Hadoop学习笔记—12.MapReduce中的常见算法
Posted 初见微凉i
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hadoop学习笔记—12.MapReduce中的常见算法相关的知识,希望对你有一定的参考价值。
一、MapReduce中有哪些常见算法
(1)经典之王:单词计数
这个是MapReduce的经典案例,经典的不能再经典了!
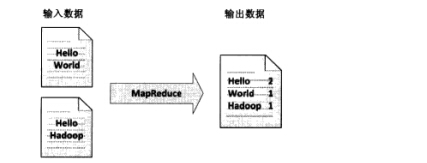
(2)数据去重
"数据去重"主要是为了掌握和利用并行化思想来对数据进行有意义的筛选。统计大数据集上的数据种类个数、从网站日志中计算访问地等这些看似庞杂的任务都会涉及数据去重。

(3)排序:按某个Key进行升序或降序排列
(4)TopK:对源数据中所有数据进行排序,取出前K个数据,就是TopK。

通常可以借助堆(Heap)来实现TopK问题。
(5)选择:关系代数基本操作再现
从指定关系中选择出符合条件的元组(记录)组成一个新的关系。在关系代数中,选择运算是针对元组的运算。

在MapReduce中,以求最大最小值为例,从N行数据中取出一行最小值,这就是一个典型的选择操作。
(6)投影:关系代数基本操作再现
从指定关系的属性(字段)集合中选取部分属性组成同类的一个新关系。由于属性减少而出现的重复元组被自动删除。投影运算针对的是属性。

在MapReduce中,以前面的处理手机上网日志为例,在日志中的11个字段中我们选出了五个字段来显示我们的手机上网流量就是一个典型的投影操作。
(7)分组:Group By XXXX

在MapReduce中,分组类似于分区操作,以处理手机上网日志为例,我们分为了手机号和非手机号这样的两个组来分别处理。
(8)多表连接

(9)单表关联

二、TopK一般类型之前K个问题
TopK问题是一个很常见的实际问题:在一大堆的数据中如何高效地找出前K个最大/最小的数据。我们以前的做法一般是将整个数据文件都加载到内存中,进行排序和统计。但是,当数据文件达到一定量时,这时是无法直接全部加载到内存中的,除非你想冒着宕机的危险。
这时我们想到了分布式计算,利用计算机集群来做这个事,打个比方:本来一台机器需要10小时才能完成的事,现在10台机器并行地来计算,只需要1小时就可以完成。本次我们使用一个随机生成的100万个数字的文件,也就是说我们要做的就是在100万个数中找到最大的前100个数字。
实验数据下载地址:http://pan.baidu.com/s/1qWt4WaS
2.1 利用TreeMap存储前K个数据
(1)红黑树的实现
如何存储前K个数据时TopK问题的一大核心,这里我们采用Java中TreeMap来进行存储。TreeMap的实现是红黑树算法的实现,红黑树又称红-黑二叉树,它首先是一棵二叉树,它具体二叉树所有的特性,同时红黑树更是一棵自平衡的排序二叉树。
平衡二叉树必须具备如下特性:它是一棵空树或它的左右两个子树的高度差的绝对值不超过1,并且左右两个子树都是一棵平衡二叉树。也就是说该二叉树的任何一个等等子节点,其左右子树的高度都相近。

红黑树顾名思义就是:节点是红色或者黑色的平衡二叉树,它通过颜色的约束来维持着二叉树的平衡。

About:关于TreeMap与红黑树的详细介绍可以阅读chenssy的一篇文章:TreeMap与红黑树 ,这里不再赘述。
(2)TreeMap中的put方法
在TreeMap的put()的实现方法中主要分为两个步骤,第一:构建排序二叉树,第二:平衡二叉树。
为了平衡二叉树,往往需要进行左旋和右旋以及着色操作,这里看看左旋和右旋操作,这些操作的目的都是为了维持平衡,保证二叉树是有序的,可以帮助我们实现有序的效果,即数据的存储是有序的。


2.2 编写map和reduce函数代码
(1)map函数

public static class MyMapper extends
Mapper<LongWritable, Text, NullWritable, LongWritable> {
public static final int K = 100;
private TreeMap<Long, Long> tm = new TreeMap<Long, Long>();
protected void map(
LongWritable key,
Text value,
Mapper<LongWritable, Text, NullWritable, LongWritable>.Context context)
throws java.io.IOException, InterruptedException {
try {
long temp = Long.parseLong(value.toString().trim());
tm.put(temp, temp);
if (tm.size() > K) {
tm.remove(tm.firstKey());
// 如果是求topk个最小的那么使用下面的语句
//tm.remove(tm.lastKey());
}
} catch (Exception e) {
context.getCounter("TopK", "errorLog").increment(1L);
}
};
protected void cleanup(
org.apache.hadoop.mapreduce.Mapper<LongWritable, Text, NullWritable, LongWritable>.Context context)
throws java.io.IOException, InterruptedException {
for (Long num : tm.values()) {
context.write(NullWritable.get(), new LongWritable(num));
}
};
}
cleanup()方法是在map方法结束之后才会执行的方法,这里我们将在该map任务中的前100个数据传入reduce任务中;
(2)reduce函数
public static class MyReducer extends
Reducer<NullWritable, LongWritable, NullWritable, LongWritable> {
public static final int K = 100;
private TreeMap<Long, Long> tm = new TreeMap<Long, Long>();
protected void reduce(
NullWritable key,
java.lang.Iterable<LongWritable> values,
Reducer<NullWritable, LongWritable, NullWritable, LongWritable>.Context context)
throws java.io.IOException, InterruptedException {
for (LongWritable num : values) {
tm.put(num.get(), num.get());
if (tm.size() > K) {
tm.remove(tm.firstKey());
// 如果是求topk个最小的那么使用下面的语句
//tm.remove(tm.lastKey());
}
}
// 按降序即从大到小排列Key集合
for (Long value : tm.descendingKeySet()) {
context.write(NullWritable.get(), new LongWritable(value));
}
};
}
在reduce方法中,依次将map方法中传入的数据放入TreeMap中,并依靠红黑色的平衡特性来维持数据的有序性。
(3)完整代码
 View Code
View Code(4)实现效果:图片大小有限,这里只显示了前12个;

三、TopK特殊类型之最值问题
最值问题是一个典型的选择操作,从100万个数字中找到最大或最小的一个数字,在本次实验文件中,最大的数字时32767。现在,我们就来改写代码,找到32767。
3.1 改写map函数
public static class MyMapper extends
Mapper<LongWritable, Text, LongWritable, NullWritable> {
long max = Long.MIN_VALUE;
protected void map(LongWritable key, Text value,
Mapper<LongWritable, Text, LongWritable, NullWritable>.Context context)
throws java.io.IOException, InterruptedException {
long temp = Long.parseLong(value.toString().trim());
if (temp > max) {
max = temp;
}
};
protected void cleanup(
org.apache.hadoop.mapreduce.Mapper<LongWritable, Text, LongWritable, NullWritable>.Context context)
throws java.io.IOException, InterruptedException {
context.write(new LongWritable(max), NullWritable.get());
};
}
是不是很熟悉?其实就是依次与假设的最大值进行比较。
3.2 改写reduce函数
public static class MyReducer extends
Reducer<LongWritable, NullWritable, LongWritable, NullWritable> {
long max = Long.MIN_VALUE;
protected void reduce(
LongWritable key,
java.lang.Iterable<NullWritable> values,
Reducer<LongWritable, NullWritable, LongWritable, NullWritable>.Context context)
throws java.io.IOException, InterruptedException {
long temp = key.get();
if (temp > max) {
max = temp;
}
};
protected void cleanup(
org.apache.hadoop.mapreduce.Reducer<LongWritable, NullWritable, LongWritable, NullWritable>.Context context)
throws java.io.IOException, InterruptedException {
context.write(new LongWritable(max), NullWritable.get());
};
}
在reduce方法中,继续对各个map任务传入的数据进行比较,还是依次地与假设的最大值进行比较,最后所有reduce方法执行完成后通过cleanup方法对最大值进行输出。
最终的完整代码如下:
View Code3.3 查看实现效果

可以看出,我们的程序已经求出了最大值:32767。虽然例子很简单,业务也很简单,但是我们引入了分布式计算的思想,将MapReduce应用在了最值问题之中,就是一个进步了!
参考资料
(1)吴超,《深入浅出Hadoop》:http://www.superwu.cn/
(2)Suddenly,《Hadoop日记Day18-MapReduce排序和分组》:http://www.cnblogs.com/sunddenly/p/4009751.html
(3)chenssy,《Java提高篇(27)—TreeMap》:http://blog.csdn.net/chenssy/article/details/26668941
以上是关于Hadoop学习笔记—12.MapReduce中的常见算法的主要内容,如果未能解决你的问题,请参考以下文章