Hadoop13:案例MapReduce任务日志查看
Posted 大自然的农民工
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hadoop13:案例MapReduce任务日志查看相关的知识,希望对你有一定的参考价值。
在上一篇中介绍了MapReduce进行单词计数的案例,这一章介绍下怎么查看MapReduce的任务日志。
如果想要查看mapreduce任务执行过程产生的日志信息怎么办呢?
是不是在提交任务的时候直接在这个控制台上就能看到了?先不要着急,我们先在代码中增加一些日志信息,在实际工作中做调试的时候这个也是很有必要的
一、syout日志输出
1、mapper类修改
在自定义mapper类的map函数中增加一个输出,将k1,v1的值打印出来
添加内容如下:
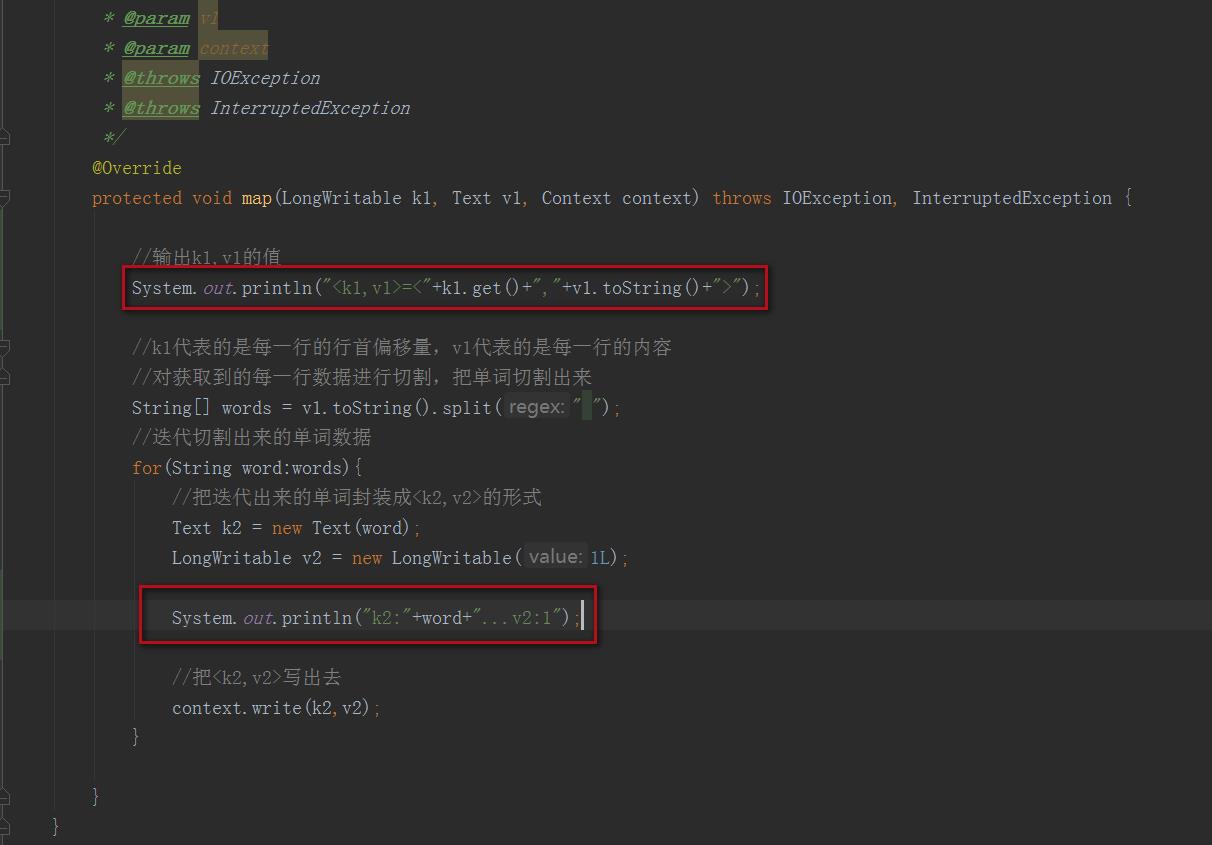
mapper类修改后代码如下:
public static class MyMapper extends Mapper<LongWritable,Text,Text,LongWritable>
/**
* 需要实现map函数
* 这个map函数就是可以接收k1,v1, 产生k2,v2
* @param k1
* @param v1
* @param context
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void map(LongWritable k1, Text v1, Context context) throws IOException, InterruptedException
//输出k1,v1的值
System.out.println("<k1,v1>=<"+k1.get()+","+v1.toString()+">");
//k1代表的是每一行的行首偏移量,v1代表的是每一行的内容
//对获取到的每一行数据进行切割,把单词切割出来
String[] words = v1.toString().split(" ");
//迭代切割出来的单词数据
for(String word:words)
//把迭代出来的单词封装成<k2,v2>的形式
Text k2 = new Text(word);
LongWritable v2 = new LongWritable(1L);
System.out.println("k2:"+word+"...v2:1");
//把<k2,v2>写出去
context.write(k2,v2);
2、reducer类修改
在自定义reducer类中的reduce方法中增加一个输出,将k2,v2和k3,v3的值打印出来
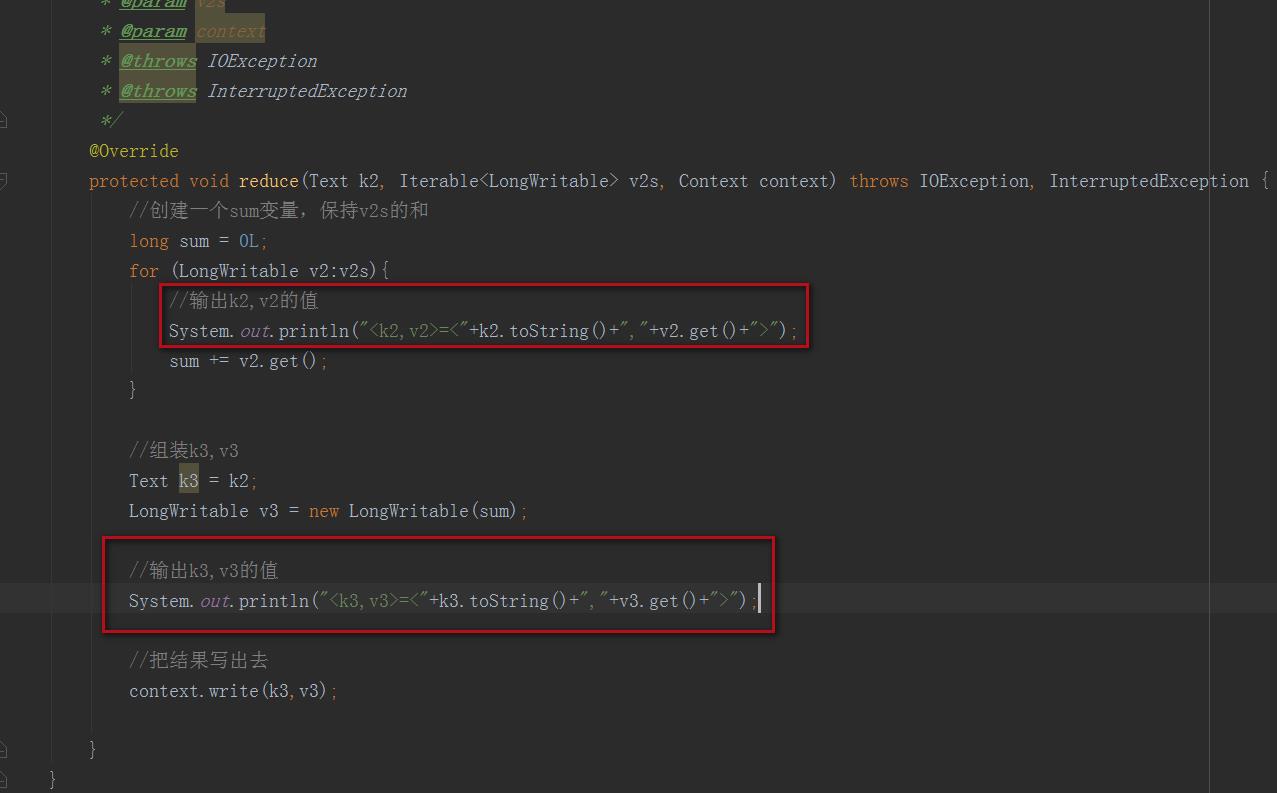
修改后reducer代码如下:
public static class MyReducer extends Reducer<Text,LongWritable,Text,LongWritable>
/**
* 针对v2s的数据进行累加求和,并且最终把数据转化为k3,v3写出去
* @param k2
* @param v2s
* @param context
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void reduce(Text k2, Iterable<LongWritable> v2s, Context context) throws IOException, InterruptedException
//创建一个sum变量,保持v2s的和
long sum = 0L;
for (LongWritable v2:v2s)
//输出k2,v2的值
System.out.println("<k2,v2>=<"+k2.toString()+","+v2.get()+">");
sum += v2.get();
//组装k3,v3
Text k3 = k2;
LongWritable v3 = new LongWritable(sum);
//输出k3,v3的值
System.out.println("<k3,v3>=<"+k3.toString()+","+v3.get()+">");
//把结果写出去
context.write(k3,v3);
3、打包
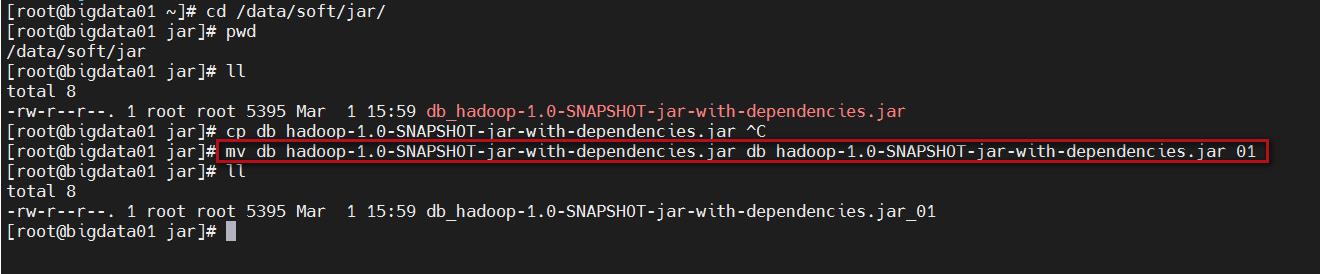
把之前的jar包改个名字备份一下
mv db_hadoop-1.0-SNAPSHOT-jar-with-dependencies.jar db_hadoop-1.0-SNAPSHOT-jar-with-dependencies.jar_01
重新在windows机器上打jar包
mvn clean package -DskipTests
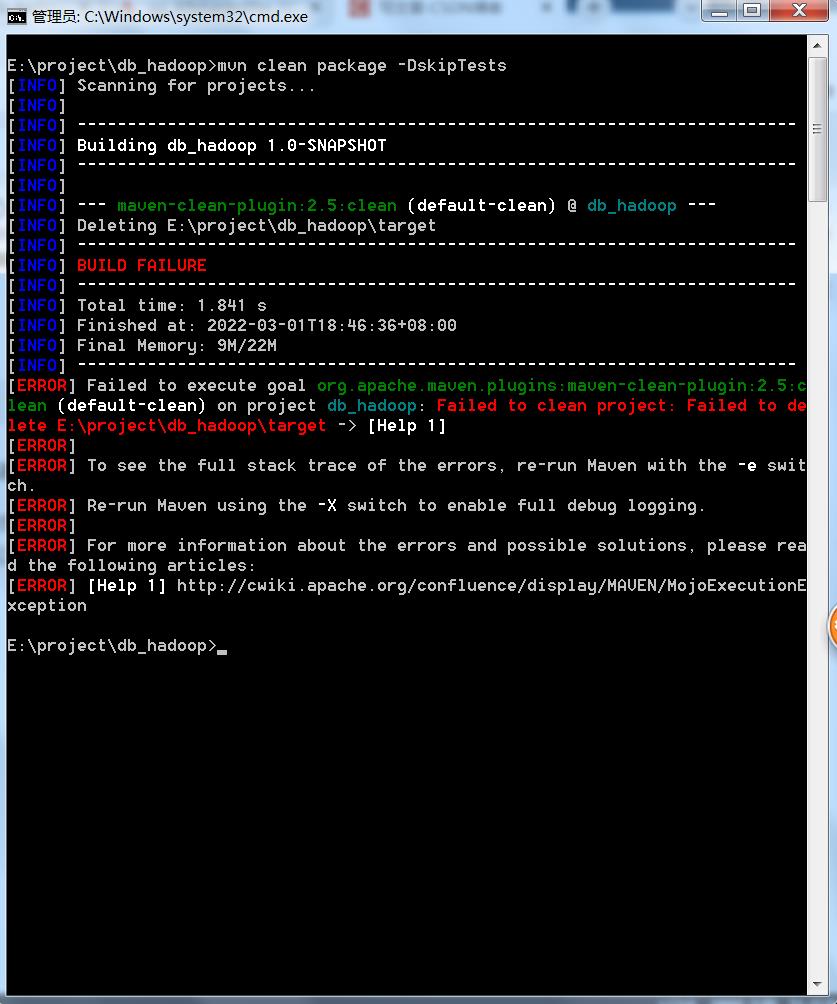
我们发现报错了,因为上传到服务器占用了这个目录!!!
这里的解决办法是随便切到一个目录,上传一个东西这样就不会占用了!!关闭MobaXterm重新打开MobaXterm是没有用的,还是会记录上一次的目录!!
我这里重新在/data/soft目录上传了一个hello.txt文件。
这样的话,本地项目所在的目录就不会被占用了
E:\\project\\db_hadoop\\target
然后,重新执行如下命令
mvn clean package -DskipTests
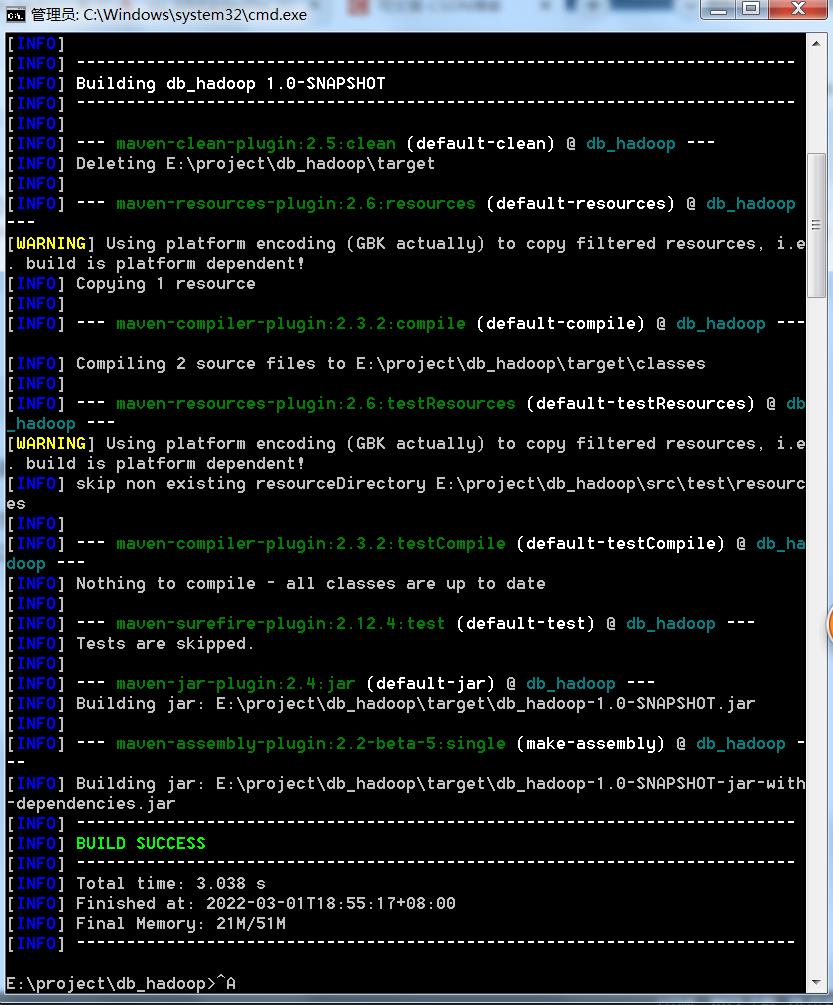
这样就能打包成功了。
把新的jar包上传到bigdata01机器的/data/soft/jar目录中
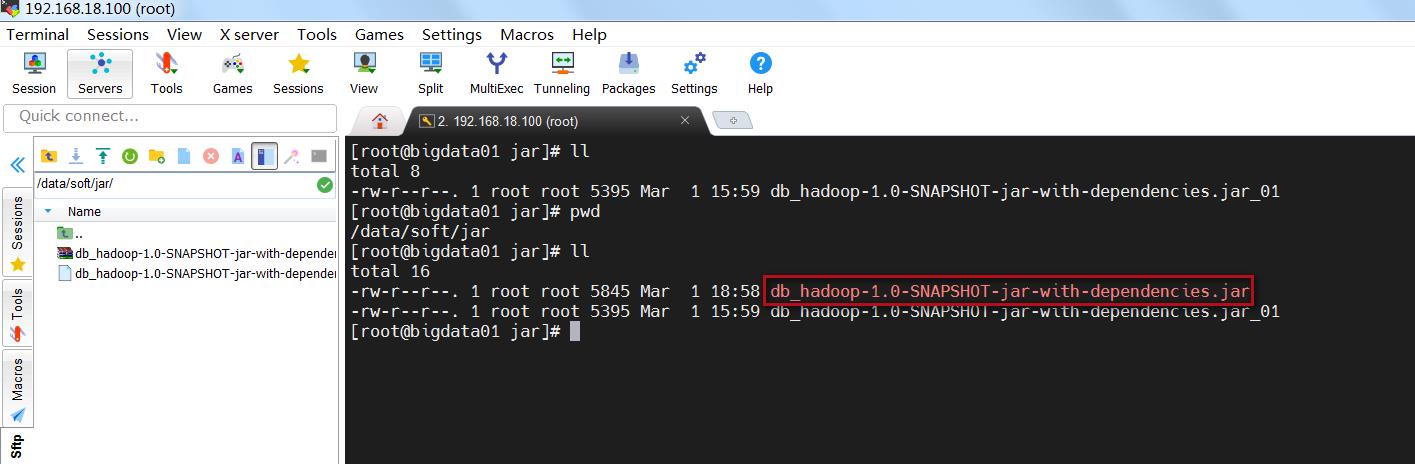
下面那个是我们备份的,不用管它。
4、提交任务
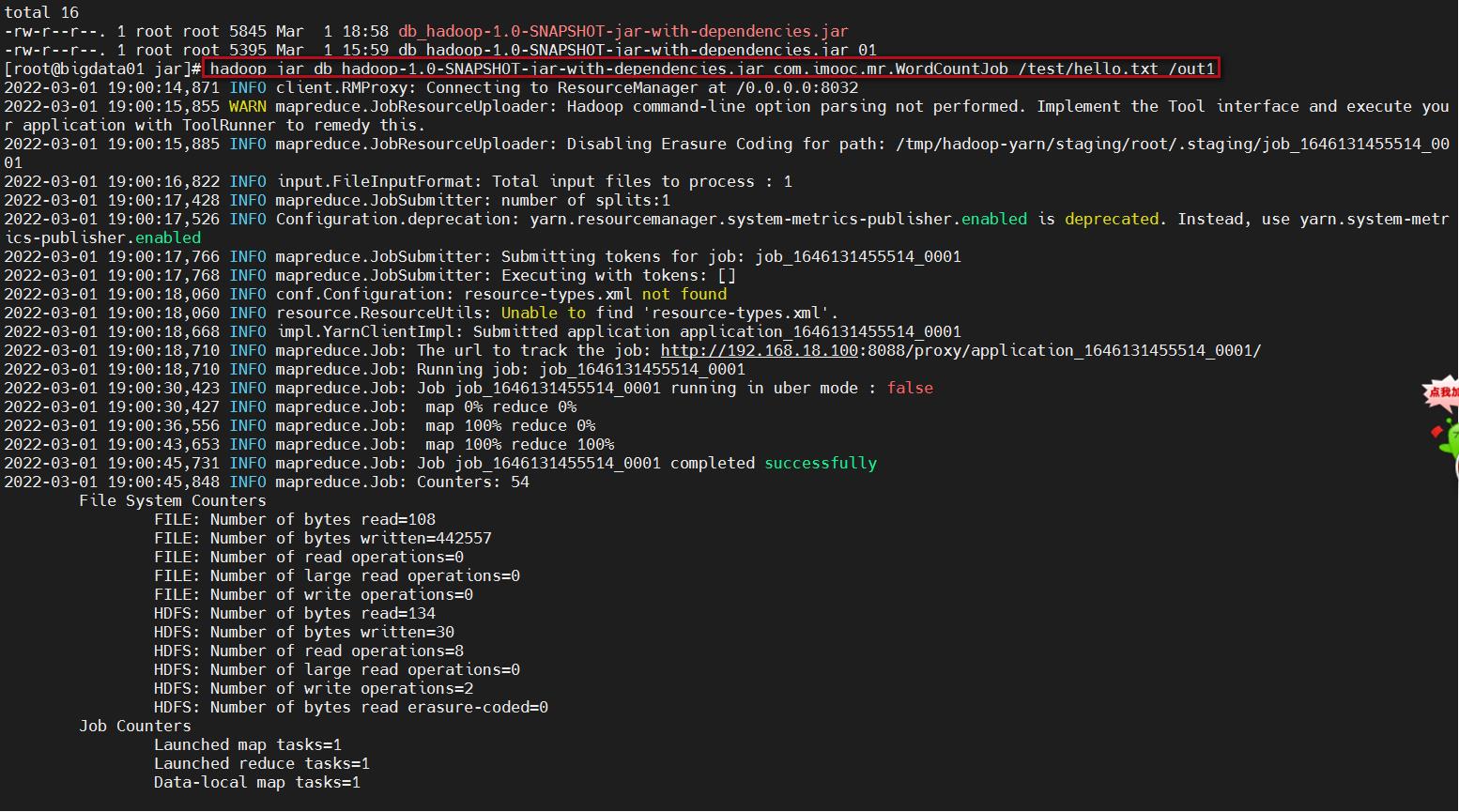
重新向集群提交任务,注意,针对输出目录,要么换一个新的不存在的目录,要么把之前的out目录删掉可以继续使用out目录,在这里我换了一个新的输出目录 out1
hadoop jar db_hadoop-1.0-SNAPSHOT-jar-with-dependencies.jar com.imooc.mr.WordCountJob /test/hello.txt /out1
等待任务执行结束,我们发现在控制台上是看不到任务中的日志信息的,为什么呢?因为我们在这相当于是通过一个客户端把任务提交到集群里面去执行了,所以日志是存在在集群里面的。想要查看需要需要到一个特殊的地方查看这些日志信息。
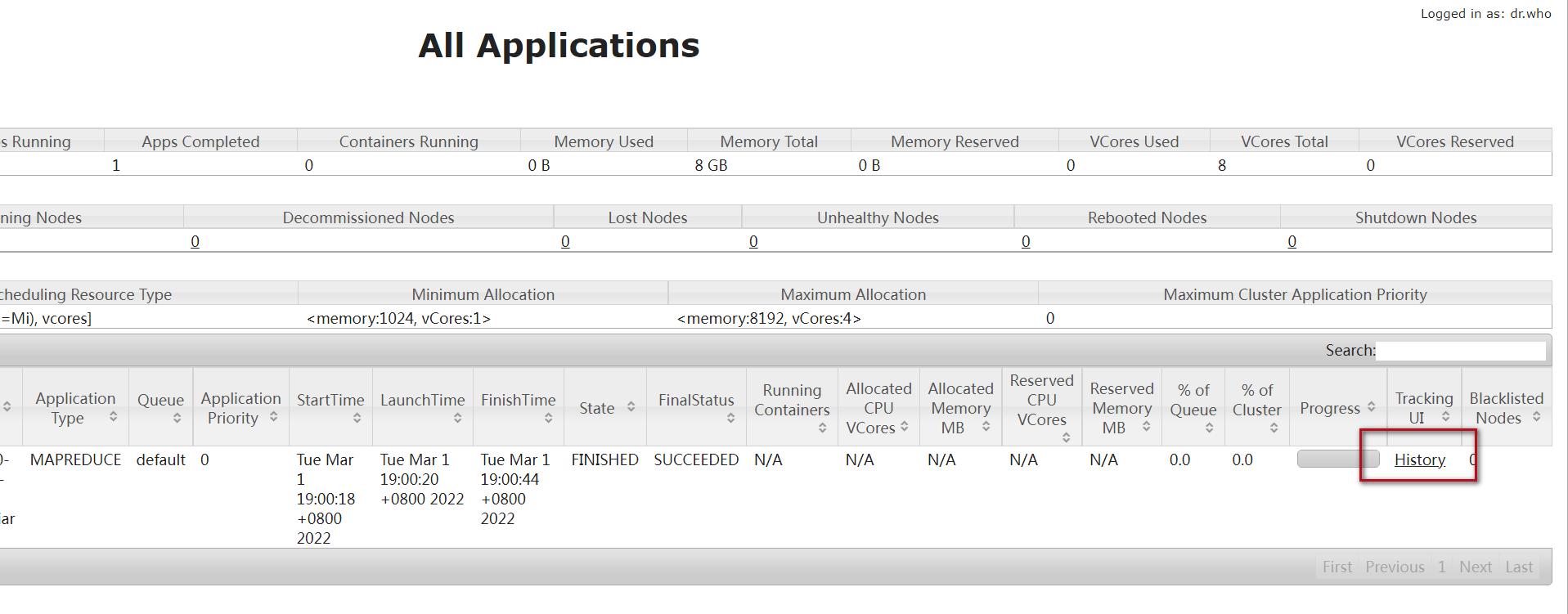
先进入到yarn的web界面,访问8088端口,点击对应任务的history链接
http://bigdata01:8088/
注意:如果想使用主机名在浏览器中访问8088界面,不能开启翻墙工具,否则就算在windows的hosts文件中配置了虚拟机的ip和主机名的映射关系,在浏览器中也无法使用主机名访问,因为此时请求会被翻墙工具所拦截,但是翻墙工具中无法识别这个主机名。
注意了,在这里我们发现这个链接是打不来的,如下
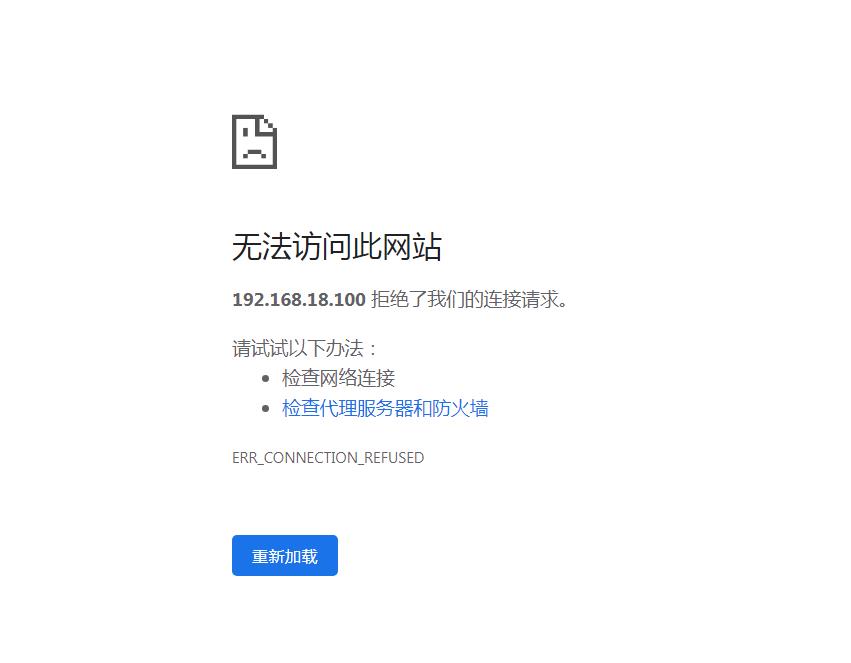
原因有2个:
第1个原因:
没有在本地C:\\Windows\\System32\\drivers\\etc\\hosts进行配置主机名和ip的映射关系。
192.168.18.100 bigdata01
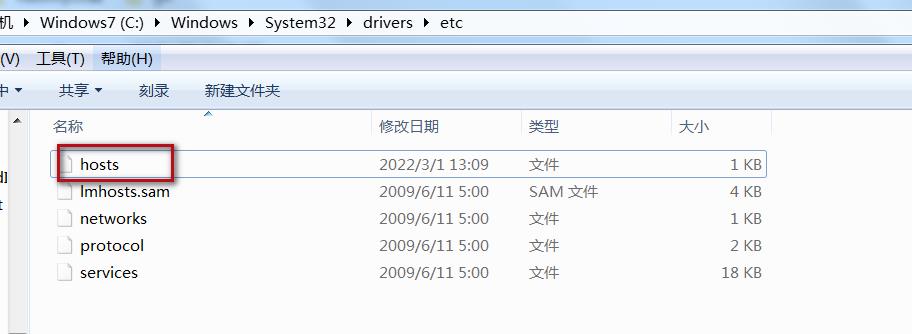
但我们发现我们已经进行配置了。

第2个原因:
就是这里必须要启动historyserver进程才可以,并且还要开启日志聚合功能,才能在web界面上直接查看任务对应的日志信息,因为默认情况下任务的日志是散落在nodemanager节点上的,想要查看需要找到对应的nodemanager节点上去查看,这样就很不方便,通过日志聚合功能我们可以把之前本来散落在nodemanager节点上的日志统一收集到hdfs上的指定目录中,这样就可以在yarn的web界面中直接查看了。
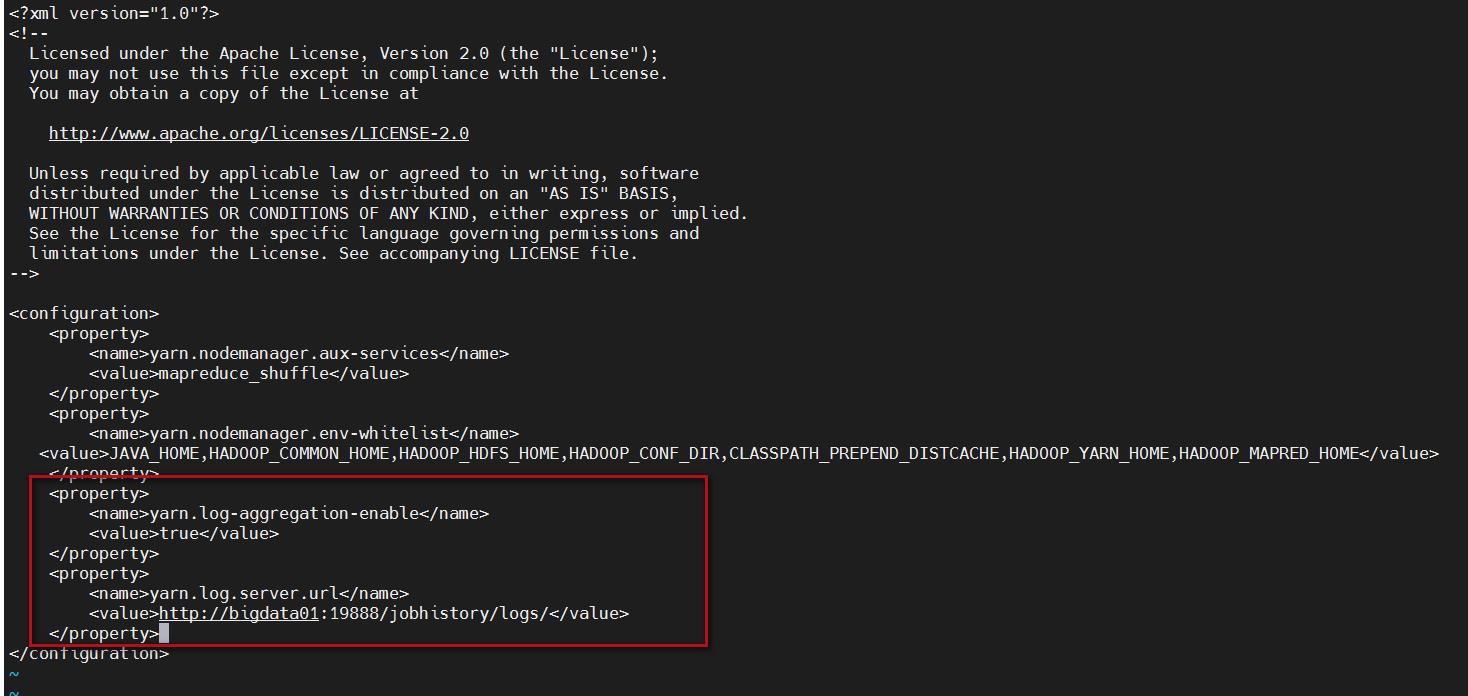
那我们就来开启日志聚合功能。开启日志聚合功能需要修改yarn-site.xml的配置,增加
yarn.log-aggregation-enable和yarn.log.server.url这两个参数
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log.server.url</name>
<value>http://bigdata01:19888/jobhistory/logs/</value>
</property>
然后我们进行修改
cd /data/soft/hadoop-3.2.0/etc/hadoop
vi yarn-site.xml
添加后如下:
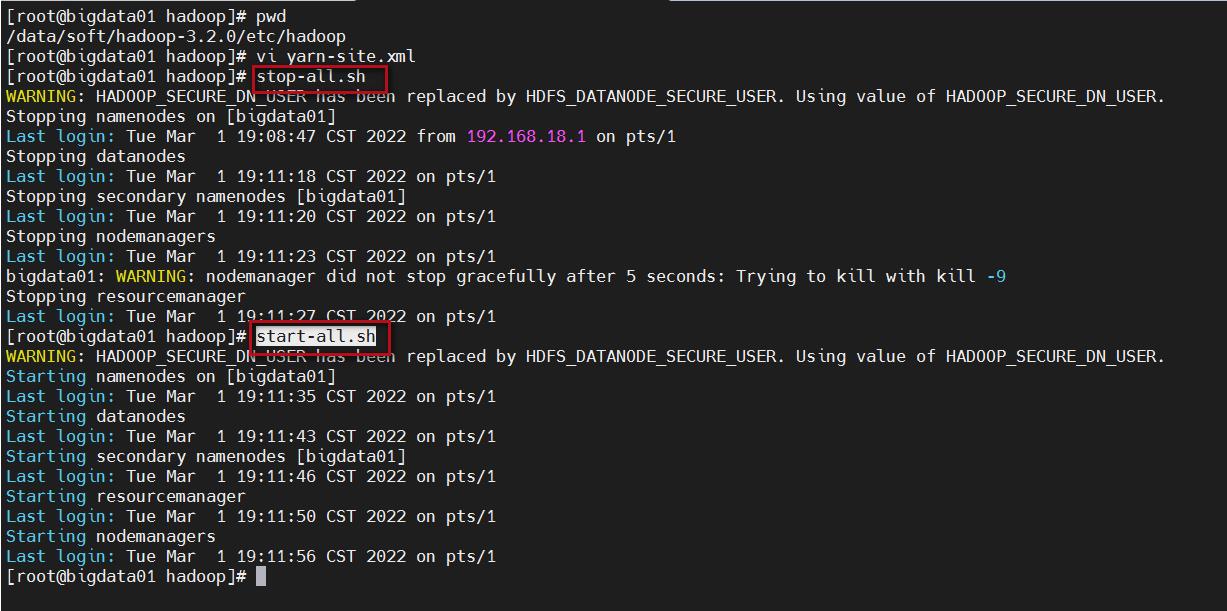
注意,修改完成后重新启动集群。
stop-all.sh
start-all.sh
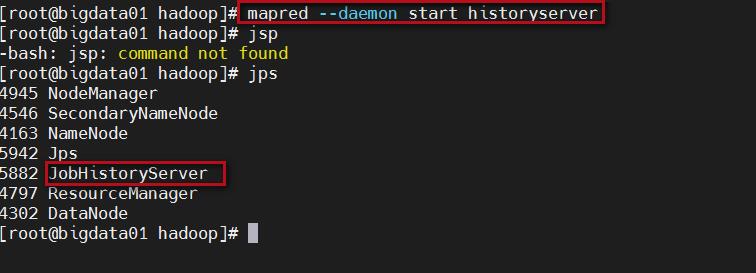
启动historyserver进程,需要在集群的所有节点上都启动这个进程,因为我这里是伪分布部署的,只有一个节点,只需要启动一个。
mapred --daemon start historyserver
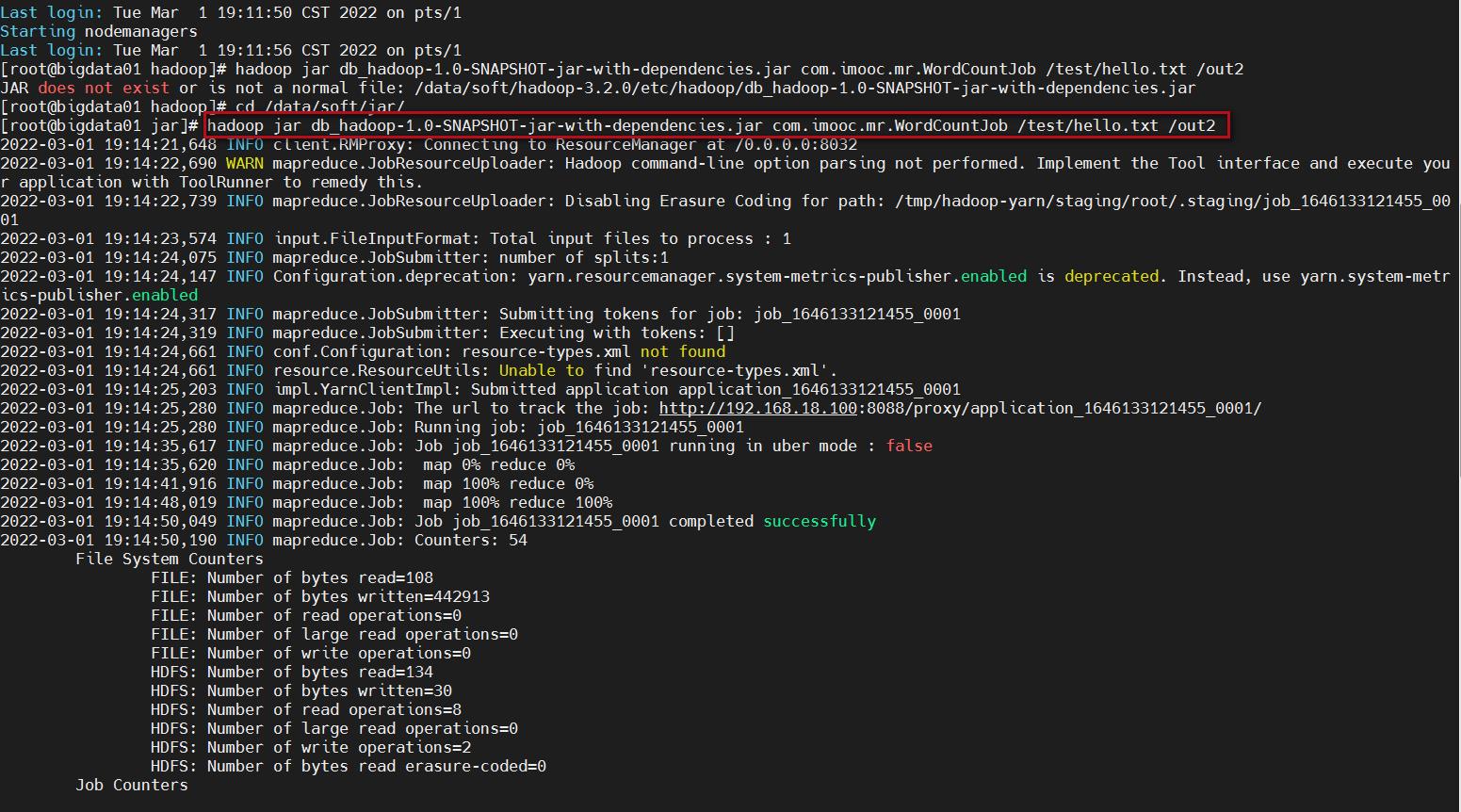
5、重新提交任务
重启集群后之前的任务就没了,这里我重新修改了输出目录为/out2
cd /data/soft/jar/
hadoop jar db_hadoop-1.0-SNAPSHOT-jar-with-dependencies.jar com.imooc.mr.WordCountJob /test/hello.txt /out2
等待任务执行完成
此时再进入yarn的8088界面,点击任务对应的history链接就可以打开了。
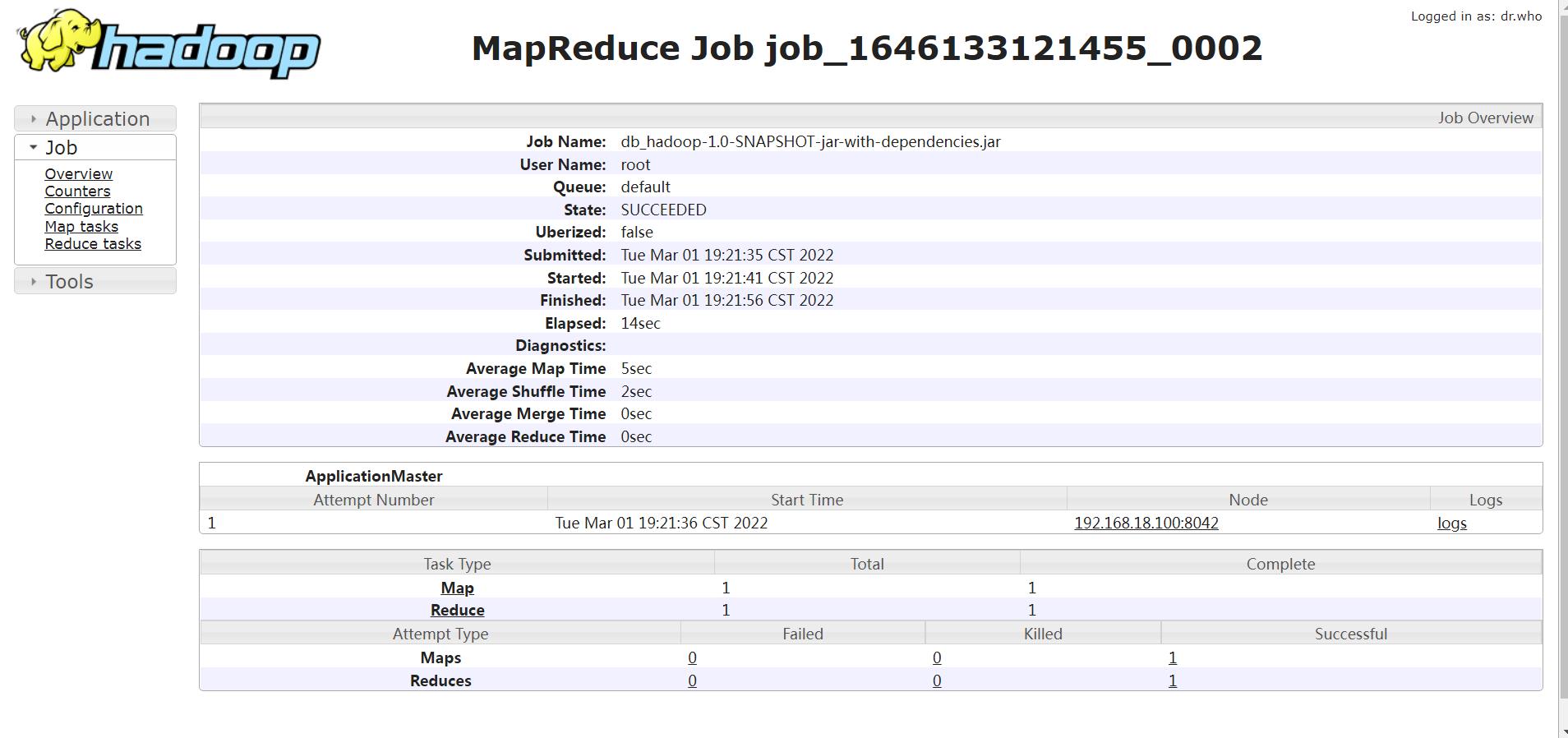
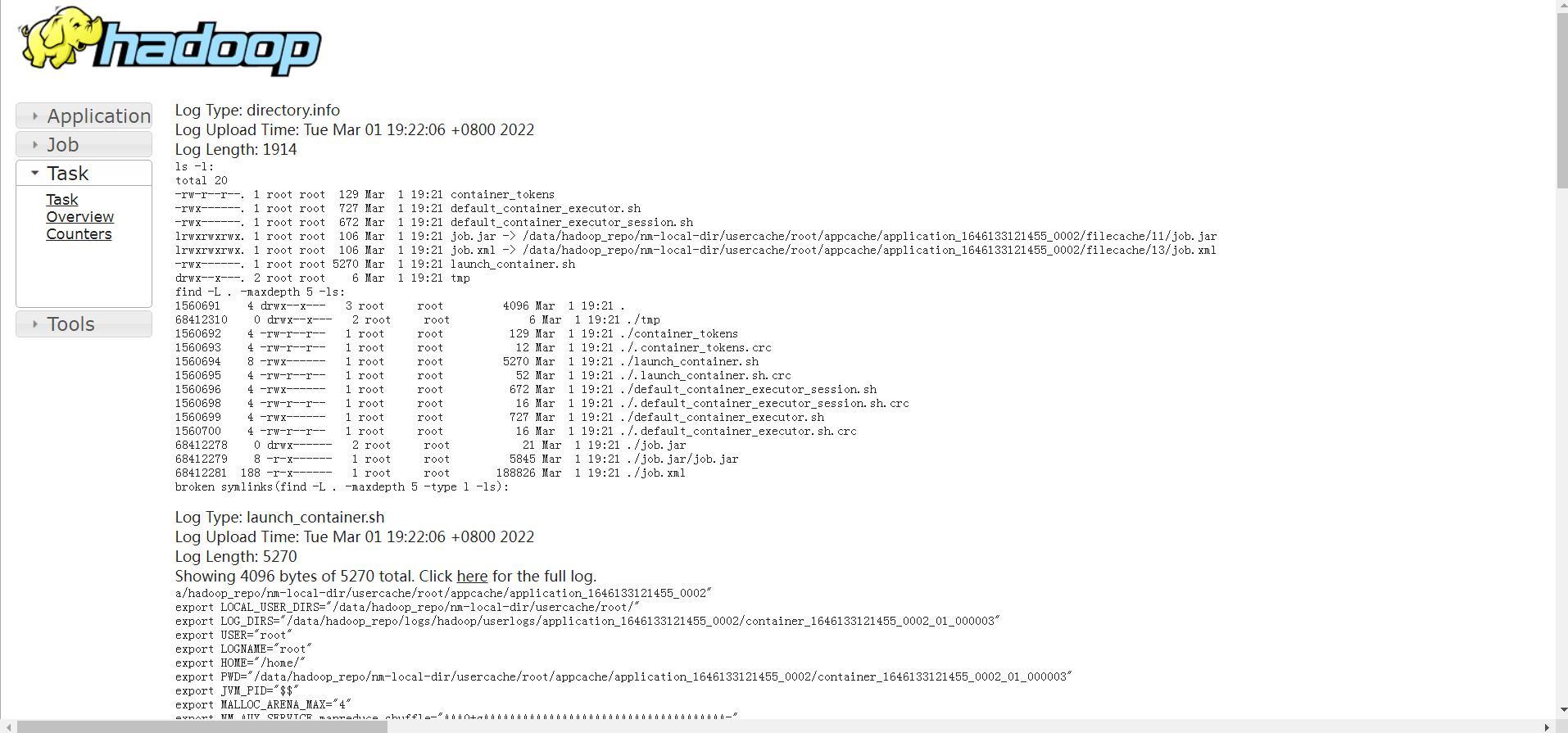
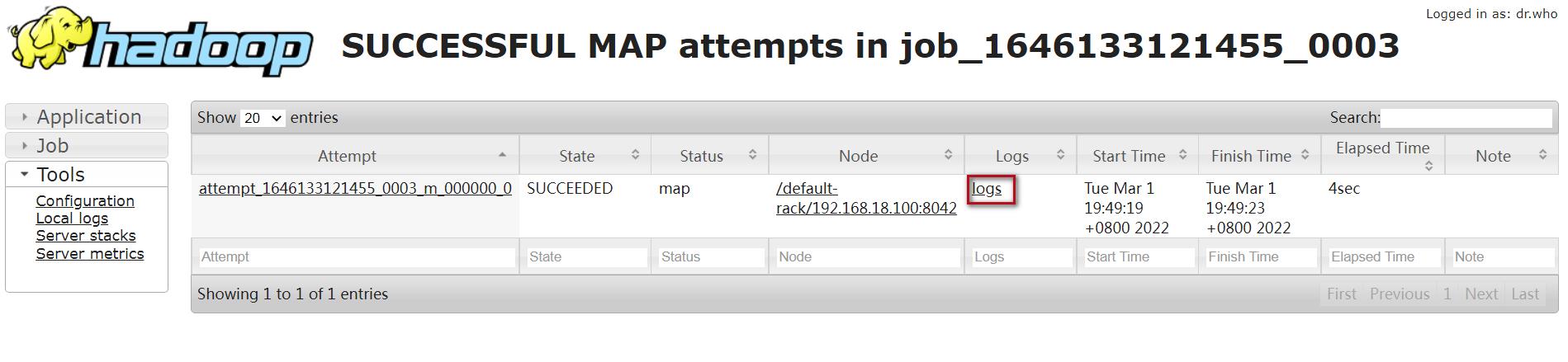
此时,点击对应map和reduce后面的链接就可以点进去查看日志信息了,点击map后面的数字1,可以进入如下界面
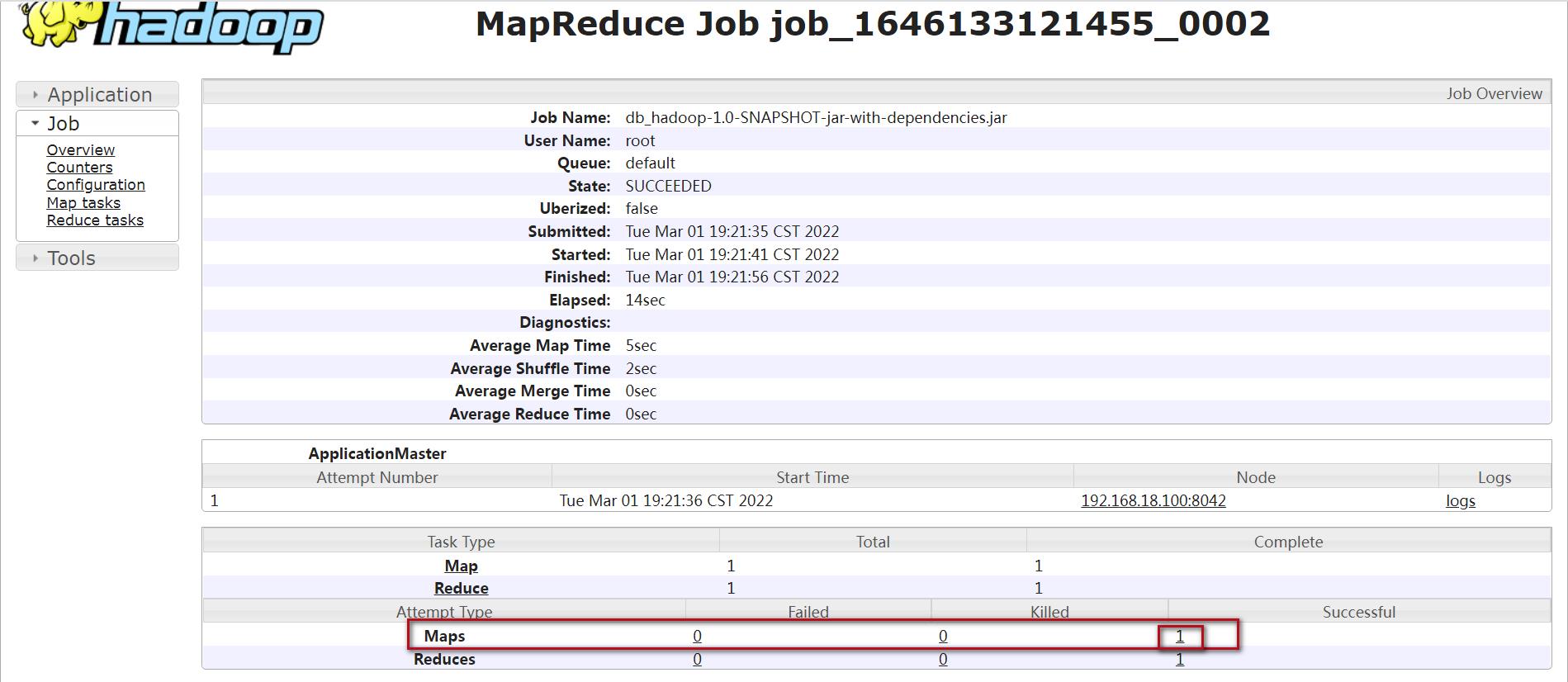
点击这个界面中的logs文字链接,可以查看详细的日志信息。
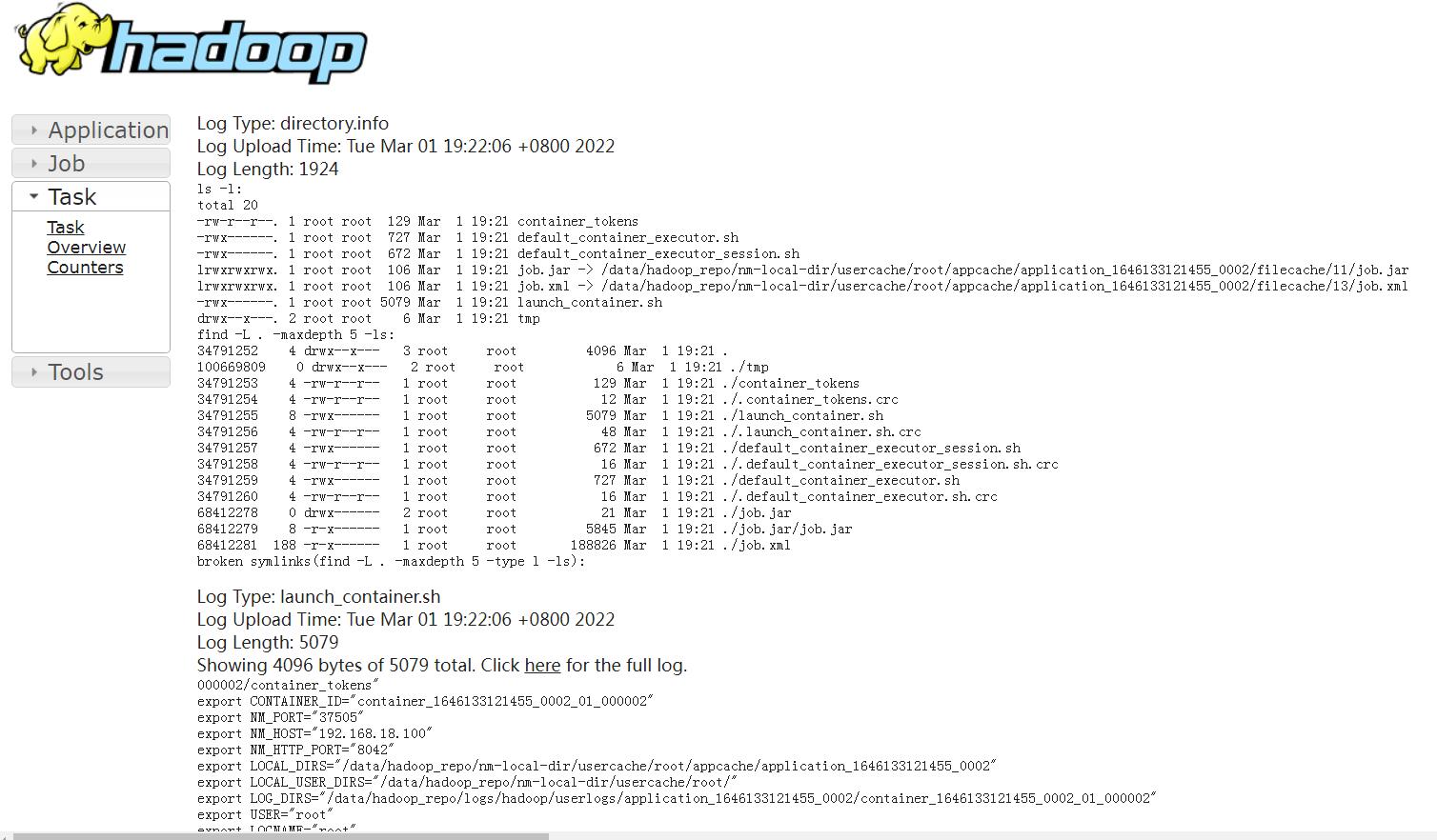
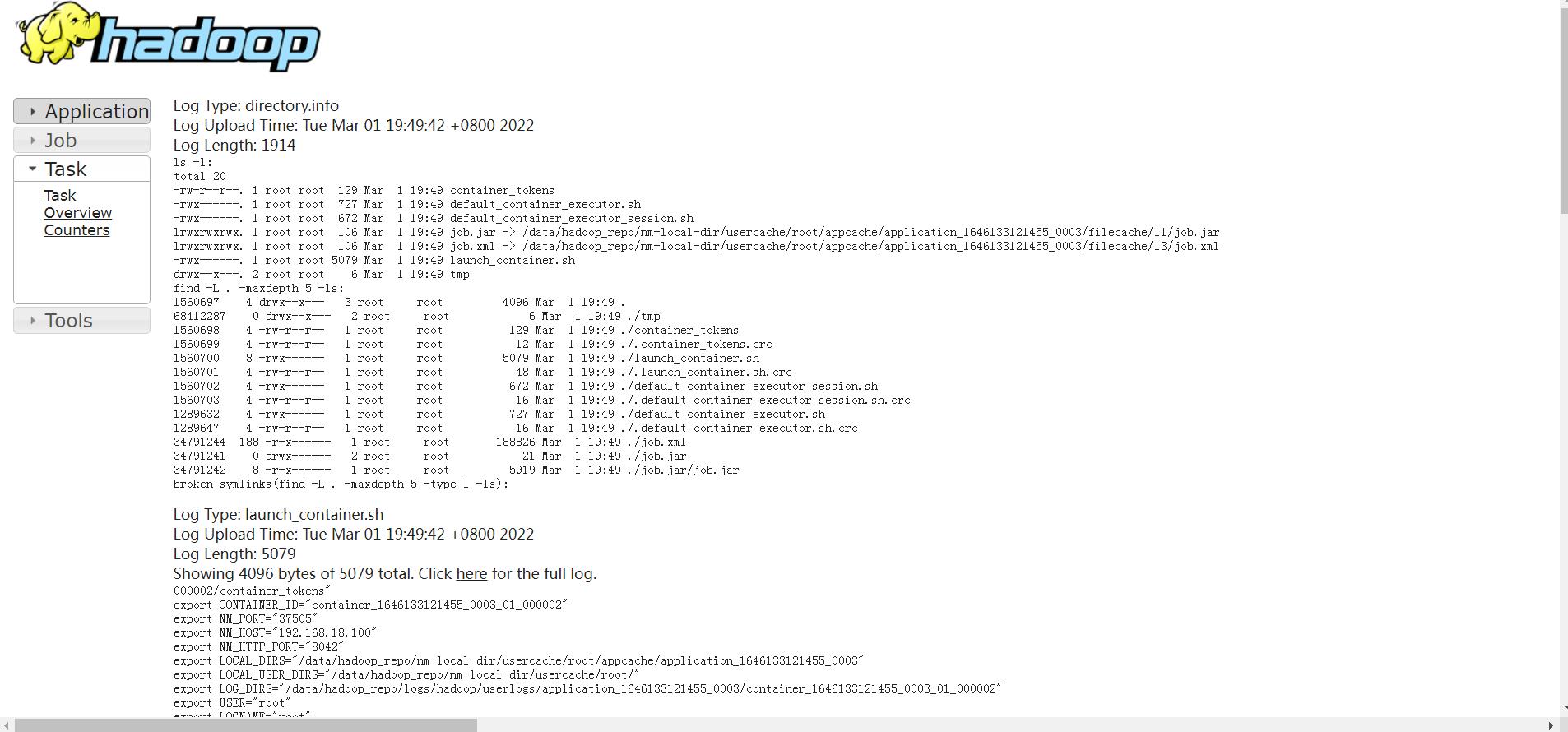
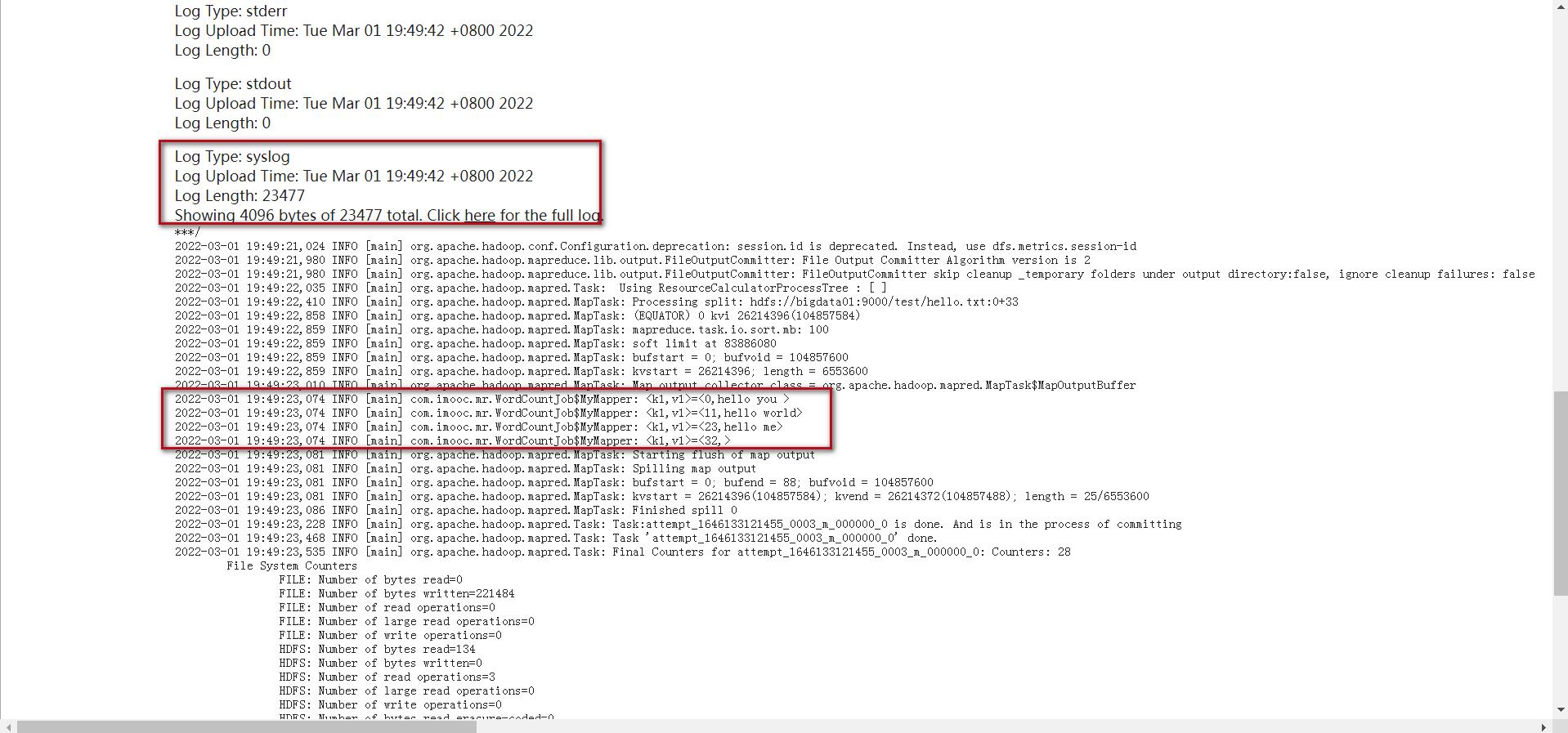
最终可以在界面中看到很多日志信息,我们刚才使用sout输出的日志信息需要到Log Type: stdout这里来查看,在这里可以看到,k1和v1的值
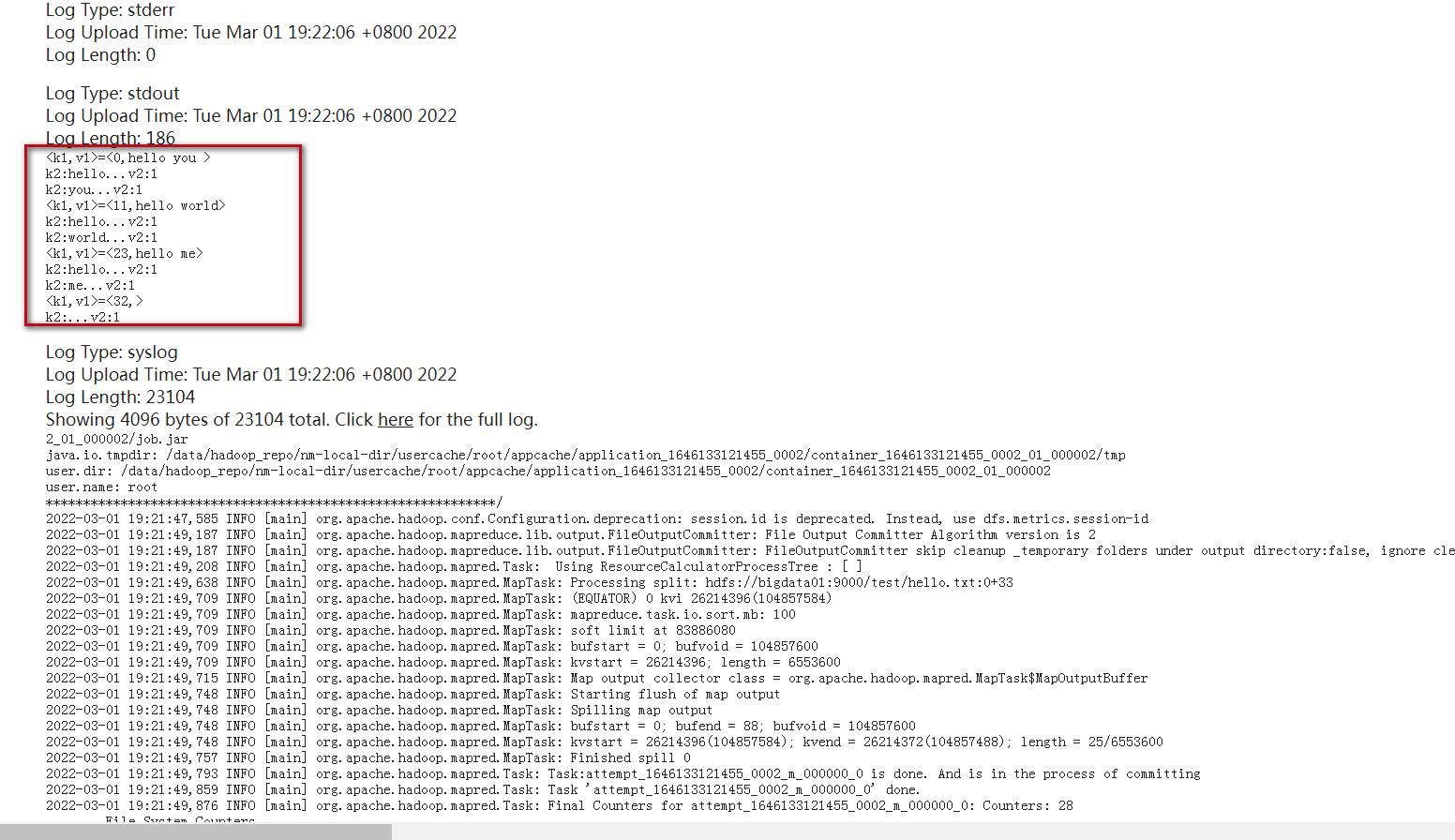
想要查看reduce输出的日志信息需要到reduce里面查看,操作流程是一样的,可以看到k2,v2和k3,v3的值。

咱们刚才的输出是使用syout输出的,这个其实是不正规的,标准的日志写法是需要使用logger进行输出的。
二、logger日志输出
1、修改mapper类
修改如下部分:
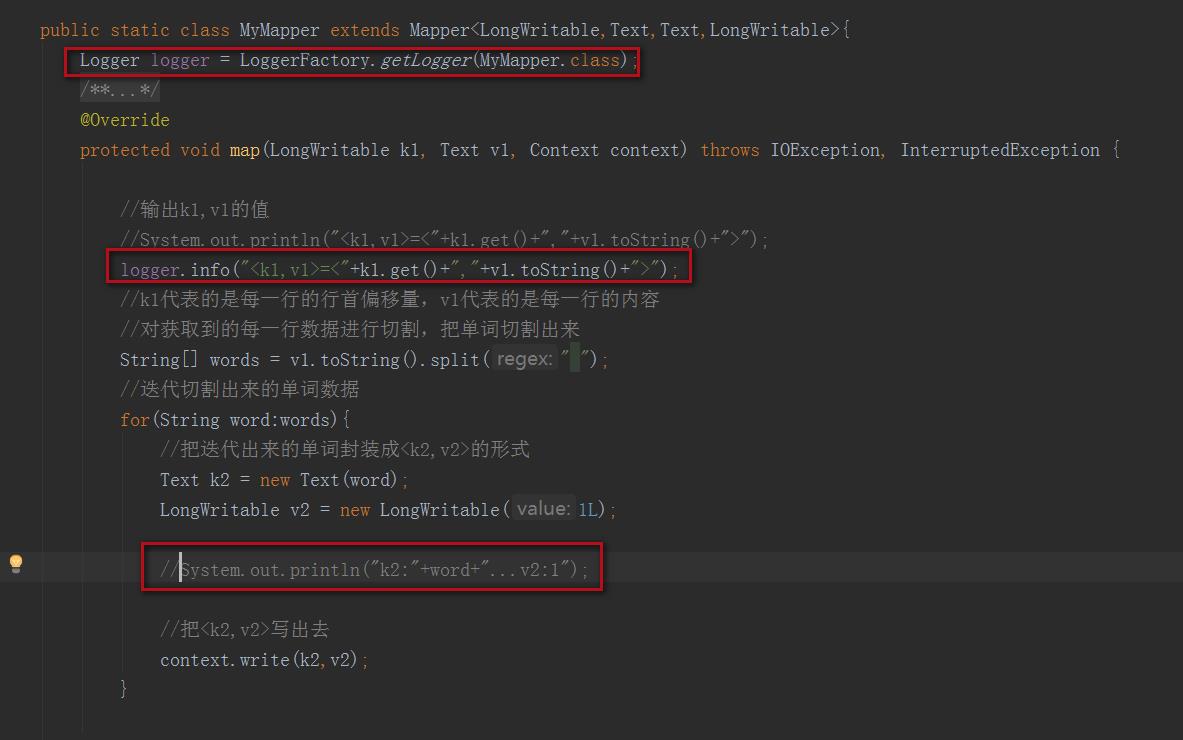
修改后代码如下:
public static class MyMapper extends Mapper<LongWritable,Text,Text,LongWritable>
Logger logger = LoggerFactory.getLogger(MyMapper.class);
/**
* 需要实现map函数
* 这个map函数就是可以接收k1,v1, 产生k2,v2
* @param k1
* @param v1
* @param context
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void map(LongWritable k1, Text v1, Context context) throws IOException, InterruptedException
//输出k1,v1的值
//System.out.println("<k1,v1>=<"+k1.get()+","+v1.toString()+">");
logger.info("<k1,v1>=<"+k1.get()+","+v1.toString()+">");
//k1代表的是每一行的行首偏移量,v1代表的是每一行的内容
//对获取到的每一行数据进行切割,把单词切割出来
String[] words = v1.toString().split(" ");
//迭代切割出来的单词数据
for(String word:words)
//把迭代出来的单词封装成<k2,v2>的形式
Text k2 = new Text(word);
LongWritable v2 = new LongWritable(1L);
//System.out.println("k2:"+word+"...v2:1");
//把<k2,v2>写出去
context.write(k2,v2);
2、修改reducer类
修改如下部分:
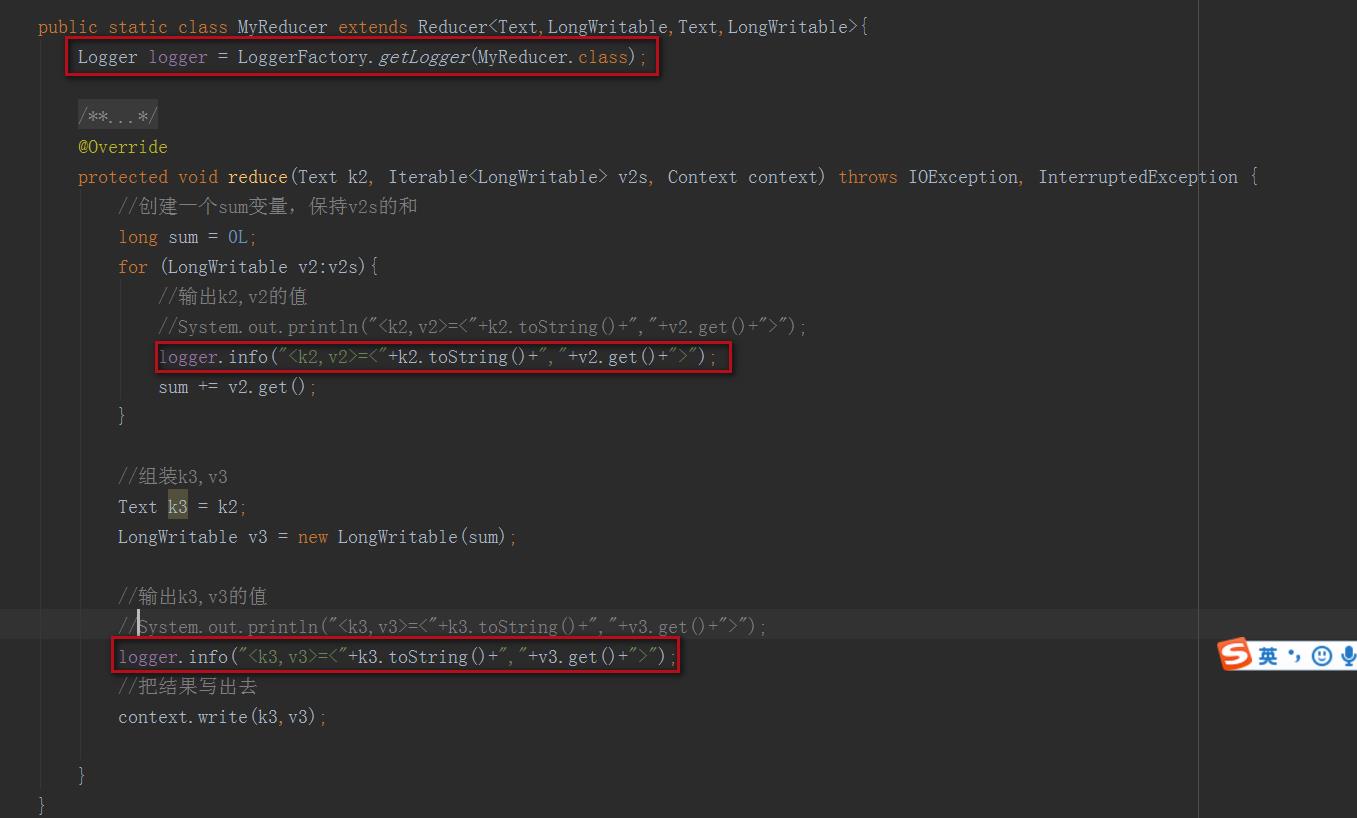
修改后代码如下:
public static class MyReducer extends Reducer<Text,LongWritable,Text,LongWritable>
Logger logger = LoggerFactory.getLogger(MyReducer.class);
/**
* 针对v2s的数据进行累加求和,并且最终把数据转化为k3,v3写出去
* @param k2
* @param v2s
* @param context
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void reduce(Text k2, Iterable<LongWritable> v2s, Context context) throws IOException, InterruptedException
//创建一个sum变量,保持v2s的和
long sum = 0L;
for (LongWritable v2:v2s)
//输出k2,v2的值
//System.out.println("<k2,v2>=<"+k2.toString()+","+v2.get()+">");
logger.info("<k2,v2>=<"+k2.toString()+","+v2.get()+">");
sum += v2.get();
//组装k3,v3
Text k3 = k2;
LongWritable v3 = new LongWritable(sum);
//输出k3,v3的值
//System.out.println("<k3,v3>=<"+k3.toString()+","+v3.get()+">");
logger.info("<k3,v3>=<"+k3.toString()+","+v3.get()+">");
//把结果写出去
context.write(k3,v3);
修改后整个代码汇总如下:
package com.imooc.mr;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.io.IOException;
/**
* 需求:读取hdfs上的hello.txt文件,计算文件中每个单词出现的总次数
* hello.txt文件内容如下:
* hello you
* hello me
* 最终需要的结果形式如下:
* hello 2
* me 1
* you 1
*/
public class WordCountJob
/**
* 组装job=map+reduce
* @param args
*/
public static void main(String[] args)
try
if(args.length != 2)
System.exit(100);
//job需要的配置参数
Configuration conf = new Configuration();
//创建一个job
Job job = Job.getInstance(conf);
// 注意:这一行必须设置,否则在集群中执行的是找不到WordCountJob这个类
job.setJarByClass(WordCountJob.class);
//指定输入路径(可以是文件,也可以是目录)
FileInputFormat.setInputPaths(job,new Path(args[0]));
//指定输出路径(只能指定一个不存在的目录)
FileOutputFormat.setOutputPath(job,new Path(args[1]));
//指定map相关的代码
job.setMapperClass(MyMapper.class);
//指定k2的类型
job.setMapOutputKeyClass(Text.class);
//指定v2的类型
job.setMapOutputValueClass(LongWritable.class);
//指定reduce相关的代码
job.setReducerClass(MyReducer.class);
//指定k3的类型
job.setOutputKeyClass(Text.class);
//指定v3的类型
job.setOutputValueClass(LongWritable.class);
//提交job
job.waitForCompletion(true);
catch (Exception e)
e.printStackTrace();
public static class MyMapper extends Mapper<LongWritable,Text,Text,LongWritable>
Logger logger = LoggerFactory.getLogger(MyMapper.class);
/**
* 需要实现map函数
* 这个map函数就是可以接收k1,v1, 产生k2,v2
* @param k1
* @param v1
* @param context
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void map(LongWritable k1, Text v1, Context context) throws IOException, InterruptedException
//输出k1,v1的值
//System.out.println("<k1,v1>=<"+k1.get()+","+v1.toString()+">");
logger.info("<k1,v1>=<"+k1.get()+","+v1.toString()+">");
//k1代表的是每一行的行首偏移量,v1代表的是每一行的内容
//对获取到的每一行数据进行切割,把单词切割出来
String[] words = v1.toString().split(" ");
//迭代切割出来的单词数据
for(String word:words)
//把迭代出来的单词封装成<k2,v2>的形式
Text k2 = new Text(word);
LongWritable v2 = new LongWritable(1L);
//System.out.println("k2:"+word+"...v2:1");
//把<k2,v2>写出去
context.write(k2,v2);
public static class MyReducer extends Reducer<Text,LongWritable,Text,LongWritable>
Logger logger = LoggerFactory.getLogger(MyReducer.class);
/**
* 针对v2s的数据进行累加求和,并且最终把数据转化为k3,v3写出去
* @param k2
* @param v2s
* @param context
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void reduce(Text k2, Iterable<LongWritable> v2s, Context context) throws IOException, InterruptedException
//创建一个sum变量,保持v2s的和
long sum = 0L;
for (LongWritable v2:v2s)
//输出k2,v2的值
//System.out.println("<k2,v2>=<"+k2.toString()+","+v2.get()+">");
logger.info("<k2,v2>=<"+k2.toString()+","+v2.get()+">");
sum += v2.get();
//组装k3,v3
Text k3 = k2;
LongWritable v3 = new LongWritable(sum);
//输出k3,v3的值
//System.out.println("<k3,v3>=<"+k3.toString()+","+v3.get()+">");
logger.info("<k3,v3>=<"+k3.toString()+","+v3.get()+">");
//把结果写出去
context.write(k3,v3);
重新编译打包上传,重新提交最新的jar包,这个时候再查看日志就需要到Log Type: syslog中查看日志了。
3、打包
打包失败,一般是目录被占用,按照前面说的方法去处理,这里就不演示了。
mvn clean package -DskipTests
4、上传
先备份下之前jar包
cd /data/soft/jar
mv db_hadoop-1.0-SNAPSHOT-jar-with-dependencies.jar db_hadoop-1.0-SNAPSHOT-jar-with-dependencies.jar_02
然后上传jar包
5、提交任务
hadoop jar db_hadoop-1.0-SNAPSHOT-jar-with-dependencies.jar com.imooc.mr.WordCountJob /test/hello.txt /out3
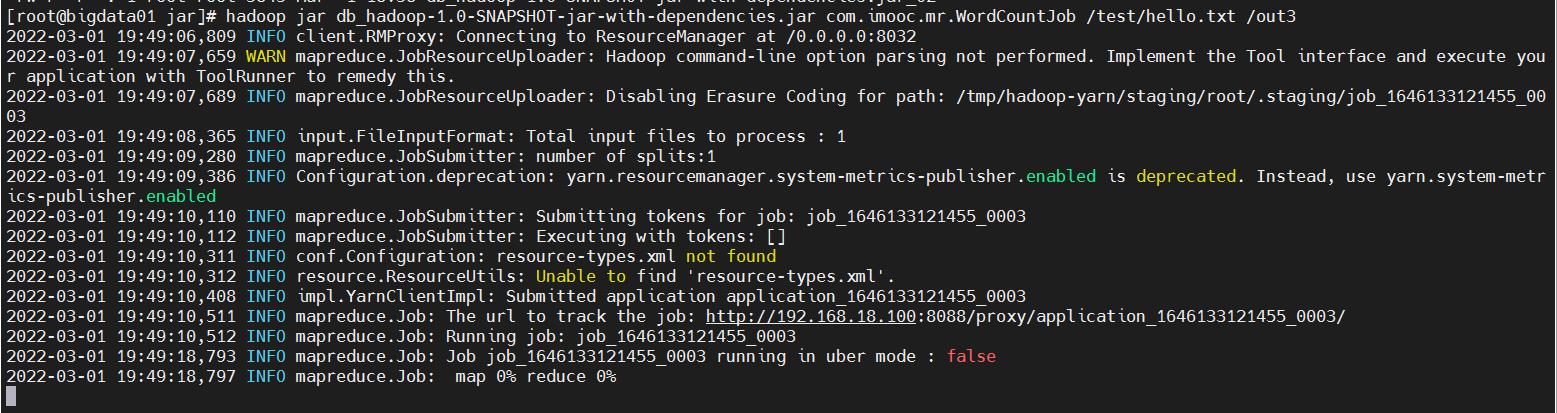
6、查看日志
这个时候再查看日志就需要到Log Type: syslog中查看日志了。
点击History
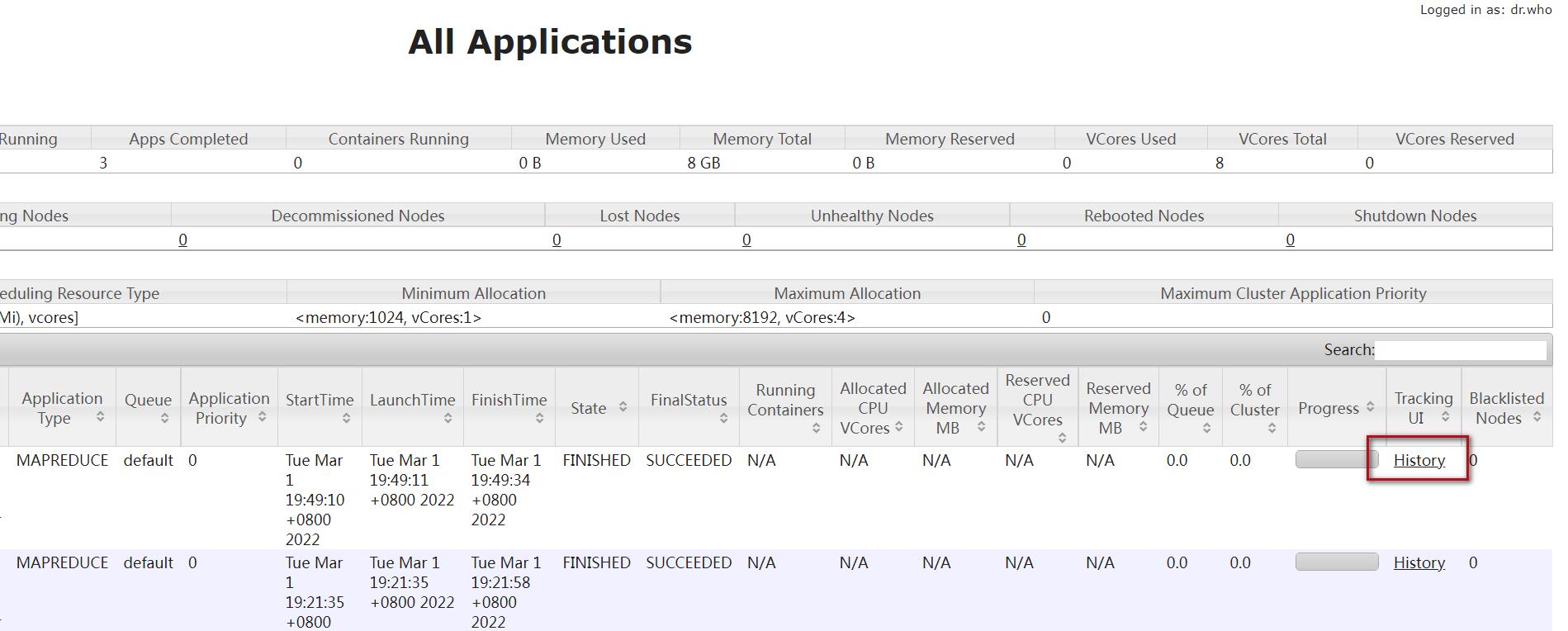
(1)map的日志:
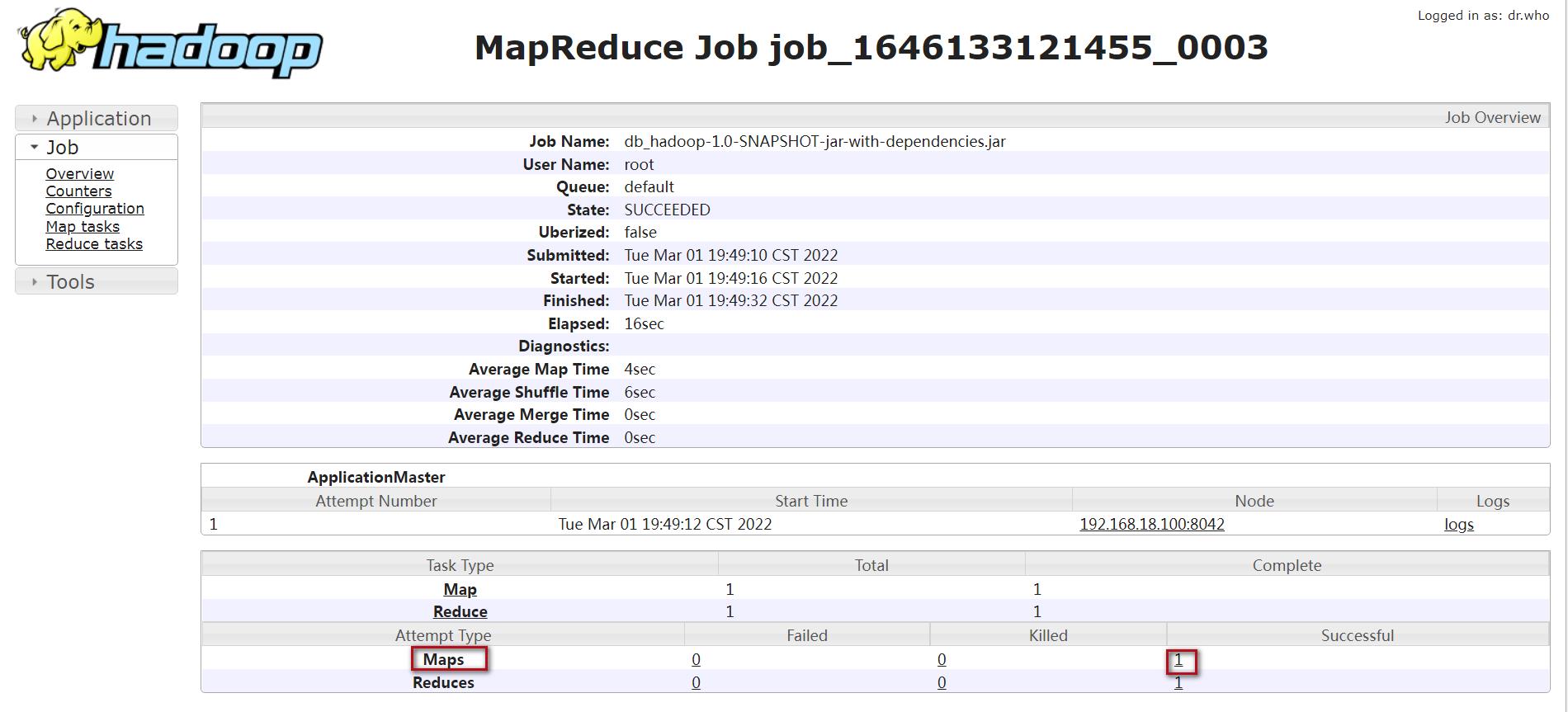
点击logs
找到Log Type: syslog
(2)reduce的日志:
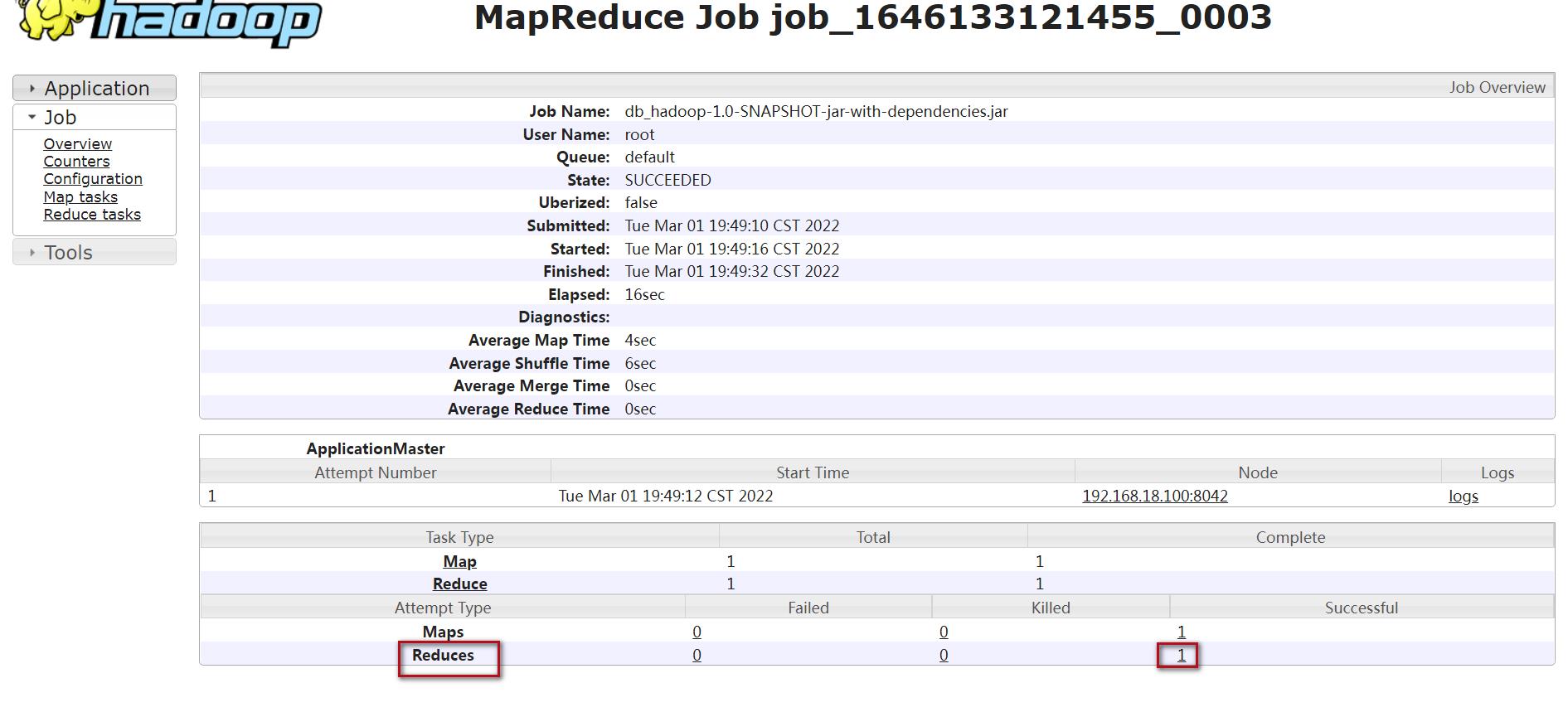
点击logs
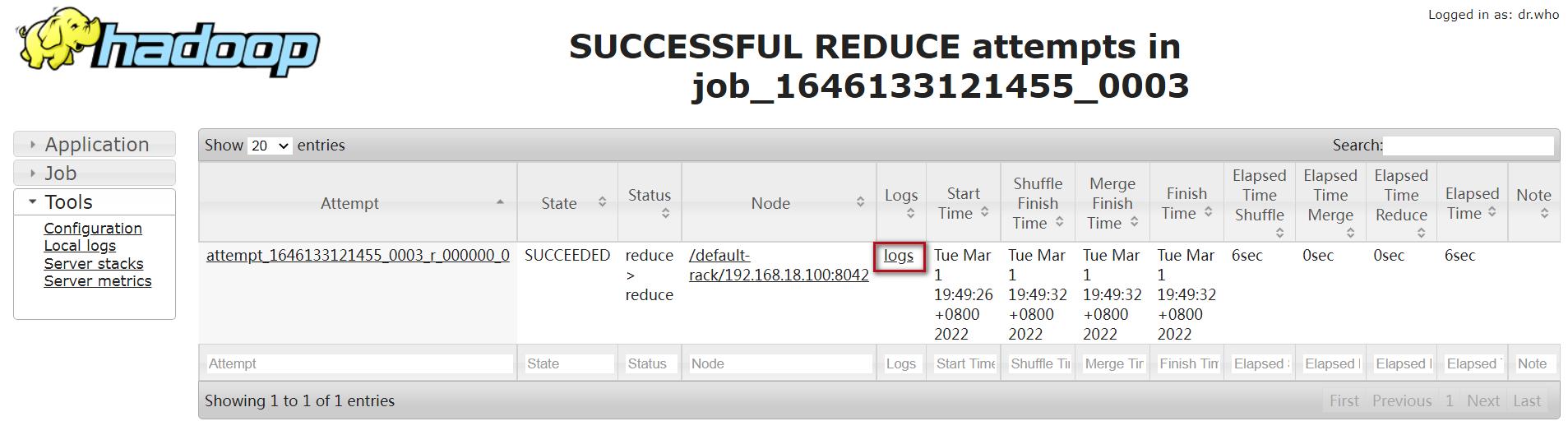
找到Log Type: syslog
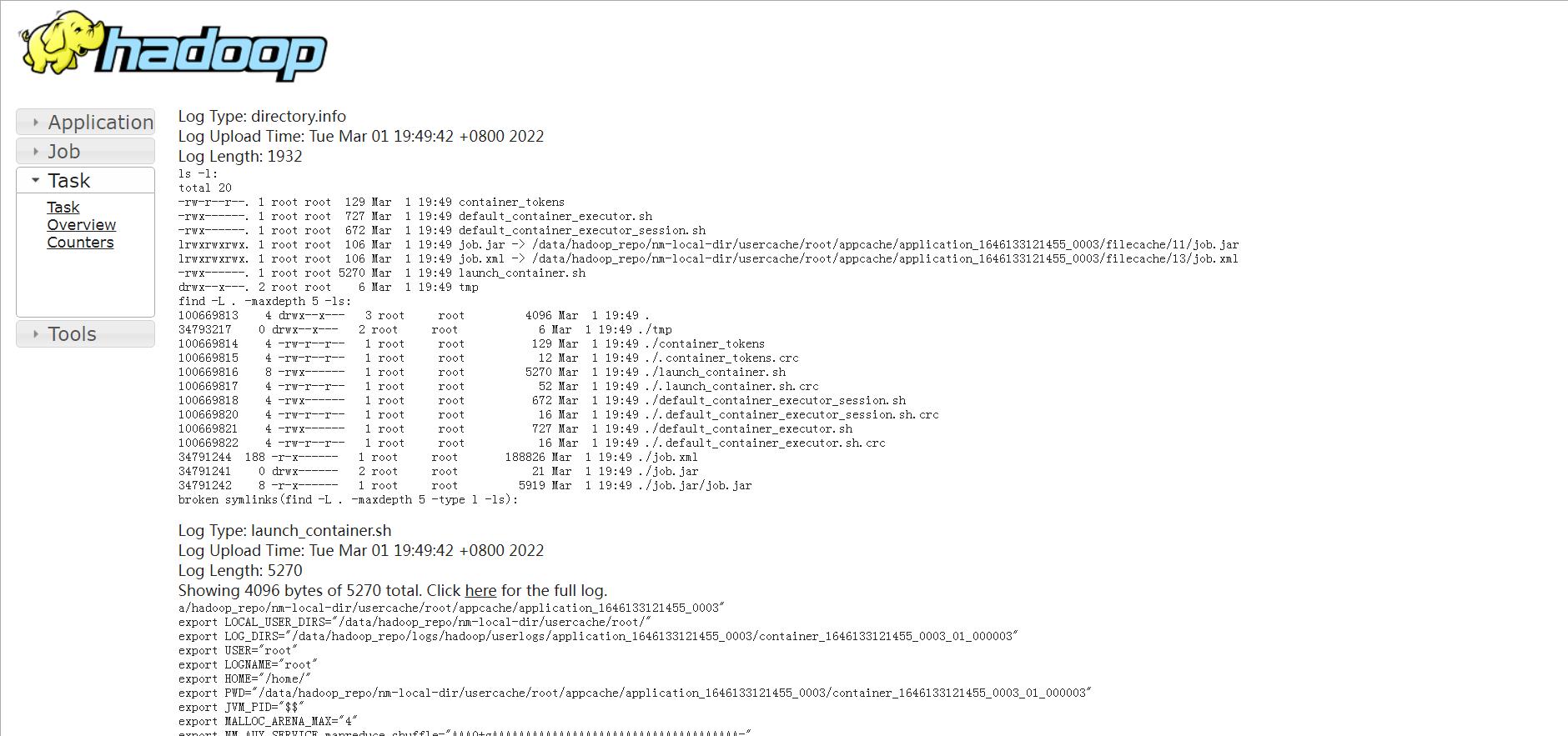
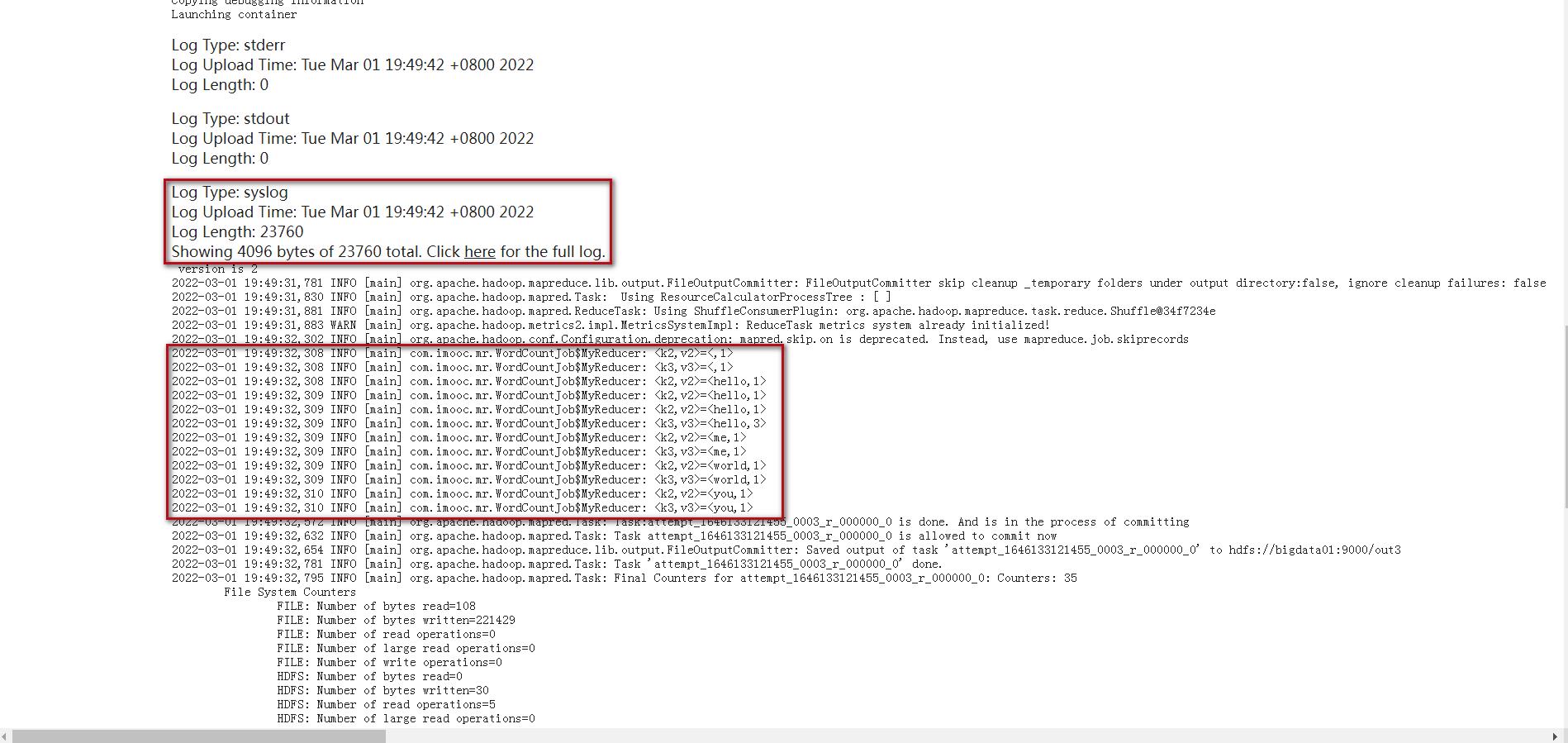
这是工作中比较常用的查看日志的方式
三、其他方式查看日志
但是还有一种使用命令查看的方式,这种方式面试的时候一般喜欢问,如下:
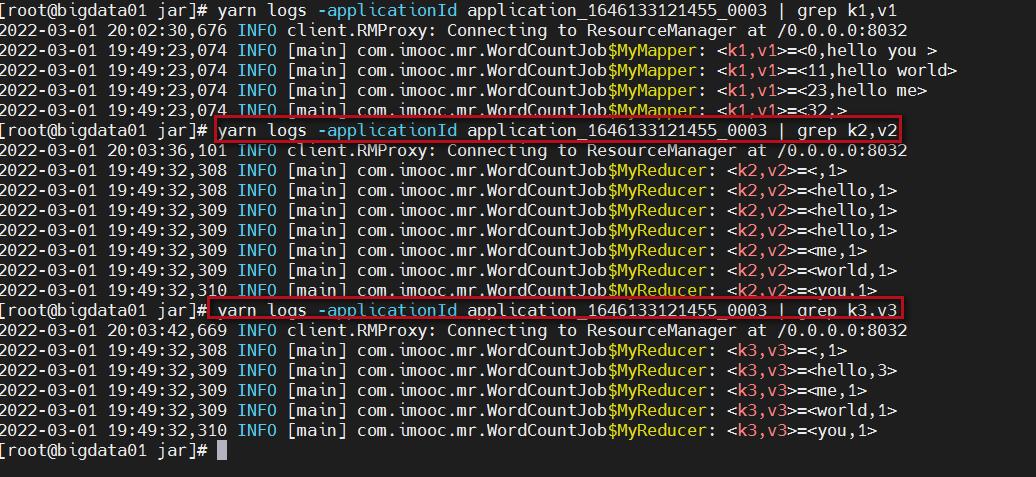
yarn logs -applicationId application_1646133121455_0003
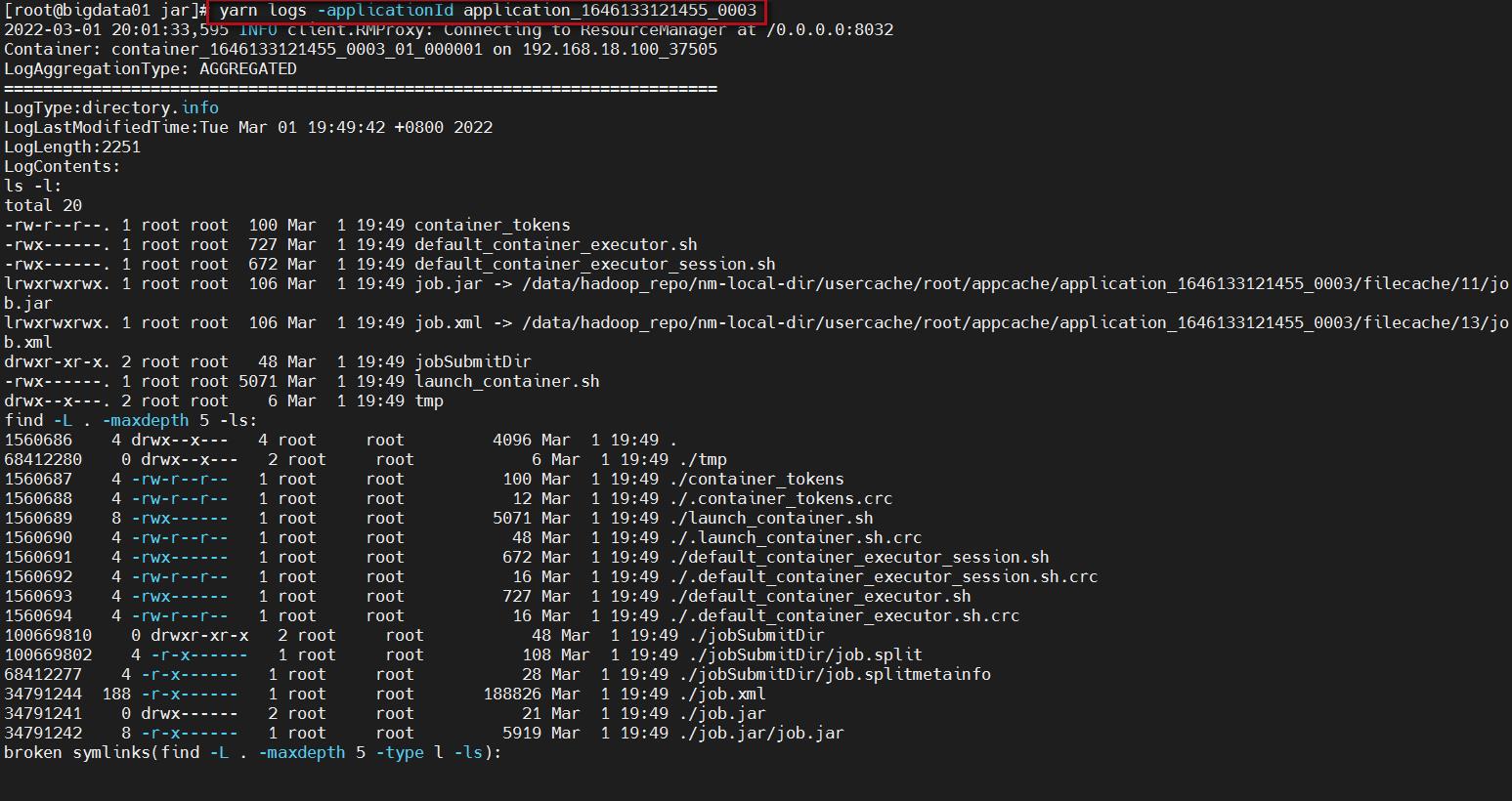
注意:后面指定的是任务id,任务id可以到yarn的web界面上查看。
执行这个命令可以看到很多的日志信息,我们通过grep筛选一下日志。
yarn logs -applicationId application_1646133121455_0003 | grep k1,v1

yarn logs -applicationId application_1646133121455_0003 | grep k2,v2
yarn logs -applicationId application_1646133121455_0003 | grep k3,v3
这种方式也需要大家能够记住并且掌握住,首先是面试的时候可能会问到,还有就是针对某一些艰难的场景下,无法使用yarn的web界面查看日志,就需要使用yarn logs命令了。
补充2个内容:
四、停止Hadoop集群中的任务
如果一个mapreduce任务处理的数据量比较大的话,这个任务会执行很长时间,可能几十分钟或者几个小时都有可能,假设一个场景,任务执行了一半了我们发现我们的代码写的有问题,需要修改代码重新提交执行,这个时候之前的任务就没有必要再执行了,没有任何意义了,最终的结果肯定是错误的,所以我们就想把它停掉,要不然会额外浪费集群的资源,如何停止呢?
我在提交任务的窗口中按ctrl+c是不是就可以停止?
注意了,不是这样的,我们前面说过,这个任务是提交到集群执行的,你在提交任务的窗口中执行ctrl+c对已经提交到集群中的任务是没有任何影响的。
我们可以验证一下,执行ctrl+c之后你再到yarn的8088界面查看,会发现任务依然存在。
所以需要使用hadoop集群的命令去停止正在运行的任务
使用yarn application -kill命令,后面指定任务id即可
yarn application -kill application_1587713567839_0003
五、MapReduce程序扩展
咱们前面说过MapReduce任务是由map阶段和reduce阶段组成的
但是我们也说过,reduce阶段不是必须的,那也就意味着MapReduce程序可以只包含map阶段。
什么场景下会只需要map阶段呢?
当数据只需要进行普通的过滤、解析等操作,不需要进行聚合,这个时候就不需要使用reduce阶段了,在代码层面该如何设置呢?
很简单,在组装Job的时候设置reduce的task数目为0就可以了。并且Reduce代码也不需要写了。
1、代码如下:
package com.imooc.mr;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.io.IOException;
/**
* 只有Map阶段,不包含Reduce阶段
*/
public class WordCountJobNoReduce
/**
* 组装job=map+reduce
* 但这里没有reduce,注意
* @param args
*/
public static void main(String[] args)
try
if (args.length != 2)
//如果传递的参数不够,程序直接退出
System.exit(100);
//job需要的配置参数
Configuration conf = new Configuration();
//创建一个Job
Job job = Job.getInstance(conf);
//注意:这一行必须设置,否则在集群中执行的是找不到WordCountJob这个类
job.setJarByClass(WordCountJobNoReduce.class);
//指定输入路径(可以是文件,也可以是目录)
FileInputFormat.setInputPaths(job,new Path(args[0]));
//指定输出路径(只能指定一个不存在的目录)
FileOutputFormat.setOutputPath(job,new Path(args[1]));
//指定map相关的代码
job.setMapperClass(MyMapper.class);
//指定k2的类型
job.setMapOutputKeyClass(Text.class);
//指定v2的类型
job.setMapOutputValueClass(LongWritable.class);
//禁用reduce阶段
job.setNumReduceTasks(0);
//提交job
job.waitForCompletion(true);
catch (Exception e)
e.printStackTrace();
public static class MyMapper extends Mapper<LongWritable,Text,Text,LongWritable>
Logger logger = LoggerFactory.getLogger(MyMapper.class);
/**
* 需要实现map函数
* 这个map函数就是可以接收k1,v1, 产生k2,v2
* @param k1
* @param v1
* @param context
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void map(LongWritable k1, Text v1, Context context) throws IOException, InterruptedException
//输出k1,v1的值
//System.out.println("<k1,v1>=<"+k1.get()+","+v1.toString()+">");
logger.info("<k1,v1>=<"+k1.get()+","+v1.toString()+">");
// k1代表的是每一行的行首偏移量,v1代表的是每一行内容
// 对获取到的每一行数据进行切割,把单词切割出来
String[] words = v1.toString().split(" ");
//迭代出来的单词数据
for(String word:words)
//把迭代出来的单词封装成<k2,v2>的形式
Text k2 = new Text(word);
LongWritable v2 = new LongWritable(1L);
//把<k2,v2>写出去
context.write(k2,v2);
2、打包上传
打包
mvn clean package -DskipTests

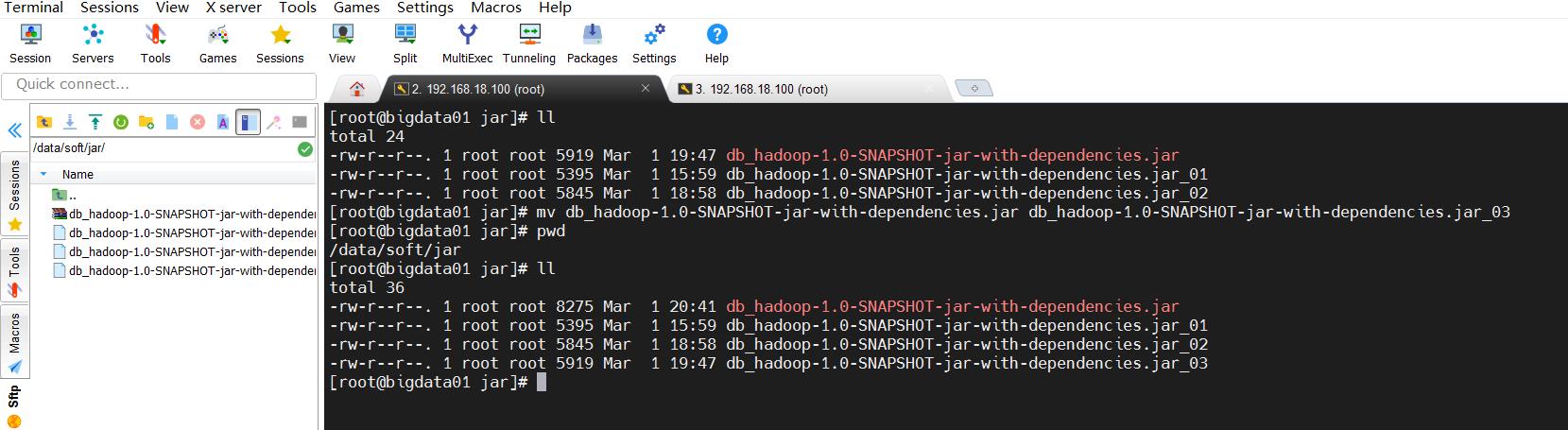
备份下jar包
mv db_hadoop-1.0-SNAPSHOT-jar-with-dependencies.jar db_hadoop-1.0-SNAPSHOT-jar-with-dependencies.jar_03
上传jar包
3、执行任务
hadoop jar db_hadoop-1.0-SNAPSHOT-jar-with-dependencies.jar com.imooc.mr.WordCountJobNoReduce /test/hello.txt /out4
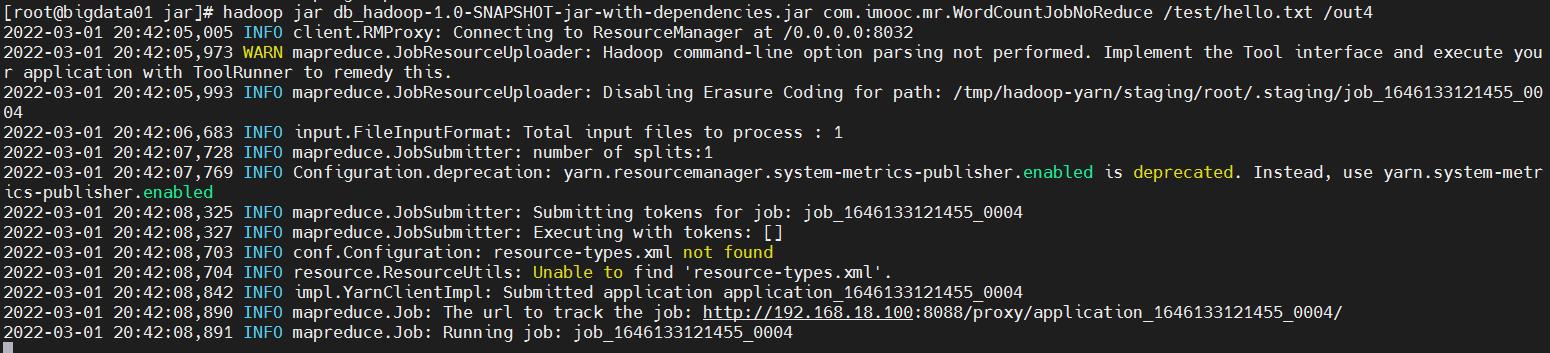
这里发现map执行到100%以后任务就执行成功了,reduce还是0%,因为就没有reduce阶段了。
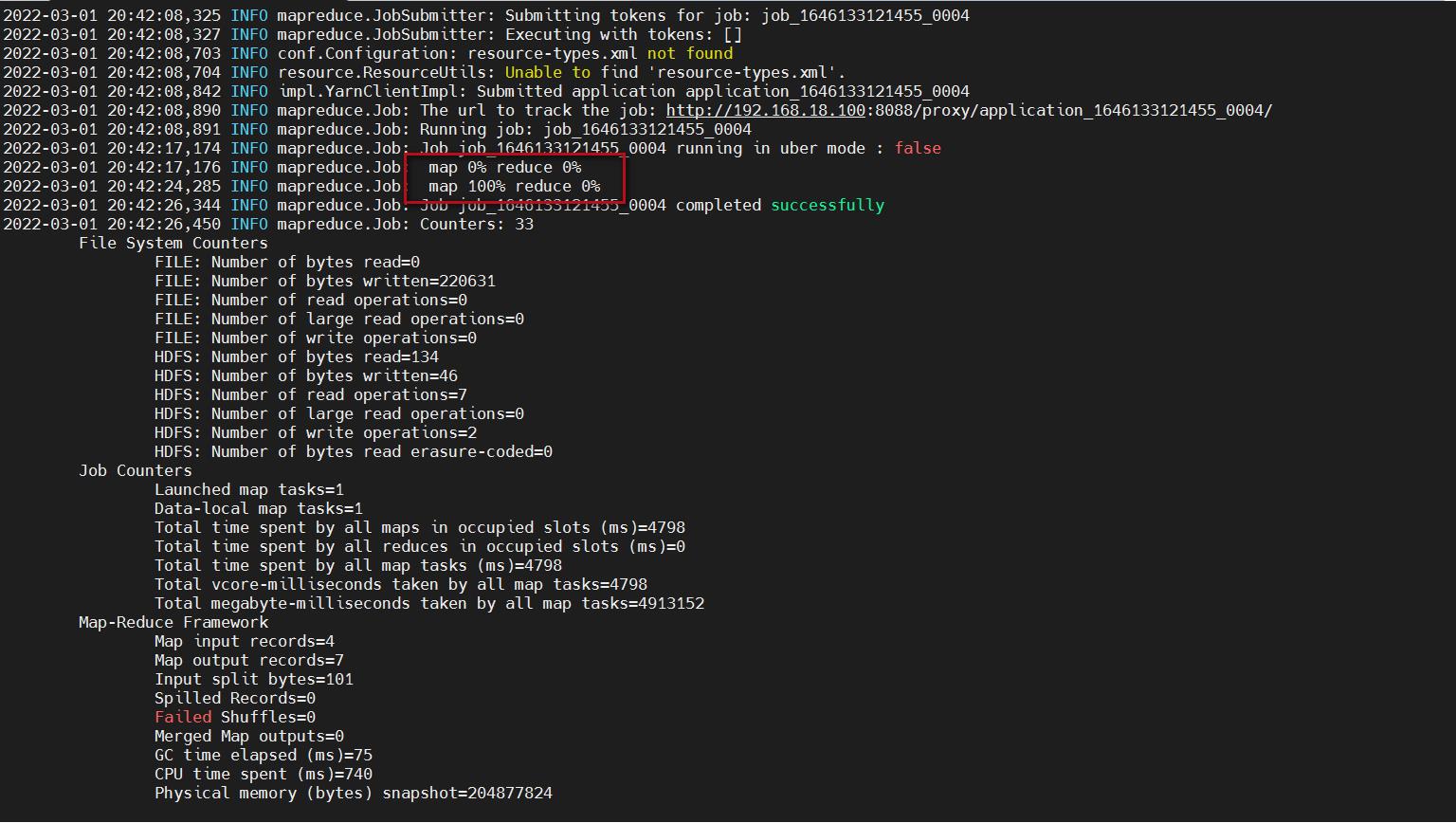
4、查看结果
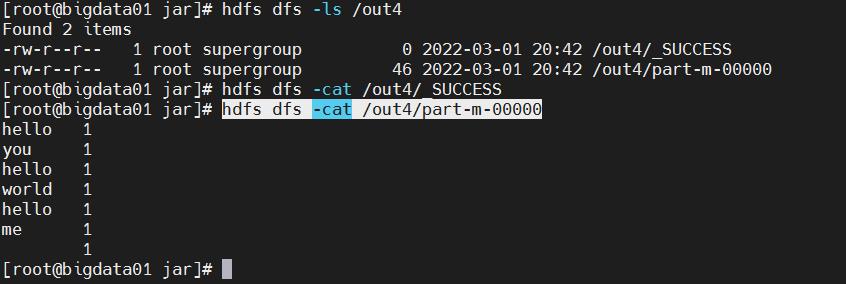
查看输出结果,注意,这里的文件名就是part-m-00000了
hdfs dfs -ls /out4
hdfs dfs -cat /out4/_SUCCESS
hdfs dfs -cat /out4/part-m-00000
5、web页面查看
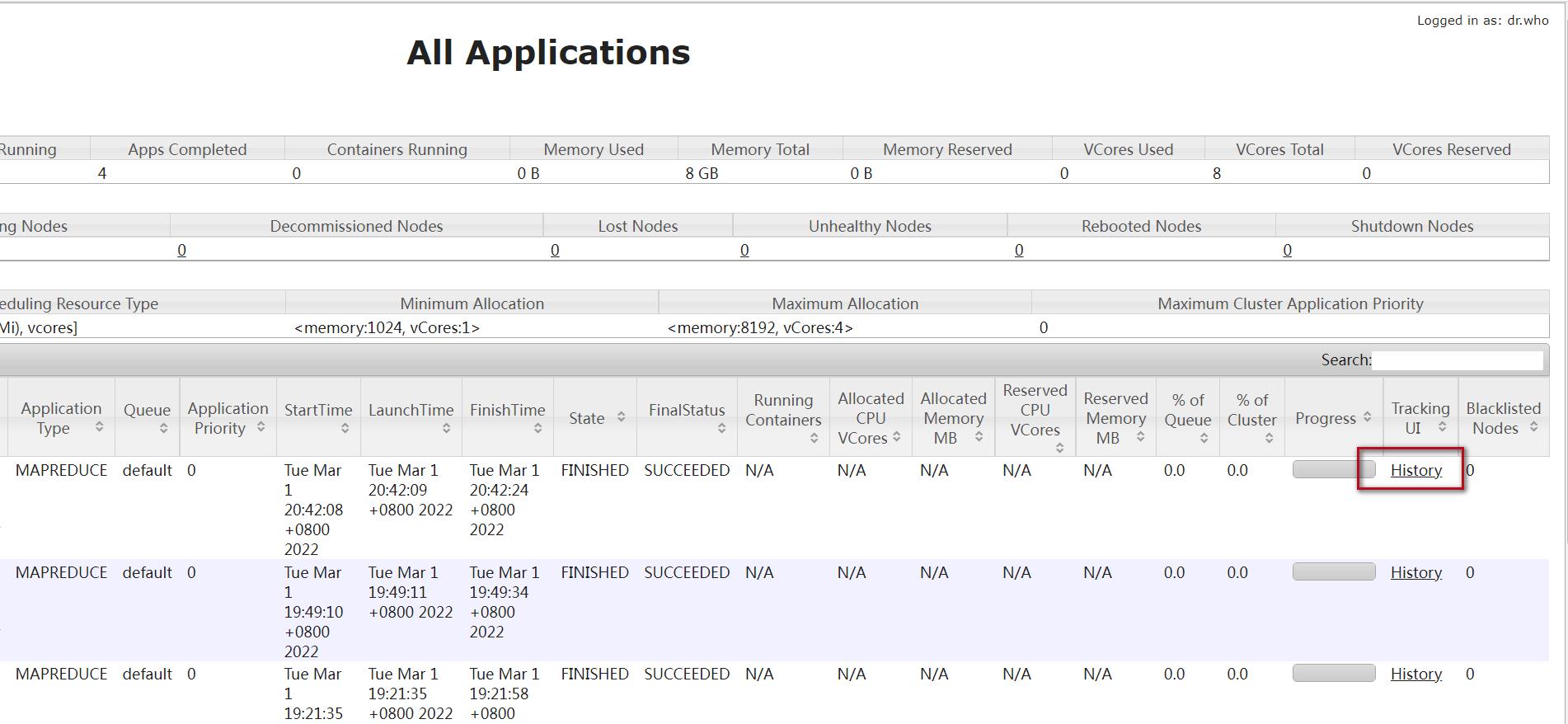
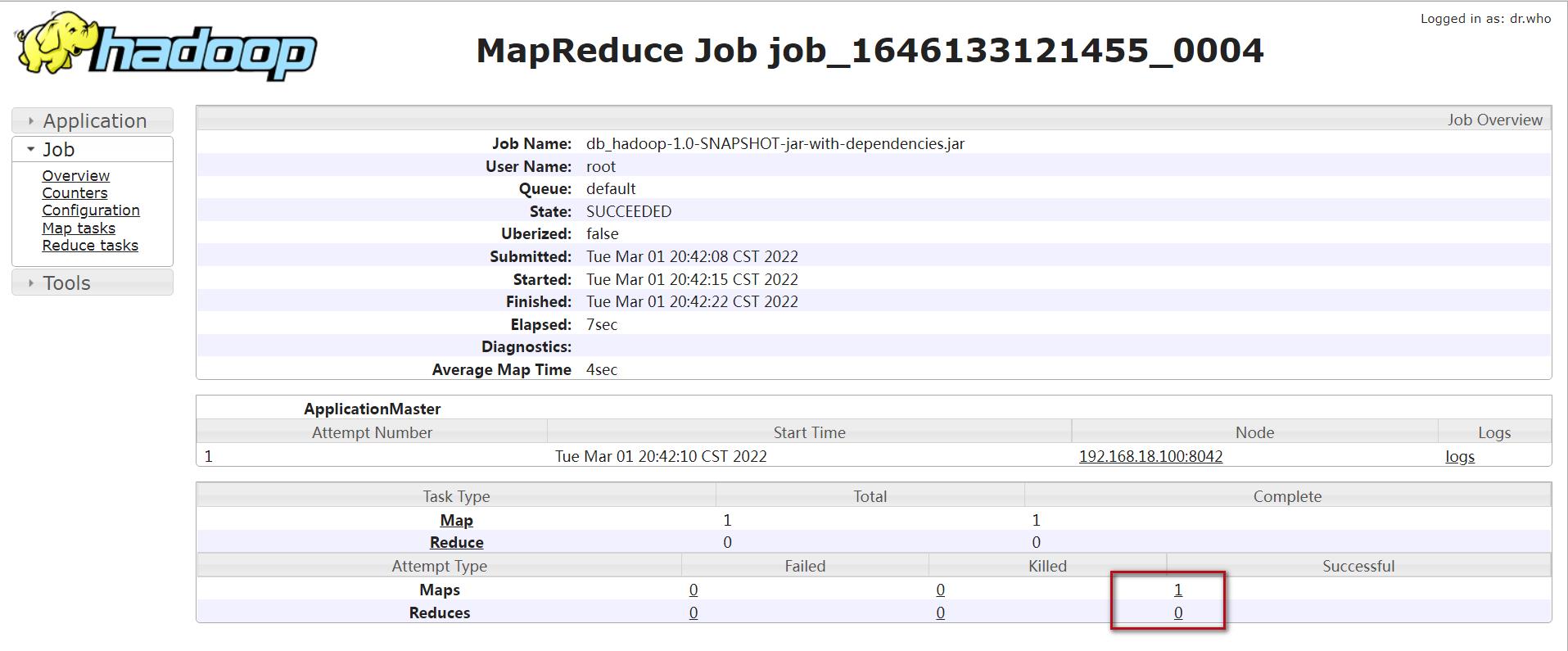
reduce任务为0
以上是关于Hadoop13:案例MapReduce任务日志查看的主要内容,如果未能解决你的问题,请参考以下文章
Hadoop中的MapReduce框架原理WritableComparable排序排序分类WritableComparable排序案例实操(全排序)(二次排序)
Hadoop中的MapReduce框架原理自定义Partitioner步骤在Job驱动中,设置自定义PartitionerPartition 分区案例