实验4 Matplotlib数据可视化
Posted Next***
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了实验4 Matplotlib数据可视化相关的知识,希望对你有一定的参考价值。
1. 实验目的
①掌握Matplotlib绘图基础;
②运用Matplotlib,实现数据集的可视化;
③运用Pandas访问csv数据集。
2. 实验内容
①绘制散点图、直方图和折线图,对数据进行可视化;
②下载波士顿数房价据集,并绘制数据集中各个属性与房价之间的散点图,实现数据集可视化;
③使用Pandas访问鸢尾花数据集,对数据进行设置列标题、读取数据、显示统计信息、转化为Numpy数组等操作;并使用Matpoltlib对数据集进行可视化。
3. 实验过程
题目一:
这是一个商品房销售记录表,请根据表中的数据,按下列要求绘制散点图。其中横坐标为商品房面积,纵坐标为商品房价格。

要求:
(1)绘制散点图,数据点为红色圆点;
(2)标题为:“商品房销售记录”,字体颜色为蓝色,大小为16;
(3)横坐标标签为:“面积(平方米)”,纵坐标标签为“价格(万元)”,字体大小为14。
源代码
import numpy as np
import matplotlib.pyplot as plt
#设置rc参数
plt.rcParams["font.family"] = "SimHei"#设置默认字体为中文黑体
plt.rcParams['axes.unicode_minus'] = False #坐标轴上负号的显示可能会出错
area = np.array([137.97,104.50,100.00,124.32,79.20,99.00,124.00,114.00,106.69,138.05,53.75,46.91,68.00,63.02,81.26,86.21])
price = np.array([145.00,110.00,93.00,116.00,65.32,104.00,118.00,91.00,62.00,133.00,51.00,45.00,78.50,69.65,75.69,95.30])
plt.scatter(area,price,color = 'red')
plt.title("商品房销售记录",fontsize = "16",color = "blue")
plt.xlabel("面积(平方米)",fontsize = '14')
plt.ylabel("价格(万元)",fontsize = '14')
plt.show()

题目二:
按下列要求完成程序。
(1)下载波士顿数据集,读取全部506条数据,放在NumPy数组x、y中(x:属性,y:标记);
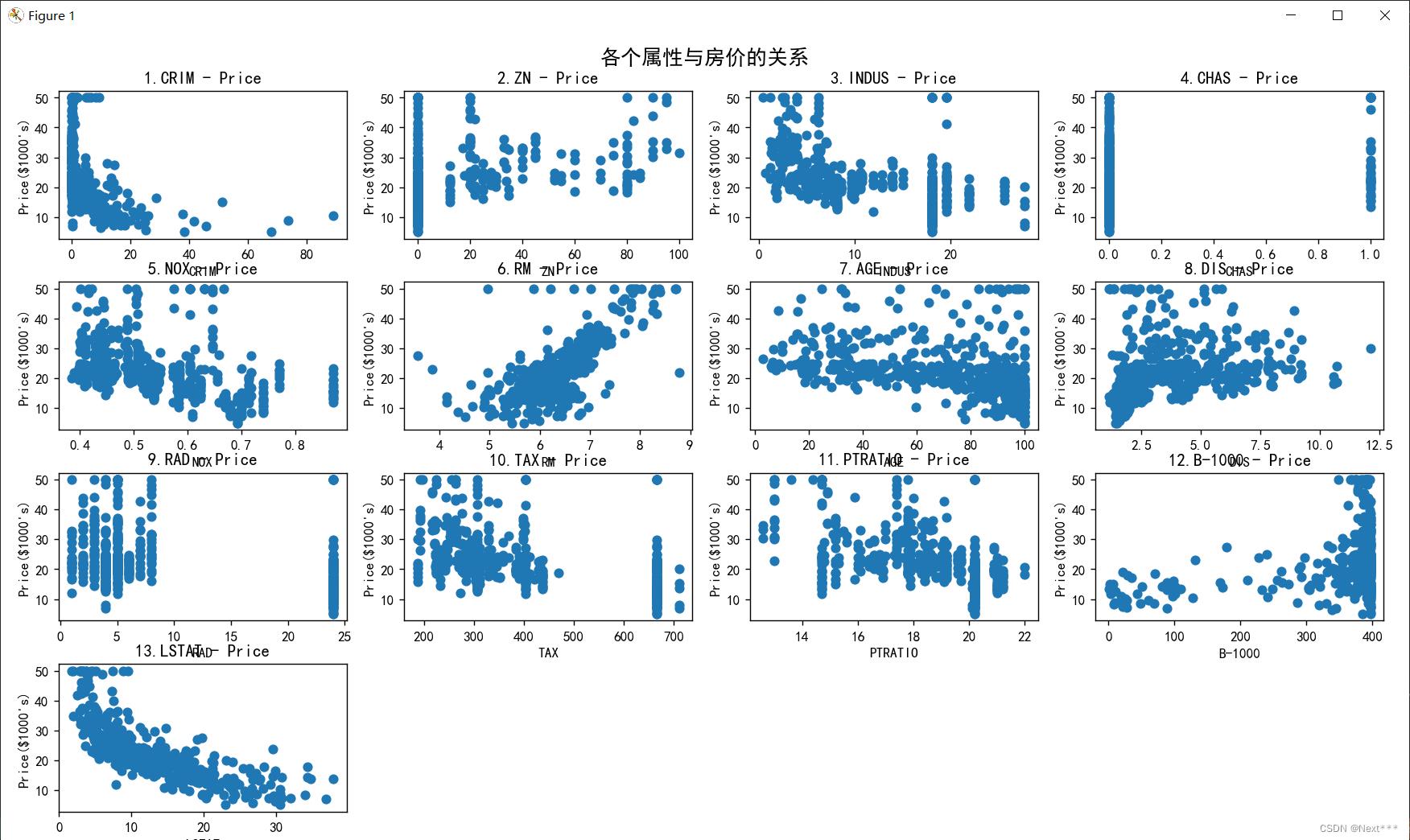
(2)使用全部506条数据,实现波士顿房价数据集可视化,如图1所示;
(3)要求用户选择属性,如图2所示,根据用户的选择,输出对应属性的散点图,如图3所示

请用户输入属性:

运行结果:

import tensorflow as tf
import matplotlib.pyplot as plt
import numpy as np
boston_housing = tf.keras.datasets.boston_housing
(train_x, train_y), (test_x, test_y) = boston_housing.load_data(test_split=0)
plt.rcParams['font.sans-serif'] = "SimHei"
plt.rcParams['axes.unicode_minus'] = False
titles = [
"CRIM", "ZN", "INDUS", "CHAS", "NOX", "RM", "AGE", "DIS", "RAD", "TAX",
"PTRATIO", "B-1000", "LSTAT", "MEDV"
]
plt.figure(figsize=(14, 14))
for i in range(13):
plt.subplot(4, 4, i + 1)
plt.scatter(train_x[:, i], train_y)
plt.xlabel(titles[i])
plt.ylabel("Price($1000's)")
plt.title(str(i + 1) + "." + titles[i] + " - Price")
plt.tight_layout(rect=[0, 0, 1, 0.95])
plt.suptitle("各个属性与房价的关系", x=0.5, y=0.98, fontsize=20)
plt.show()
plt.close()
print("请输入所选择的属性")
print( "1--CRIM\\n", "2--ZN\\n", "3--INDUS\\n", "4--CHAS\\n", "5--NOX\\n", "6--RM\\n",
"7--AGE\\n", "8--DIS\\n", "9--RAD\\n", "10--TAX\\n",
"11--PTRATIO\\n", "12--B-1000\\n", "13--LSTAT\\n", "14--MEDV")
n = int(input())
sc = titles[i - 1] + "Price($1000's)"
plt.figure(figsize=(5,5))
plt.scatter(train_x[:,i-1],train_y)
plt.xlabel(titles[i - 1])
plt.ylabel("Price($1000's)")
plt.title(sc)
plt.show()

题目三:
使用鸢尾花数据集,绘制如下图形,其中对角线为属性的直方图。
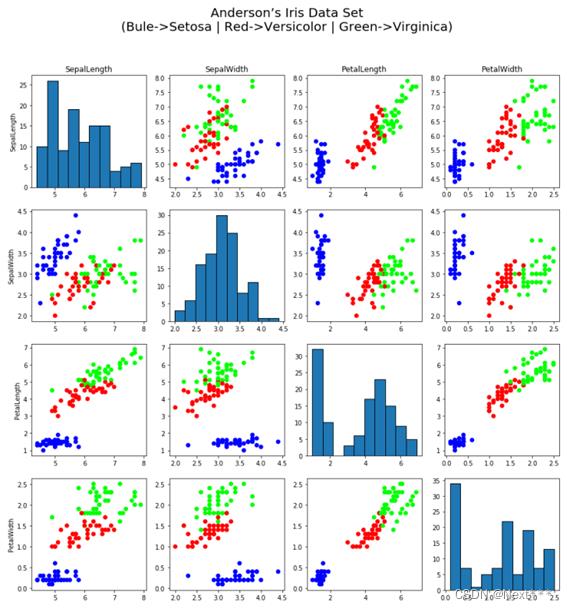
提示:绘制直方图函数 plt.hist(x, align= ‘mid’, color, edgecolor)
import tensorflow as tf
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
TRAIN_URL = "http://download.tensorflow.org/data/iris_training.csv"
train_path = tf.keras.utils.get_file(TRAIN_URL.split('/')[-1],TRAIN_URL)
#设置列标题
COLUMN_NAMES = [
'SepalLEngth', 'SePalWidth', 'PetalLength', 'PetalWidth', 'Species'
]
#下载鸢尾花数据集,并设置列标题
dr_iris = pd.read_csv(train_path, names=COLUMN_NAMES, header=0)
iris = np.array(dr_iris)
fig = plt.figure(figsize=(15, 15))
fig.suptitle(
"Anderson's Iris Data Set\\n(Bule->Setosa | Red->Versicolor | Green->Virginica)"
)
for i in range(4):
for j in range(4):
plt.subplot(4, 4, 4 * i + (j + 1))
if (i == j):
plt.hist(iris[:, j], align='mid')
else:
plt.scatter(iris[:, j], iris[:, i], c=iris[:, 4], cmap='brg')
plt.title(COLUMN_NAMES[j]) # 横坐标标签使用子图标题来实现
plt.ylabel(COLUMN_NAMES[i])
plt.tight_layout(rect=[0, 0, 1, 0.93])
plt.show()

4.实验小结&讨论题
① 实验过程中遇到了哪些问题,你是如何解决的?
没有熟悉使用pycharm,询问了同学。
② 根据题目二的数据进行可视化结果,分析波士顿数据集中各个属性对房价的影响。
占地面积与房价大致呈线性相关。
③ Numpy和Pandas各有什么特点和优势?在应用中应如何选择?
Pandas拥有Numpy一些没有的方法,例如describe函数。其主要区别是:Numpy就像增强版的List,而Pandas就像列表和字典的合集,Pandas有索引。Pandas有两种结构,分别是Series和DataFrame。其中Series拥有Numpy的所有功能,可以认为是简单的一维数组;而DataFrame是将多个Series按列合并而成的二维数据结构,每一列单独取出来是一个Series。
④ 在题目基本要求的基础上,你对每个题目做了那些扩展和提升?或者你觉得在编程实现过程中,还有哪些地方可以进行优化?
完全按照题目的要求来做的。
Python实验四:Matplotlib数据可视化
Python实验四:Matplotlib数据可视化
实验内容:
任务一:分析1996~2015年人口数据特征间的关系
需求说明:人口数据总共拥有 6 个特征,分别为年末总人口、男性人口、女性人口、城镇人口、乡村人口和年份。查看各个特征随着时间推移发生的变化情况可以分析出未来男女人口比例、城乡人口变化的方向。
任务二:分析1996~2015年人口数据各个特征的分布与分散状况
需求说明:通过绘制各年份男女人口数目及城乡人口数目的直方图,男女人口比例及城乡人口比例的饼图可以发现人口结构的变化。而绘制每个特征的箱线图则可以发现不同特征增长或者减少的速率是否变得缓慢。
实验步骤:
任务一步骤:
(1)使用NumPy库读取人口数据。
(2)创建画布figsize=(12,12),并添加子图。
(3)在两个子图上分别绘制散点图其中(marker=’8’,color=’red’)和折线图。
(4)将绘制的散点图和折线图保存在当前文件夹下,分别为“image1.png”和“image2.png”。
(5)显示图片并分析未来人口变化趋势。
import numpy as np
import matplotlib.pyplot as plt
data = np.load('populations.npz')
# print(data['data'])
# print(data['feature_names'])
plt.rcParams['font.sans-serif'] = 'SimHei'
name = data['feature_names']
values = data['data']
pic_1 = plt.figure(figsize=(12, 12))
pic_11 = pic_1.add_subplot(2, 1, 1)
plt.scatter(values[0:20, 0], values[0:20, 1], marker='8', color='red')
plt.legend('年末')
plt.ylabel('总人口(万人)')
plt.title('1996~2015年末与各类人口散点图')
pic2 = pic_1.add_subplot(2, 1, 2)
plt.scatter(values[0:20, 0], values[0:20, 2], marker='o', color='yellow')
plt.scatter(values[0:20, 0], values[0:20, 3], marker='D', color='green')
plt.scatter(values[0:20, 0], values[0:20, 4], marker='p', color='blue')
plt.scatter(values[0:20, 0], values[0:20, 5], marker='s', color='purple')
plt.xlabel('时间')
plt.ylabel('总人口(万人)')
plt.xticks(values[0:20, 0])
plt.legend(['男性', '女性', '城镇', '乡村'])
plt.savefig('image1.png')
pic_2 = plt.figure(figsize=(12, 12))
pic_21 = pic_2.add_subplot(2, 1, 1)
plt.plot(values[0:20, 0], values[0:20, 1], color='r', linestyle='--', marker='8')
plt.ylabel('总人口(万人)')
plt.xticks(range(0, 20, 1), values[range(0, 20, 1), 0], rotation=45)
plt.legend('年末')
plt.title('1996~2015年末总与各类人口折线图')
pic2 = pic_2.add_subplot(2, 1, 2)
plt.plot(values[0:20, 0], values[0:20, 2], 'y-')
plt.plot(values[0:20, 0], values[0:20, 3], 'g-')
plt.plot(values[0:20, 0], values[0:20, 4], 'b-')
plt.plot(values[0:20, 0], values[0:20, 5], 'p-')
plt.xlabel('时间')
plt.ylabel('总人口(万人)')
plt.xticks(values[0:20, 0])
plt.legend(['男性', '女性', '城镇', '乡村'])
plt.savefig('image2.png')
plt.show()
任务二步骤:
(1)创建 3 幅画布并添加对应数目的子图
(2)在每一幅子图上绘制对应的图形
(3)保存和显示图形。将直方图、饼图、箱线图分别保存为image1.png、image2.png、image3.png
(4)根据图形,分析我国人口结构变化情况以及变化速率的增减情况。
import numpy as np
import matplotlib.pyplot as plt
data = np.load('populations.npz', allow_pickle=True)
plt.rcParams['font.sans-serif'] = 'SimHei'
name = data['feature_names']
values = data['data']
label_1 = ['男性', '女性']
label_2 = ['城镇', '乡村']
ex = [0.01, 0.01]
# 绘制直方图
pic_1 = plt.figure(figsize=(12, 12))
pic_11 = pic_1.add_subplot(2, 2, 1)
plt.bar(range(2), values[19, 2:4], width=0.5, color='orange')
plt.ylabel('人口(万人)')
plt.ylim(0, 80000)
plt.xticks(range(2), label_1)
plt.title('1996年男、女人口数直方图')
pic_12 = pic_1.add_subplot(2, 2, 2)
plt.bar(range(2), values[0, 2:4], width=0.5, color='red')
plt.ylabel('人口(万人)')
plt.ylim(0, 80000)
plt.xticks(range(2), label_1)
plt.title('2015年男、女人口数直方图')
pic_13 = pic_1.add_subplot(2, 2, 3)
plt.bar(range(2), values[19, 4:6], width=0.5, color='orange')
plt.xlabel('类别')
plt.ylabel('人口(万人)')
plt.ylim(0, 90000)
plt.xticks(range(2), label_2)
plt.title('1996年城、乡人口数直方图')
pic_14 = pic_1.add_subplot(2, 2, 4)
plt.bar(range(2), values[0, 4:6], width=0.5, color='red')
plt.xlabel('类别')
plt.ylabel('人口(万人)')
plt.ylim(0, 90000)
plt.xticks(range(2), label_2)
plt.title('2015年城、乡人口数直方图')
plt.savefig('image1.png')
# 绘制饼图
pic_2 = plt.figure(figsize=(8, 8))
pic_21 = pic_2.add_subplot(2, 2, 1)
plt.pie(values[19, 2:4], explode=ex, labels=label_1, colors=['pink', 'crimson'], autopct='%1.1f%%')
plt.title('1996年男、女人口数饼图')
pic_22 = pic_2.add_subplot(2, 2, 2)
plt.pie(values[0, 2:4], explode=ex, labels=label_1, colors=['PeachPuff', 'skyblue'], autopct='%1.1f%%')
plt.title('2015年男、女人口数饼图')
pic_23 = pic_2.add_subplot(2, 2, 3)
plt.pie(values[19, 4:6], explode=ex, labels=label_2, colors=['pink', 'crimson'], autopct='%1.1f%%')
plt.title('1996年城、乡人口数饼图')
pic_24 = pic_2.add_subplot(2, 2, 4)
plt.pie(values[0, 4:6], explode=ex, labels=label_2, colors=['PeachPuff', 'skyblue'], autopct='%1.1f%%')
plt.title('2015年城、乡人口数饼图')
plt.savefig('image2.png')
# 箱纸图
pic_3 = plt.figure(figsize=(10, 10))
plt.boxplot(values[0:20, 1:6], notch=True, labels=['年末', '男性', '女性', '城镇', '乡村'], meanline=True)
plt.xlabel('类别')
plt.ylabel('人口(万人)')
plt.title('1996~2015年各特征人口箱纸图')
plt.savefig('image3.png')
plt.show()
以上是关于实验4 Matplotlib数据可视化的主要内容,如果未能解决你的问题,请参考以下文章
Python进阶(四十)-数据可视化の使用matplotlib进行绘图
Python可视化-当Matplotlib遇上matplotx