论文学习——《Learning to Compose with Professional Photographs on the Web》 (ACM MM 2017)
Posted 悦悦的小屋
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了论文学习——《Learning to Compose with Professional Photographs on the Web》 (ACM MM 2017)相关的知识,希望对你有一定的参考价值。
总结
1.这篇论文的思路基于一个简单的假设:专业摄影师拍出来的图片一般具备比较好的构图,而如果从他们的图片中随机抠出一块,那抠出的图片大概率就毁了。也就是说,原图在构图方面的分数应该高于抠出来的图片。而这种比较的方式,可以很方便地用 Siamese Network 和 hinge loss 实现,如下图所示。

2.另外,这篇论文另一个讨人喜欢的地方在于,它几乎不需要标注数据,只需要在网上爬取很多专业图片,再随机抠图就可以快速构造大量训练样本,因此成本近乎为零,即使精度不高也可以接受,其中作者将数据保存在了dataset.pkl里。
这篇论文的训练方式只能让网络知道哪种图片的构图好,而无法自动从原图中抠出构图好的图块,因此,在抠图方面,采用的是sliding window search strategy滑动窗口策略,并根据网络输出的分数决定哪个窗口最好。
细节
1.dataset.pkl是数据集信息,来自Flickr website,它是一个长度为294644的列表,包含了21046张原图的14个裁剪图,其中scale为0.5、0.6的border crops各4个,scale为0.7、0.8的square crops各3个,作者公开的代码里,目的就是从这14个裁剪图中,选出裁剪效果最好的一个,dataset.pkl数据结构如下面两个图所示;
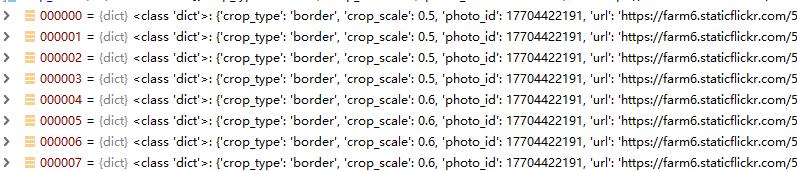
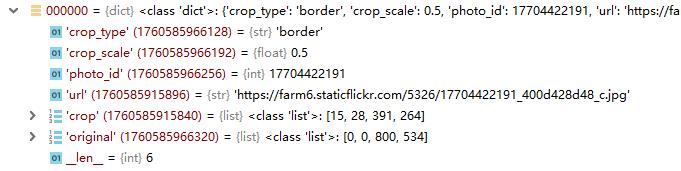
2.VFN(View Finding Network)结构
VFN的网络结构如下图所示,VFN的卷积层采用了AlexNet,然后,将卷积层的输出送入两个全连接层,然后是一个排列层(ranking layer)。该排列层是无参数的,且仅用于评估图像对的hinge loss。在训练过程中,模型更新其参数,使得Φ(·)最小化式(2)中的总排名损失。一旦网络被训练,我们抛弃了排名层,简单地使用Φ(·)将给定的图像I映射到一个美学评分,这个评分将I与其他视觉上相似的视图区分开来。在最后一个卷积层的顶部,附加了一个空间金字塔池(SPP)层。并且该文在VFN中使用固定大小的输入图像(例如,输入图像/patch首先被调整为227)。简单地应用SPP技术来实现对卷积激活特性的数据聚合。
该文选择了3*3、5*5、7*7的池化尺寸池,且步幅stride要小于池化层尺寸。多分辨率池过滤器以不同的尺度保留组合信息。另外,该文通过实证发现,如果没有SPP,模型的特征空间越大,越容易出现过拟合。该文在实验中同时使用了最大池和平均池。
池化层特征是12,544维,然后送入第一个全连接层;fc1后面是ReLU,其输出维度为1,000。由于排序问题不像物体分类那么复杂,所以我们选择相对较小的特征维数;此外,卷积激活特征可以在压缩时不造成较大的信息丢失,而宽的全连接层往往会出现过拟合。fc2只有一个神经元,只输出最终的排名分数。
为了训练网络,使用了带动量momentum的随机梯度下降算法。从在ImageNet ILSVRC2012数据集上预先训练的AlexNet开始,随机初始化全连接层。动量设置为0.9,学习速率从0.01开始,经过10,000次迭代后降低到0.002,每个小批量包含100个图像对。总共运行15,000次迭代用于训练,每1,000次迭代评估验证集。选择验证误差最小的模型进行测试。为了对抗过拟合,训练数据通过随机水平翻转以及亮度和对比度的轻微随机扰动来增强。使用TensorFlow框架来实现和训练我们的模型。


3.评价标准
(1)average intersection-over-union (IoU)
def overlap_ratio(x1, y1, w1, h1, x2, y2, w2, h2): intersection = max(0, min(x1 + w1, x2 + w2) - max(x1, x2)) * max(0, min(y1 + h1, y2 + h2) - max(y1, y2)) union = (w1 * h1) + (w2 * h2) - intersection return float(intersection) / float(union)
(2)average boundary displacement
boundary_displacement = (abs(best_x - x) + abs(best_x + best_w - x - w))/float(width) + (abs(best_y - y) + abs(best_y + best_h - y - h))/float(height)
参考博客:
“Learning to Compose with Professional Photographs on the Web" 论文解读(一)(附代码与详细注释)
“Learning to Compose with Professional Photographs on the Web”论文解读(二)(附代码与详细注释)
以上是关于论文学习——《Learning to Compose with Professional Photographs on the Web》 (ACM MM 2017)的主要内容,如果未能解决你的问题,请参考以下文章
论文学习——《Learning to Compose with Professional Photographs on the Web》 (ACM MM 2017)
论文学习:Learning to Generate Time-Lapse Videos Using Multi-StageDynamic Generative Adversarial Networks
Transfer Learning from Speaker Verification to Multispeaker Text-To-Speech Synthesis论文阅读
论文《learning to link with wikipedia》
论文阅读笔记《Residual Physics Learning and System Identification for Sim to real Transfer of Policies on B