数据仓库Hive
Posted 一杯敬朝阳一杯敬月光
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据仓库Hive相关的知识,希望对你有一定的参考价值。
目录
Hive概述
产生背景
- MapReduce编程的不便性
- 传统RDBMS人员的需求
- HDFS上的文件并没有schema的概念
Hive是什么
- 由Facebook开源,用于解决海量结构化日志的数据统计问题
- 构建在Hadoop之上的数据仓库(可以理解为数据存在在HDFS,可以通过MapReduce进行计算,提交在YARN上运行的)
- Hive提供的SQL查询语言:HQL
- 底层支持多种不同的执行引擎(MR/Tez/Spark,Hive构建在Hadoop之上,底层应该是MapReduce的执行引擎,MapReduce适合离线处理,执行效率不是很高, Hive从诞生之初到1.x都是支持MapReduce的,Hive2.x开始底层的默认执行引擎是Spark)
为什么要使用Hive
- 简单、容易上手
- 为超大数据集设计的计算/扩展能力
- 统一的元数据管理
- Hive数据存放在HDFS上
- 元数据信息(记录数据的数据,例如一个表,表的名字、字段、字段的类型、数据存放在HDFS的啥位置)是存放在mysql中
- SQL on Hadoop:Hive、Spark SQL、impala...,即在Hive里面创建一张表,在Spark SQL和impala可以直接使用,反之亦然,元数据管理是单独抽取的部分,后续想更换框架会很方便
Hive在Hadoop生态圈中的位置

Hive体系架构
把SQL翻译成MapReduce,跑在Hadoop之上,在使用查询和管理的过程中可能会涉及到一些表一些数据库,因为Hive是基于表来操作的,这些表和数据库都是作为元数据信息存放在Metastore里面的,这个Metastore是存放在MySQL里面的。
- client:
- shell
- thrift/jdbc(server/jdbc的方式,一种协议,相当于把hive启成一种服务,通过jdbc的方式往这个服务上提交查询或SQL)
- WebUI(HUE/Zeppelin),提供Web界面,在Web界面上直接写SQL,统计结果可以以图形化的方式直接展示出来
- metastore ==> MySQL
- database:name、location、owner....
- table:name、location、owner、column name / type、....
- Driver
- SQL语句是一个普通的字符串而已,如何让这个字符串被Hive识别?先将SQL编译成一个语法树(SQL Parser),基于这个语法树可以做很多的优化(Query Optimizer),取出最优的执行计划生成物理执行计划(Physical Plan),在物理执行计划过程中,可能有一些序列化与反序列化以及UDF(UDF:用户自己定义的一些函数),物理执行计划会生成一个Execution,在Execution下面会生成MapReduce作业。

Hive部署架构
Hive是一个客户端,不涉及集群的概念,需要在哪个机器上使用Hive操作,直接在哪台机器上布上 Hive的软件包就行了
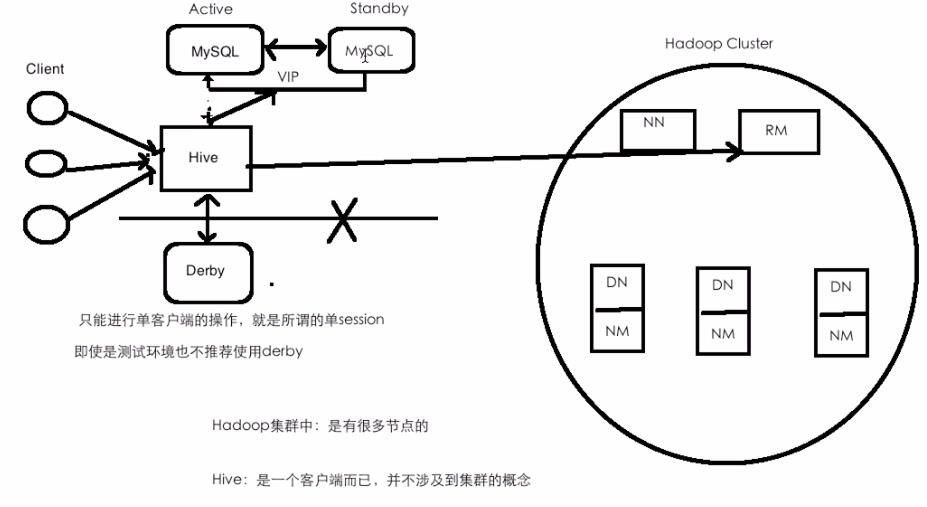
Hive和RDBMS的区别
- 支持的
- 都支持SQL
- 都支持insert和update,只不过大数据不太建议insert和update,因为性能比较低
- 都支持分布式(集群),不过MySQL的集群比较小,而且是构建在专用的机器上的,成本昂贵;Hive是基于Hadoop之上的,Hadoop可以拥有成千上万个节点,且是构建在廉价的机器之上的。
- 区别的
- Hive HQL 和关系型数据库的SQL非常类似,但他们有本质区别,他俩只是长得像,并没有关系
- 对于查询而言,关系型数据库延时较低,时效性高;Hive 基于Hadoop之上的,作业要通过SQL转换成MapReduce作业或者Spark作业,然后提交到集群上运行,跑出结果可能要很久
- MySQL处理PB级数据已经很厉害了,但是对于Hive来说PB不算大。
Hive部署
我用的是mac,下载hive-1.1.0-cdh5.15.1.tar.gz,因为之前Hadoop选择的版本是hadoop-2.6.0-cdh5.15.1,所以hive也必须选择cdh5.15.1,这边的mysql下载的是5.6.40,mysql直接下载的dmg格式,直接一路点点点。
- 下载 & 解压
- 添加HIVE_HOME到系统的环境变量,在source一下,打开的多个控制台都要source一下,否则在以前打开的控制台上不生效
- 修改配置
-
hive-env.sh
-
HADOOP_HOME:若添加到系统环境变量,通常不需要配,不过配一下也没事
-
-
hive-site.xml
-
需要配置元数据存储的地方,所以这边只需要配置一些MySQL的信息
-
-
-
拷贝MySQL驱动包到$HIVE_HOME/lib下
-
前提是要准备安装一个MySQL数据库,yum install 去安装一个MySQL数据库
hive-site.xml的配置
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<!-- hadoop所在服务器的别名,3306mysql的端口 -->
<value>jdbc:mysql://hadoop000:3306/hadoop_hive?createDatabaseIfNotExist=true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value> <!-- 驱动 -->
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value> <!-- mysql用户名 -->
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value> <!-- mysql用户名对应的密码 -->
</property>
</configuration>
HIve DDL
数据库操作
DDL:Hive Data Definition Language【create、delete、alter...】
Hive数据抽象/结构:
- database HDFS一个目录
- table HDFS一个目录
- data HDFS一个文件
- partition 分区表 HDFS一个目录
- data HDFS一个文件
- bucket 分桶 HDFS一个文件
- table HDFS一个目录
HiveQL DDL statements are documented here, including:
- CREATE DATABASE/SCHEMA, TABLE, VIEW, FUNCTION, INDEX
- DROP DATABASE/SCHEMA, TABLE, VIEW, INDEX
- TRUNCATE TABLE
- ALTER DATABASE/SCHEMA, TABLE, VIEW
- MSCK REPAIR TABLE (or ALTER TABLE RECOVER PARTITIONS)
- SHOW DATABASES/SCHEMAS, TABLES, TBLPROPERTIES, VIEWS, PARTITIONS, FUNCTIONS, INDEX[ES], COLUMNS, CREATE TABLE
- DESCRIBE DATABASE/SCHEMA, table_name, view_name, materialized_view_name
PARTITION statements are usually options of TABLE statements, except for SHOW PARTITIONS.
命令:create database
[]:中括号里面可选, |:多选一
CREATE [REMOTE] (DATABASE|SCHEMA) [IF NOT EXISTS] database_name
[COMMENT database_comment] // 加一个注释
[LOCATION hdfs_path] // hdfs上一个目录
[MANAGEDLOCATION hdfs_path]
[WITH DBPROPERTIES (property_name=property_value, ...)];CREATE DATABASE IF NOT EXISTS hive
;// 通常会加上IF NOT EXISTSCREATE DATABASE IF NOT EXISTS hive2 LOCATION '/test/location'
;// 更改路径CREATE DATABASE IF NOT EXISTS hive3
WITH DBPROPERTIES ("creator"="hh");
/user/hive/warehouse:这个是HIve默认的存储在HDFS上的路径,这个路径是可以更改的。
举个🌰
hive> show databases;
OK
default
hive
hive2
test_db
Time taken: 0.036 seconds, Fetched: 4 row(s)
在hive中一共有三个数据库,我们去MySQL上看一下哈,hadoop_hive这个数据库是我们在hive-site.xml里面配置的
mysql> use hadoop_hive;
Database changed
mysql> select * from DBS \\G;
*************************** 1. row ***************************
DB_ID: 1
DESC: Default Hive database
DB_LOCATION_URI: hdfs://localhost:8020/user/hive/warehouse
NAME: default
OWNER_NAME: public
OWNER_TYPE: ROLE
*************************** 2. row ***************************
DB_ID: 2
DESC: NULL
DB_LOCATION_URI: hdfs://localhost:8020/user/hive/warehouse/test_db.db
NAME: test_db
OWNER_NAME: dinghui
OWNER_TYPE: USER
*************************** 3. row ***************************
DB_ID: 3
DESC: NULL
DB_LOCATION_URI: hdfs://localhost:8020/user/hive/warehouse/hive.db
NAME: hive
OWNER_NAME: dinghui
OWNER_TYPE: USER
*************************** 4. row ***************************
DB_ID: 4
DESC: NULL
DB_LOCATION_URI: hdfs://localhost:8020/test/location
NAME: hive2
OWNER_NAME: dinghui
OWNER_TYPE: USER
4 rows in set (0.00 sec)
ERROR:
No query specified
我们来看看
("creator"="hh")这个的显示:desc database extended hive3;hive> desc database extended hive3;
OK
hive3 hdfs://localhost:8020/user/hive/warehouse/hive3.db hh USER {creator=hh}
Time taken: 0.034 seconds, Fetched: 1 row(s)
hive> desc database extended hive2;
OK
hive2 hdfs://localhost:8020/test/location dinghui USER
hive> desc database hive3;
OK
hive3 hdfs://localhost:8020/user/hive/warehouse/hive3.db dinghui USER
在控制台上显示现在操作的数据库
hive> set hive.cli.print.current.db;
hive.cli.print.current.db=false
hive> set hive.cli.print.current.db=true;
hive (test_db)> !clear // 清除屏幕上的显示
删除数据库
drop database test_db; // 若test_db中没有表,执行该语句会成功删掉test_db库;若里面有表,则不能,此时若还想删除,可以添加CASCADE,则无论有没有表都可以删掉该数据库,有表的话,连带表一起删除,要慎用,尤其生产环境,保险起见还是一张表一张表的删比较好。
hive (test_db)> drop database test_db;
FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.DDLTask. InvalidOperationException(message:Database test_db is not empty. One or more tables exist.)
hive (test_db)> drop database test_db CASCADE;
hive (test_db)> show databases;
default
hive
hive2
like的用法
hive (test_db)> show databases;
default
hive
hive2
hive (test_db)> show databases like "hive*";
hive
hive2
表操作
命令:
CREATE [TEMPORARY] [EXTERNAL] TABLE [IF NOT EXISTS] [db_name.]table_name -- (Note: TEMPORARY available in Hive 0.14.0and later)
[(col_name data_type [column_constraint_specification] [COMMENT col_comment], ... [constraint_specification])]
[COMMENT table_comment]
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)]
[CLUSTERED BY (col_name, col_name, ...) [SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS]
[SKEWED BY (col_name, col_name, ...) -- (Note: Available in Hive0.10.0and later)]
ON ((col_value, col_value, ...), (col_value, col_value, ...), ...)
[STORED AS DIRECTORIES]
[
[ROW FORMAT row_format]
[STORED AS file_format]
| STORED BY'storage.handler.class.name'[WITH SERDEPROPERTIES (...)] -- (Note: Available in Hive0.6.0and later)
]
[LOCATION hdfs_path]
[TBLPROPERTIES (property_name=property_value, ...)] -- (Note: Available in Hive0.6.0and later)
[AS select_statement]; -- (Note: Available in Hive0.5.0and later; not supportedforexternal tables)
创建表
CREATE TABLE emp(
empno int,
ename string,
job string,
mgr int,
hiredate string,
sal double,
comm double,
deptno int
) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\\t';
查看表结构,此处可以看到字段名、类型
hive (default)> desc emp;
显示详细信息,但是显示不够人性化,所以通常不用
desc extended emp;
通常用这条命令,现实详细信息
desc formatted emp;
将数据导入hive表
LOAD DATA LOCAL INPATH '/Users/dinghui/data/emp.txt' OVERWRITE INTO TABLE emp;
/user/hive/warehouse/emp/emp.txt
ALTER TABLE emp RENAME TO emp2;
/user/hive/warehouse/emp2/emp.txt
我们对表改名,体现在hdfs的目录上,下面的数据文件emp.txt的名字不受影响,因为表名对应其上一级的文件名。
Hive DML
DML:Data Manipulation Language
创建表
CREATE TABLE emp(
empno int,
ename string,
job string,
mgr int,
hiredate string,
sal double,
comm double,
deptno int
) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\\t';
查看表结构,此处可以看到字段名、类型
hive (default)> desc emp;
显示详细信息,但是显示不够人性化,所以通常不用
desc extended emp;
通常用这条命令,现实详细信息
desc formatted emp;
加载数据到hive
LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO TABLE tablename [PARTITION (partcol1=val1, partcol2=val2 ...)]
LOAD DATA LOCAL INPATH '/Users/dinghui/data/emp.txt' OVERWRITE INTO TABLE emp;
/user/hive/warehouse/emp/emp.txt
ALTER TABLE emp RENAME TO emp2;
/user/hive/warehouse/emp2/emp.txt
LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO TABLE tablename
[PARTITION (partcol1=val1, partcol2=val2 ...)]
LOCAL: 本地系统,若没有LOCAL就是指HDFS路径
OVERWRITE:是否数据覆盖,若没有就是数据追加
// hive下使用load data:load data inpath ‘hdfs://hadoop000:8020/data/emp.txt’ into table emp;/data目录下的emp.txt就没了
// 这个其实是一个移动的过程,把data下的移动到你的hive表的目录下面去了
LOAD DATA INPATH 'hdfs://localhost:8020/data/emp.txt' INTO TABLE emp;
LOAD DATA INPATH 'hdfs://localhost:8020/data/emp.txt' OVERWRITE INTO TABLE emp;
从下面我们可以看出,表格对应目录,表格中的内容对应目录下的文件,查询的时候table名对应目录名,和里面的文件名木有任何关系。
create table emp1 as select * from emp;
/user/hive/warehouse/emp1/000000_0
create table emp2 as select empno, ename from emp;
/user/hive/warehouse/emp2/000000_0
INSERT OVERWRITE [LOCAL] DIRECTORY directory1
[ROW FORMAT row_format] [STORED AS file_format] (Note: Only available starting with Hive 0.11.0)
SELECT ... FROM ...
// 若没有hive目录会创建,若存在hive目录,且hive目录非空,则会覆盖,即之前hive目录下的文件全部被删除
INSERT OVERWRITE LOCAL DIRECTORY '/Users/dinghui/MyTmp/hive/'
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\\t'
select empno, ename, sal, deptno from emp;
INSERT OVERWRITE LOCAL DIRECTORY '/Users/dinghui/MyTmp/'
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\\t'
select empno, ename, sal, deptno from emp;
大数据hive中不推荐使用insert插入一条数据和update更改一条数据,这种操作很耗性能,且有可能产生小文件,
若要操作,建议用NoSQL数据库
基本统计
简单查询,不需要跑mapreduce,很快就可以出结果
// between and [],左闭右闭
select * from emp where sal between 800 and 1500;
select * from emp where ename in ('SMITH', "MARTIN");
select * from emp where ename not in ('SMITH', "MARTIN");
select * from emp where comm is null;
select * from emp where comm is not null;
聚合
max/min/sum/avg,这类涉及到统计的,需要跑mapreduce,耗时比较久
select count(1) from emp where deptno=10;
select max(sal), min(sal), sum(sal), avg(sal) from emp;
分组函数
group by,这个也是要跑mapreduce
求每个部门的平均工资
出现在select中的字段如果没有出现在聚合函数里,则必须出现在group by里
select deptno, avg(sal) from emp group by deptno;
求每个部门、工作岗位的平均工资
select deptno, job, avg(sal) from emp group by deptno, job;
求每个部门平均工资大于2000的部门
对于分组函数过滤使用having
select deptno, avg(sal) from emp group by deptno having avg(sal) > 2000;
join
这个也是要跑mapreduce
create table dept(
deptno int,
dname string,
loc string
)ROW FORMAT DELIMITED FIELDS TERMINATED BY '\\t';
LOAD DATA LOCAL INPATH '/Users/dinghui/data/dept.txt' OVERWRITE INTO TABLE dept;
select
empno, ename, sal, e.deptno, dname
from emp e join dept d
on e.deptno = d.deptno;
执行计划
EXPLAIN select
empno, ename, sal, e.deptno, dname
from emp e join dept d
on e.deptno = d.deptno;
EXPLAIN extended
select
empno, ename, sal, e.deptno, dname
from emp e join dept d
on e.deptno = d.deptno;
关于外部表和内部表
外部表创建:加EXTERNAL关键字,通常我们会用location指定外部表存放位置,/external/emp/这个目录不需要我们自己手动创建。例如:
CREATE EXTERNAL TABLE emp_external(
empno int,
ename string,
) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\\t'
location '/external/emp/';
此时我们如果去mysql看元数据信息,命令select * from TBLS \\G;,会有如下关键字,TBL_TYPE: EXTERNAL_TABLE,若该字段是TBL_TYPE: MANAGED_TABLE(则是内部表)。
外部表 VS 内部表
- 若执行 drop table table_name
- 则无论外部表和内部表的元数据信息均会被删除,具体表现,hive执行show tables;不会展现被删除的表,去mysql查看元数据信息,也不会看到该表的信息
- 内部表的数据还会被删除,表现hdfs路径xxx/xxx/table_name/,这个目录连同该目录下的文件会被删除;但是外部表的数据还会存在在hdfs文件系统,表现先前定义该表时指定的location 目录及其下的文件还会在,此时若我们想恢复外部表,只需要按之前创建表的命令再创建一次即可恢复。
- 修改表名:ALTER TABLE emp RENAME TO emp2;
- 若是外部表,修改表名,不会影响到HDFS文件存储,只是表明发生更改,对应路径名不会更改,表现:show tables;出现emp2;但是文件目录,若之前是xxx/xxx/emp_info/xxx,依旧还是xxx/xxx/emp_info/xxx
- 若是内部表,则修改表名,还会体现到HDFS文件存储上,即从xxx/xxx/emp_info/xxx变为xxx/xxx/emp2/xxx
Hive shell一些小命令
shell临时显示字段名
set hive.cli.print.header=true;
shell 临时显示当前库
set hive.cli.print.current.db=true;
查看hive支持的函数
show functions;
查看该函数的使用方法
desc function upper;
查看该函数的使用方法,且有例子介绍
desc function extended upper;
参考: 慕课网 - Hadoop 系统入门+核心精讲
以上是关于数据仓库Hive的主要内容,如果未能解决你的问题,请参考以下文章