数据仓库工具——Hive表操作
Posted 小企鹅推雪球!
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据仓库工具——Hive表操作相关的知识,希望对你有一定的参考价值。
文章目录
Hive——DDL基础
- DDL(data definition language): 主要的命令有CREATE、ALTER、DROP等。
- DDL主要是用在定义、修改数据库对象的结构 或 数据类型。
- 数据库结构:
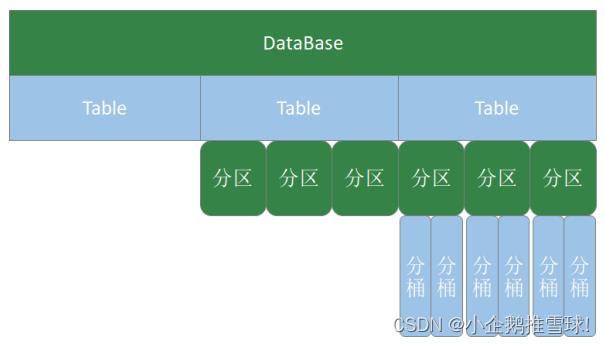
- Hive有一个默认的数据库default,在操作HQL时,如果不明确的指定要使用哪个库,则使用默认数据库;
- Hive的数据库名、表名均不区分大小写,但是名字不能使用数字开头,不能使用关键字,尽量不适用特殊符号。
Hive——DDL操作
-
Hive创建数据库语法:
CREATE (DATABASE|SCHEMA) [IF NOT EXISTS] database_name [COMMENT database_comment] [LOCATION hdfs_path] [MANAGEDLOCATION hdfs_path] [WITH DBPROPERTIES (property_name=property_value, ...)]; -
Hive创建数据库样例
-- 创建数据库,在HDFS上存储路径为 /user/hive/warehouse/*.db hive (default)> create database mydb; hive (default)> dfs -ls /user/hive/warehouse; -- 避免数据库已经存在时报错,使用 if not exists 进行判断【标准写法】 hive (default)> create database if not exists mydb; -- 创建数据库。添加备注,指定数据库在存放位置 hive (default)> create database if not exists mydb2 comment 'this is mydb2' location '/user/hive/mydb2.db'; -
数据库操作
-- 查看所有数据库 show database; -- 查看数据库信息 desc database mydb2; desc database extended mydb2; describe database extended mydb2; -- 使用数据库 use mydb; -- 删除一个空数据库 drop database databasename; -- 如果数据库不为空,使用 cascade 强制删除 drop database databasename cascade; -
Hive-建表语法
create [external] table [IF NOT EXISTS] table_name [(colName colType [comment 'comment'], ...)] [comment table_comment] [partition by (colName colType [comment col_comment], ...)] [clustered BY (colName, colName, ...) [sorted by (col_name [ASC|DESC], ...)] into num_buckets buckets] [row format row_format] [stored as file_format] [LOCATION hdfs_path] [TBLPROPERTIES (property_name=property_value, ...)] [AS select_statement]; CREATE [TEMPORARY] [EXTERNAL] TABLE [IF NOT EXISTS] [db_name.]table_name LIKE existing_table_or_view_name [LOCATION hdfs_path]; -
CREATE TABLE。按给定名称创建表,如果表已经存在则抛出异常。可使用if not
exists 规避。 -
EXTERNAL关键字。创建外部表,否则创建的是内部表(管理表)。
- 删除内部表时,数据和表的定义同时被删除;
- 删除外部表时,仅仅删除了表的定义,数据保留;
- 在生产环境中,多使用外部表;
-
comment。表的注释
-
partition by。对表中数据进行分区,指定表的分区字段
-
clustered by。创建分桶表,指定分桶字段
-
sorted by。对桶中的一个或多个列排序,较少使用
-
Hive存储子句:建表时可指定 SerDe 。如果没有指定 ROW FORMAT 或者 ROW FORMAT DELIMITED,将会使用默认的 SerDe。建表时还需要为表指定列,在指定列的同时也会指定自定义的 SerDe。Hive通过 SerDe 确定表的具体的列的数据。
ROW FORMAT DELIMITED [FIELDS TERMINATED BY char] [COLLECTION ITEMS TERMINATED BY char] [MAP KEYS TERMINATED BY char] [LINES TERMINATED BY char] | SERDE serde_name [WITH SERDEPROPERTIES (property_name=property_value, property_name=property_value, ...)] -
SerDe是 Serialize/Deserilize 的简称, hive使用Serde进行行对象的序列与反序列化。
-
stored as SEQUENCEFILE|TEXTFILE|RCFILE。如果文件数据是纯文本,可以使用 STORED AS TEXTFILE(缺省);如果数据需要压缩,使用 STORED AS SEQUENCEFILE(二进制序列文件)
-
LOCATION。表在HDFS上的存放位置
-
TBLPROPERTIES。定义表的属性
-
AS。后面可以接查询语句,表示根据后面的查询结果创建表
-
LIKE。like 表名,允许用户复制现有的表结构,但是不复制数据
Hive内部表 & 外部表
-
在创建表的时候,可指定表的类型。表有两种类型,分别是内部表(管理表)、外部表。
-
默认情况下,创建内部表。如果要创建外部表,需要使用关键字 external
-
在删除内部表时,表的定义(元数据) 和 数据 同时被删除
-
在删除外部表时,仅删除表的定义,数据被保留
-
在生产环境中,多使用外部表
-
创建表 SQL——创建内部表
-- 创建内部表 create table t1( id int, name string, hobby array<string>, addr map<string, string> ) row format delimited fields terminated by ";" collection items terminated by "," map keys terminated by ":"; -- 显示表的定义,显示的信息较少 desc t1; -- 显示表的定义,显示的信息多,格式友好 desc formatted t1; -- 加载数据 load data local inpath '/home/hadoop/data/t1.dat' into table t1; -- 查询数据 select * from t1; -- 查询数据文件 dfs -ls /user/hive/warehouse/mydb.db/t1; -- 删除表。表和数据同时被删除 drop table t1; -- 再次查询数据文件,已经被删除 -
创建表 SQL——创建外部表
-- 创建外部表 create external table t2( id int, name string, hobby array<string>, addr map<string, string> ) row format delimited fields terminated by ";" collection items terminated by "," map keys terminated by ":"; -- 显示表的定义 desc formatted t2; -- 加载数据 load data local inpath '/home/hadoop/data/t1.dat' into table t2; -- 查询数据 select * from t2; -- 删除表。表删除了,目录仍然存在 drop table t2; -- 再次查询数据文件,仍然存在
Hive 内部表与外部表的转换
-- 创建内部表,加载数据,并检查数据文件和表的定义
create table t1(
id int,
name string,
hobby array<string>,
addr map<string, string>
)
row format delimited
fields terminated by ";"
collection items terminated by ","
map keys terminated by ":";
load data local inpath '/home/hadoop/data/t1.dat' into table t1;
dfs -ls /user/hive/warehouse/mydb.db/t1;
desc formatted t1;
-- 内部表转外部表
alter table t1 set tblproperties('EXTERNAL'='TRUE');
-- 查询表信息,是否转换成功
desc formatted t1;
-- 外部表转内部表。EXTERNAL 大写,false 不区分大小
alter table t1 set tblproperties('EXTERNAL'='FALSE');
-- 查询表信息,是否转换成功
desc formatted t1;
- 建表时:如果不指定external关键字,创建的是内部表;指定external关键字,创建的是外部表;
- 删表时:删除外部表时,仅删除表的定义,表的数据不受影响,删除内部表时,表的数据和定义同时被删除
- 外部表的使用场景:想保留数据时使用。生产多用外部表
以上是关于数据仓库工具——Hive表操作的主要内容,如果未能解决你的问题,请参考以下文章