p j ) l o s s=\\frac1N \\sum_i L_i=\\frac1N \\sum_i-\\log \\left(\\frace^p_i\\sum_j e^p_j\\right) loss=N1∑iLi=N1∑i−log(∑jepjepi)
使用参数 α \\alpha α平衡主损失和辅助损失,总损失函数如下:
L ( X ; W ) = l p ( X ; W ) + α ∑ i = 2 K l i ( X i ; W ) L(X ; W)=l_p(X ; W)+\\alpha \\sum_i=2^K l_i\\left(X_i ; W\\right) L(X;W)=lp(X;W)+α∑i=2Kli(Xi;W)
上式中, l p l_p lp是主损失, X X X表示BiSeNet的输出结果; l i l_i li是辅助损失, X i X_i Xi是Xception结构的中间特征,这里取 K = 3 K=3 K=3; L L L是总损失。
4.实验结果
4.1 训练
如图1所示,BiSeNet的最终输出的尺寸是输入图片的1/8。
超参数设置 使用SGD优化器,batch size设置为16,momentum为0.9,weight decay为 1 e − 4 1e^-4 1e−4,初始学习率为 2.5 e − 2 2.5e^-2 2.5e−2。使用poly学习率衰减策略,每次迭代的学习率是初始学习率乘以 ( 1 − iter max_iter ) power \\left(1-\\frac\\text iter \\text max\\_iter \\right)^\\text power (1− max_iter iter )power ,power的值为0.9。
数据增强 在训练时使用了随机翻转、随机缩放和随机裁剪,裁剪的结果是固定尺寸图片,将其输入网络用于训练。
4.2 结果
在Cityscapes数据集上的一些可视化的结果如下图所示,图中的(b)、(c)、(d)分别表示在Context Path中使用ResNet18、Xception39和ResNet101这3种结构。

BiSeNet与其他网络的速度、精度比较分别如下面2个图所示:


关于实验设置细节、消融实验的详细内容,请参考原文。
-
如果你对计算机视觉领域的目标检测、跟踪、分割、轻量化神经网络、Transformer、3D视觉感知、人体姿态估计兴趣,欢迎关注公众号【CV51】一起学习交流~
-
欢迎关注我的个人主页,这里沉淀了计算机视觉多个领域的知识:https://www.yuque.com/cv_51
以上是关于引用量超1400的经典语义分割方法BiSeNet解读的主要内容,如果未能解决你的问题,请参考以下文章