论文阅读笔记《Residual Physics Learning and System Identification for Sim to real Transfer of Policies on B
Posted 垆边画船听雨眠
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了论文阅读笔记《Residual Physics Learning and System Identification for Sim to real Transfer of Policies on B相关的知识,希望对你有一定的参考价值。
Residual Physics Learning and System Identification for Sim to real Transfer of Policies on Buoyancy Assisted Legged Robots
发表于2023年。论文较新,未找到发表期刊。
基于浮力辅助的足式机器人策略迁移的残差物理学习与系统识别
Sontakke N, Chae H, Lee S, et al. Residual physics learning and system identification for sim-to-real transfer of policies on buoyancy assisted legged robots[J]. arXiv preprint arXiv:2303.09597, 2023.
介绍
传统的移动机器人往往是刚性且笨重的,在控制或感知错误的情况下可能会对其周围环境或自身造成严重损害。浮力辅助或气球为基础的机器人可以在人类环境中保证基本的安全,可用于需要密切人机交互的应用领域,例如教育、娱乐和医疗保健。
然而,由于其独特的、非线性的、敏感的动力学特性,特别是针对这类机器人非线性、敏感的动力学特点,传统的控制方法并不适用。深度强化学习则面临着模拟与现实环境之间存在的差距问题。
为了解决这个问题,作者提出了一种新的技术EnvMimic,并证明了EnvMimic技术可以成功地缩小BALLU机器人在模拟和现实环境中的差距。
方法
首先,作者通过识别电机和关节角度之间的非线性关系来改善电缆驱动执行模型的仿真模型。
接下来,作者使用捕获的真实世界轨迹来建立BALLU机器人的残余动力学模型,这是由各种来源引起的,例如空气动力学、关节松弛和惯性参数不匹配等。
本文的关键创新点是使用深度强化学习来构建残余动力学模型,而不是普遍选择监督学习,这提供了对少量轨迹的有效泛化。
背景:BALLU机器人
BALLU是一款具有六个氦气球的新型浮力辅助双足机器人。BALLU安装了一个树莓派开发板用于计算。该机器人有两个被动髋关节和两个主动膝关节,由两个伺服电机通过电缆驱动在脚底部运作。

系统识别
仿真到实际的主要差距之一是其电缆驱动执行机制。在现实中,它们受到摩擦、扭矩饱和和未建模的缆绳动力学影响,使得执行机构动态变得嘈杂和非线性。作者首先进行系统识别,使用优化从真实数据中更好地捕获这种非线性关系。
自由变量p包括仿真中的膝关节弹簧参数、电机增益、默认电机角度和默认膝关节角度。因此,有八个自由变量需要进行优化。
作者设定的目标函数是最小化仿真和硬件之间所有四个关节角度(左右、电机臂和膝)的差异。首先采样20个执行命令,它们在区间[0,1]中均匀分布,这对应于范围在[0◦,90◦]的电机臂角度,并且测量在仿真和硬件上的膝关节和电机关节角度。然后为所有关节拟合多项式曲线,并计算对应曲线之间的有向Hausdorff距离。使用L-BFGS-B算法优化参数直到收敛。

L-BFGS-B算法是一种优化算法,能够快速求解目标函数的最小值。该算法是用于求解连续变量的无约束或约束优化问题的有效方法。L-BFGS-B算法通过迭代地更新搜索方向和步长来逼近全局最优解。其主要应用于高维问题的求解,例如神经网络模型的训练过程中的参数优化。
基于强化学习的残余动力学学习
作者设计了一个框架来学习生成适当的外部扰动力,以使模拟行为与从硬件上收集的地面真实轨迹相匹配。
在基础仿真中训练多个运动策略并记录其行动轨迹。接下来,使用记录的行动作为开环控制在硬件上收集多个状态轨迹。使用运动捕捉系统获取观测数据。使用Vicon运动捕捉系统捕捉所有数据。
Vicon红外三维运动捕捉分析系统是利用红外高速摄像机捕捉被动发光标记点,构建三维数据的运动采集与分析系统,最多可支持244台高性能高频摄像机。
一旦有了参考数据集,就可以将学习残余空气动力学策略作为一个马尔可夫决策过程(MDP)的动作模仿问题。状态空间包括气球当前和最近两个时间步的位置、速度、方向,以及底座和脚的位置和速度。动作空间是三维的,包括施加到气球质心的x、y和z方向的力。力的范围为[−1, 1] N。奖励函数是位置和方向项的组合,定义如下:
其中,位置和方向项分别计算如下:
\\(p_t\\)、\\(\\hatp_t\\)、\\(\\hatr_t\\)和\\(r_t\\)分别是气球的期望位置、实际位置,期望方向和实际方向。位置奖励\\(r^pos_t\\)鼓励仿真模型的气球尽可能接近参考气球位置,而方向奖励\\(r^orn_t\\)鼓励它跟踪参考气球方向。使用欧拉角表示方向,这种表示方法的性能比四元数表示法更好。对于所有实验,设置\\(w^pos=0.7,w^orn=0.3\\),\\(W=diag(0.2,0.4,0.4)\\)。
作者使用PPO算法训练残余动力学策略。其中使用包含两个具有64个神经元的全连接层网络。
作者还通过从选择的轨迹中均匀随机采样一个状态来作为每次训练的初始状态。这使策略暴露于更广泛的初始状态分布,并提高了其稳健性,尤其是在转移到硬件上时。
改进模拟的策略训练
一旦使用系统识别和残余动态学习改进模拟,就可以重新训练深度强化学习策略,以实现更好的模拟到真实的迁移。
策略的状态空间由气球的位置、速度、方向、基座的位置和速度、脚的位置和速度组成,这些都是在当前时间步长测量的。动作是两个执行器命令。
作者学习两种任务策略——一种是前向行走任务策略,一种是左转任务策略。
实验
sim-to-sim实验
作者在开源物理模拟器PyBullet中进行所有模拟实验。使用稳定的基线实现PPO算法来学习残余动力学和改进模拟器中的策略。
作者比较四种不同环境中的轨迹:
- 普通模拟器。
- 使用监督学习学习残余动力学的模拟器。对于监督学习,作者使用了一个具有大小为[64, 64]的两个隐藏层的神经网络。对于所有轨迹,作者使用由标准模拟中的初始策略生成的相同操作序列。
- 使用EnvMimic学习残余动力学的模拟器(作者的方法)。
- 硬件上的Ground-True轨迹。
显然,EnvMimic相比于普通模拟表现出更好的跟踪性能。
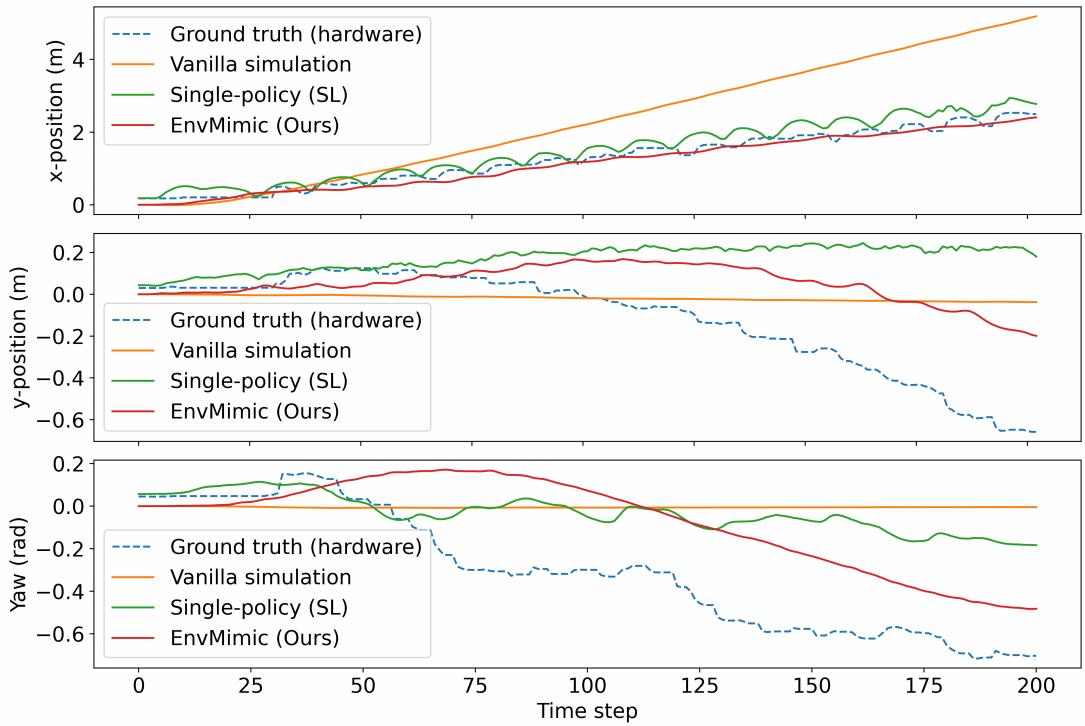
sim-to-real实验
他们使用BALLU平台进行硬件实验,并使用Vicon运动捕捉系统捕捉所有数据。作者将其与在以下设置下学习的基线策略进行比较:
- 仅使用系统识别的模拟(Vanilla + sys ID),
- 仅使用域随机化的模拟(Vanilla + DR),
- 同时使用系统识别和域随机化的模拟(Vanilla + sys ID + DR)。
对于域随机化,作者随机采样摩擦力和初始状态的参数。
对于前进步态任务,通过增强的模拟器学到的策略是唯一一个可以向前行走的策略,而其他基线策略则明显向左转弯。
对于转弯任务,作者的方法训练出了行进距离最长的有效策略,即向左(y)方向行进的距离为0.29米。
对于两个任务,增强的模拟还展现出最小的虚实迁移误差,该误差定义为模拟与硬件之间的质心平均误差和最终偏航角(α)误差。
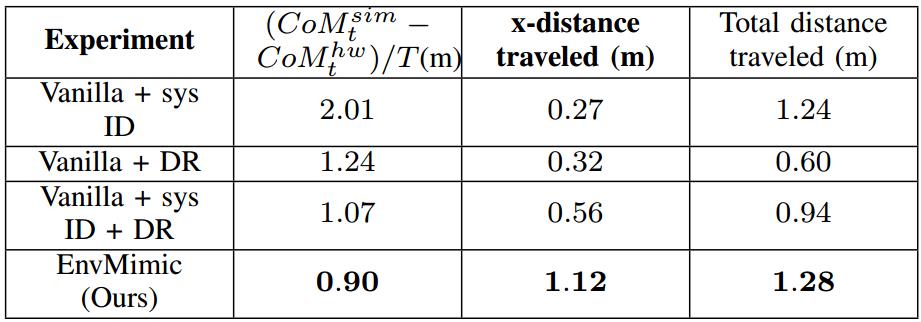
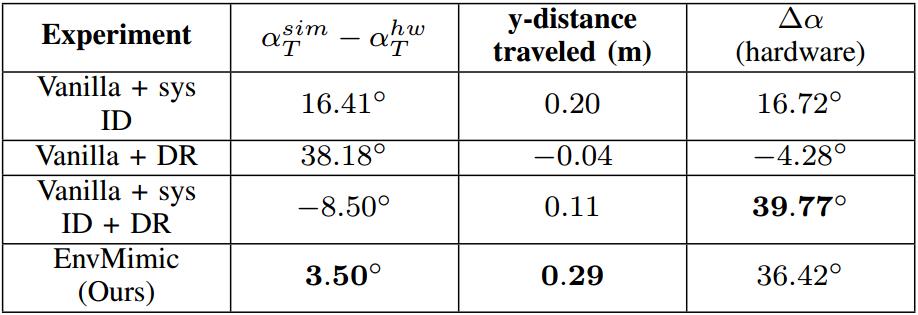
未来工作
在本工作中,作者为每个单独的任务(如行走或转弯)开发残余动力学模型,这限制了对其他任务的泛化。因此,如果收集大量数据集并使用所提出的方法训练通用的剩余动力学模型,将是有趣的研究方向。
本文假设外部力作用于气球中心来模拟空气动力学,对本文测试的运动任务已足够。但是,某些场景可能需要多个力或扭矩来模拟一些复杂的现象。
此外,BALLU机器人的动力学特性也因气球漏气而对时间敏感。未来,或许可以引入终身学习(lifelong learning)的概念来建立那些逐渐的时间变化。
论文笔记之: Wide Residual Networks
Wide Residual Networks
以上是关于论文阅读笔记《Residual Physics Learning and System Identification for Sim to real Transfer of Policies on B的主要内容,如果未能解决你的问题,请参考以下文章