Hadoop集群(第9期)_MapReduce初级案例
Posted 受伤滴小萝卜
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hadoop集群(第9期)_MapReduce初级案例相关的知识,希望对你有一定的参考价值。
1、数据去重
"数据去重"主要是为了掌握和利用并行化思想来对数据进行有意义的筛选。统计大数据集上的数据种类个数、从网站日志中计算访问地等这些看似庞杂的任务都会涉及数据去重。下面就进入这个实例的MapReduce程序设计。
1.1 实例描述
对数据文件中的数据进行去重。数据文件中的每行都是一个数据。
样例输入如下所示:
1)file1:
2012-3-1 a
2012-3-2 b
2012-3-3 c
2012-3-4 d
2012-3-5 a
2012-3-6 b
2012-3-7 c
2012-3-3 c
2)file2:
2012-3-1 b
2012-3-2 a
2012-3-3 b
2012-3-4 d
2012-3-5 a
2012-3-6 c
2012-3-7 d
2012-3-3 c
样例输出如下所示:
2012-3-1 a
2012-3-1 b
2012-3-2 a
2012-3-2 b
2012-3-3 b
2012-3-3 c
2012-3-4 d
2012-3-5 a
2012-3-6 b
2012-3-6 c
2012-3-7 c
2012-3-7 d
1.2 设计思路
数据去重的最终目标是让原始数据中出现次数超过一次的数据在输出文件中只出现一次。我们自然而然会想到将同一个数据的所有记录都交给一台reduce机器,无论这个数据出现多少次,只要在最终结果中输出一次就可以了。具体就是reduce的输入应该以数据作为key,而对value-list则没有要求。当reduce接收到一个<key,value-list>时就直接将key复制到输出的key中,并将value设置成空值。
在MapReduce流程中,map的输出<key,value>经过shuffle过程聚集成<key,value- list>后会交给reduce。所以从设计好的reduce输入可以反推出map的输出key应为数据,value任意。继续反推,map输出数 据的key为数据,而在这个实例中每个数据代表输入文件中的一行内容,所以map阶段要完成的任务就是在采用Hadoop默认的作业输入方式之后,将 value设置为key,并直接输出(输出中的value任意)。map中的结果经过shuffle过程之后交给reduce。reduce阶段不会管每 个key有多少个value,它直接将输入的key复制为输出的key,并输出就可以了(输出中的value被设置成空了)。
1.3 程序代码
程序代码如下所示:
package com.hebut.mr;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class Dedup {
//map将输入中的value复制到输出数据的key上,并直接输出
public static class Map extends Mapper<Object,Text,Text,Text>{
private static Text line=new Text();//每行数据
//实现map函数
public void map(Object key,Text value,Context context)
throws IOException,InterruptedException{
line=value;
context.write(line, new Text(""));
}
}
//reduce将输入中的key复制到输出数据的key上,并直接输出
public static class Reduce extends Reducer<Text,Text,Text,Text>{
//实现reduce函数
public void reduce(Text key,Iterable<Text> values,Context context)
throws IOException,InterruptedException{
context.write(key, new Text(""));
}
}
public static void main(String[] args) throws Exception{
Configuration conf = new Configuration();
//这句话很关键
conf.set("mapred.job.tracker", "192.168.1.2:9001");
String[] ioArgs=new String[]{"dedup_in","dedup_out"};
String[] otherArgs = new GenericOptionsParser(conf, ioArgs).getRemainingArgs();
if (otherArgs.length != 2) {
System.err.println("Usage: Data Deduplication <in> <out>");
System.exit(2);
}
Job job = new Job(conf, "Data Deduplication");
job.setJarByClass(Dedup.class);
//设置Map、Combine和Reduce处理类
job.setMapperClass(Map.class);
job.setCombinerClass(Reduce.class);
job.setReducerClass(Reduce.class);
//设置输出类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
//设置输入和输出目录
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
1.4 代码结果
1)准备测试数据
通过Eclipse下面的"DFS Locations"在"/user/hadoop"目录下创建输入文件"dedup_in"文件夹(备注:"dedup_out"不需要创建。)如图1.4-1所示,已经成功创建。
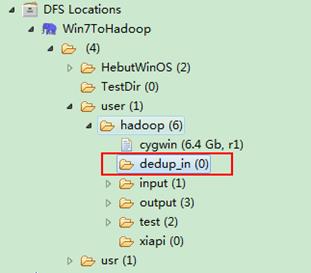
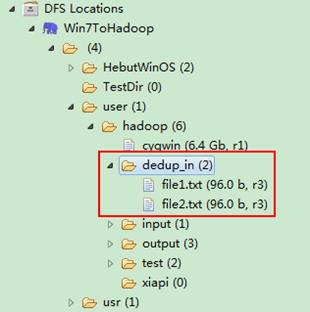
图1.4-1 创建"dedup_in" 图1.4.2 上传"file*.txt"
然后在本地建立两个txt文件,通过Eclipse上传到"/user/hadoop/dedup_in"文件夹中,两个txt文件的内容如"实例描述"那两个文件一样。如图1.4-2所示,成功上传之后。
从SecureCRT远处查看"Master.Hadoop"的也能证实我们上传的两个文件。

查看两个文件的内容如图1.4-3所示:
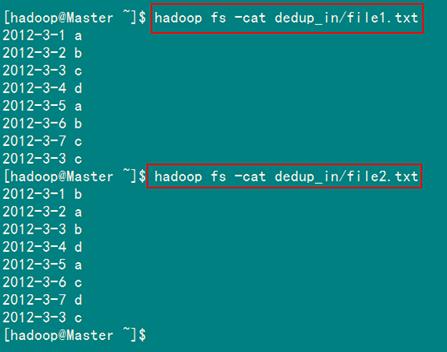
图1.4-3 文件"file*.txt"内容
2)查看运行结果
这时我们右击Eclipse 的"DFS Locations"中"/user/hadoop"文件夹进行刷新,这时会发现多出一个"dedup_out"文件夹,且里面有3个文件,然后打开双 其"part-r-00000"文件,会在Eclipse中间把内容显示出来。如图1.4-4所示。
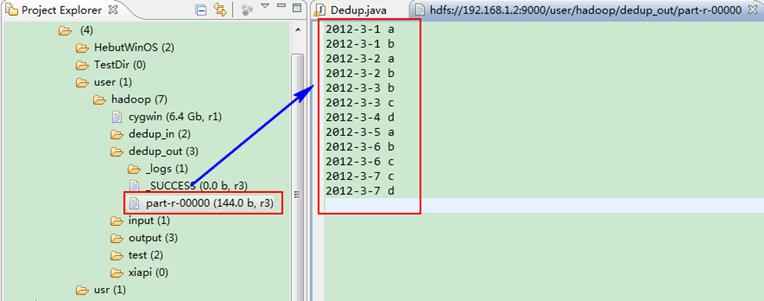
图1.4-4 运行结果
此时,你可以对比一下和我们之前预期的结果是否一致。
2、数据排序
"数据排序"是许多实际任务执行时要完成的第一项工作,比如学生成绩评比、数据建立索引等。这个实例和数据去重类似,都是先对原始数据进行初步处理,为进一步的数据操作打好基础。下面进入这个示例。
2.1 实例描述
对输入文件中数据进行排序。输入文件中的每行内容均为一个数字,即一个数据。要求在输出中每行有两个间隔的数字,其中,第一个代表原始数据在原始数据集中的位次,第二个代表原始数据。
样例输入:
1)file1:
2
32
654
32
15
756
65223
2)file2:
5956
22
650
92
3)file3:
26
54
6
样例输出:
1 2
2 6
3 15
4 22
5 26
6 32
7 32
8 54
9 92
10 650
11 654
12 756
13 5956
14 65223
2.2 设计思路
这个实例仅仅要求对输入数据进行排序,熟悉MapReduce过程的读者会很快想到在MapReduce过程中就有排序,是否可以利用这个默认的排序,而不需要自己再实现具体的排序呢?答案是肯定的。
但是在使用之前首先需要了解它的默认排序规则。它是按照key值进行排序的,如果key为封装int的IntWritable类型,那么MapReduce按照数字大小对key排序,如果key为封装为String的Text类型,那么MapReduce按照字典顺序对字符串排序。
了解了这个细节,我们就知道应该使用封装int的IntWritable型数据结构了。也就是在map中将读入的数据转化成 IntWritable型,然后作为key值输出(value任意)。reduce拿到<key,value-list>之后,将输入的 key作为value输出,并根据value-list中元素的个数决定输出的次数。输出的key(即代码中的linenum)是一个全局变量,它统计当前key的位次。需要注意的是这个程序中没有配置Combiner,也就是在MapReduce过程中不使用Combiner。这主要是因为使用map和reduce就已经能够完成任务了。
2.3 程序代码
程序代码如下所示:
package com.hebut.mr;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class Sort {
//map将输入中的value化成IntWritable类型,作为输出的key
public static class Map extends
Mapper<Object,Text,IntWritable,IntWritable>{
private static IntWritable data=new IntWritable();
//实现map函数
public void map(Object key,Text value,Context context)
throws IOException,InterruptedException{
String line=value.toString();
data.set(Integer.parseInt(line));
context.write(data, new IntWritable(1));
}
}
//reduce将输入中的key复制到输出数据的key上,
//然后根据输入的value-list中元素的个数决定key的输出次数
//用全局linenum来代表key的位次
public static class Reduce extends
Reducer<IntWritable,IntWritable,IntWritable,IntWritable>{
private static IntWritable linenum = new IntWritable(1);
//实现reduce函数
public void reduce(IntWritable key,Iterable<IntWritable> values,Context context)
throws IOException,InterruptedException{
for(IntWritable val:values){
context.write(linenum, key);
linenum = new IntWritable(linenum.get()+1);
}
}
}
public static void main(String[] args) throws Exception{
Configuration conf = new Configuration();
//这句话很关键
conf.set("mapred.job.tracker", "192.168.1.2:9001");
String[] ioArgs=new String[]{"sort_in","sort_out"};
String[] otherArgs = new GenericOptionsParser(conf, ioArgs).getRemainingArgs();
if (otherArgs.length != 2) {
System.err.println("Usage: Data Sort <in> <out>");
System.exit(2);
}
Job job = new Job(conf, "Data Sort");
job.setJarByClass(Sort.class);
//设置Map和Reduce处理类
job.setMapperClass(Map.class);
job.setReducerClass(Reduce.class);
//设置输出类型
job.setOutputKeyClass(IntWritable.class);
job.setOutputValueClass(IntWritable.class);
//设置输入和输出目录
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
2.4 代码结果
1)准备测试数据
通过Eclipse下面的"DFS Locations"在"/user/hadoop"目录下创建输入文件"sort_in"文件夹(备注:"sort_out"不需要创建。)如图2.4-1所示,已经成功创建。


图2.4-1 创建"sort_in" 图2.4.2 上传"file*.txt"
然后在本地建立三个txt文件,通过Eclipse上传到"/user/hadoop/sort_in"文件夹中,三个txt文件的内容如"实例描述"那三个文件一样。如图2.4-2所示,成功上传之后。
从SecureCRT远处查看"Master.Hadoop"的也能证实我们上传的三个文件。

查看两个文件的内容如图2.4-3所示:
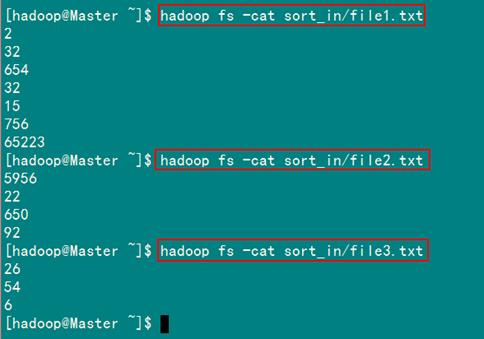
图2.4-3 文件"file*.txt"内容
2)查看运行结果
这时我们右击Eclipse 的"DFS Locations"中"/user/hadoop"文件夹进行刷新,这时会发现多出一个"sort_out"文件夹,且里面有3个文件,然后打开双 其"part-r-00000"文件,会在Eclipse中间把内容显示出来。如图2.4-4所示。

图2.4-4 运行结果
3、平均成绩
"平均成绩"主要目的还是在重温经典"WordCount"例子,可以说是在基础上的微变化版,该实例主要就是实现一个计算学生平均成绩的例子。
3.1 实例描述
对输入文件中数据进行就算学生平均成绩。输入文件中的每行内容均为一个学生的姓名和他相应的成绩,如果有多门学科,则每门学科为一个文件。要求在输出中每行有两个间隔的数据,其中,第一个代表学生的姓名,第二个代表其平均成绩。
样本输入:
1)math:
张三 88
李四 99
王五 66
赵六 77
2)china:
张三 78
李四 89
王五 96
赵六 67
3)english:
张三 80
李四 82
王五 84
赵六 86
样本输出:
张三 82
李四 90
王五 82
赵六 76
3.2 设计思路
计算学生平均成绩是一个仿"WordCount"例子,用来重温一下开发MapReduce程序的流程。程序包括两部分的内容:Map部分和Reduce部分,分别实现了map和reduce的功能。
Map处理的是一个纯文本文件, 文件中存放的数据时每一行表示一个学生的姓名和他相应一科成绩。Mapper处理的数据是由InputFormat分解过的数据集,其中 InputFormat的作用是将数据集切割成小数据集InputSplit,每一个InputSlit将由一个Mapper负责处理。此 外,InputFormat中还提供了一个RecordReader的实现,并将一个InputSplit解析成<key,value>对提 供给了map函数。InputFormat的默认值是TextInputFormat,它针对文本文件,按行将文本切割成InputSlit,并用 LineRecordReader将InputSplit解析成<key,value>对,key是行在文本中的位置,value是文件中的 一行。
Map的结果会通过partion分发到Reducer,Reducer做完Reduce操作后,将通过以格式OutputFormat输出。
Mapper最终处理的结果对<key,value>,会送到Reducer中进行合并,合并的时候,有相同key的键/值对则送到同一个 Reducer上。Reducer是所有用户定制Reducer类地基础,它的输入是key和这个key对应的所有value的一个迭代器,同时还有 Reducer的上下文。Reduce的结果由Reducer.Context的write方法输出到文件中。
3.3 程序代码
程序代码如下所示:
package com.hebut.mr;
import java.io.IOException;
import java.util.Iterator;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class Score {
public static class Map extends
Mapper<LongWritable, Text, Text, IntWritable> {
// 实现map函数
public void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
// 将输入的纯文本文件的数据转化成String
String line = value.toString();
// 将输入的数据首先按行进行分割
StringTokenizer tokenizerArticle = new StringTokenizer(line, "\\n");
// 分别对每一行进行处理
while (tokenizerArticle.hasMoreElements()) {
// 每行按空格划分
以上是关于Hadoop集群(第9期)_MapReduce初级案例的主要内容,如果未能解决你的问题,请参考以下文章