yolov3算法详解
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了yolov3算法详解相关的知识,希望对你有一定的参考价值。
参考技术A YOLOv3: An Incremental Improvement 按照原文的说法,它其实是一篇技术试验的报告。本文通过一些试验来改进yolo方法。这部分的预测和yolov2是一样的,详情可以参考 yolov2算法详解 。
文章采用的是多标签的分类方法,文章认为softmax对于好的预测结果的获取不一定是有帮助的。训练的时候类别的loss采用的是binary cross-entropy loss。
对于多尺度框的预测类似于有FPN结构的fastrcnn,不同的feature大小负责不同大小的框的检测。为了更好的解释,先看看yolov3的网络结构
上面为yolov3新提出的网络用于分类任务,网络中采用了resnet提出的残差结构,并且使用了53层卷积,所以网络称为Darknet-53。不同于分类任务,检测任务需要多尺度的特征来检测不同尺度的物体,所以需要采用FPN的结构,具体网络结构图如下,下图中图片输入大小为416,通道顺序为(N,C,H,W),每个方块中的括号里的维度代表该方块的输出feature维度,标红的框为最终的输出
可以看到类似FPN结构有三层的输出,这里每一层有3类的anchor,三层总共为9类,而这9类anchor的设定是使用yolov2提出的kmeans聚类选出来的,不同数据集不一样,对于COCO数据集来说为 这9类尺度。
需要说明的是,上图中输出的通道是255,这个数字是针对COCO数据集有80类来举例的,具体的就是[3 * (4 + 1 + 80)] = 255,3表示3类anchor,4表示预测的框,1表示框的置信度,80表示类别置信度
上述1,2点可以参考 yolov2算法详解 , 第3点参考 Focal Loss for Dense Object Detection论文详解 ,第4点参考 Faster R-CNN文章详细解读
模型训练目标检测实现分享四:详解 YOLOv4 算法实现
欢迎关注我的公众号 [极智视界],回复001获取Google编程规范
O_o >_< o_O O_o ~_~ o_O
大家好,我是极智视界,本文详细介绍一下 YOLOv4 算法的设计与实践,实践部分包括 darknet 与 pytorch。
本文是目标检测类算法实现分享的第四篇,前面已经写过三篇,感兴趣的同学可以查阅:
(1) 《【模型训练】目标检测实现分享一:详解 YOLOv1 算法实现》;
(2) 《【模型训练】目标检测实现分享二:听说克莱今天复出了?详解 YOLOv2 算法与克莱检测》;
(3) 《【模型训练】目标检测实现分享三:详解 YOLOv3 算法实现》;
YOLOv4 是 YOLO 系列的第四个版本,在论文 《YOLOv4:Optimal Speed and Accuracy of Objecti Detection》中提出,集目标检测领域各种 state-of-the-art tricks 大荟萃 ,通过阅读 YOLOv4 论文及进行训练实践,可以对近年来目标检测领域涌现出的众多优秀 tricks 有个宏观把控。作者试验并集众多 tricks 于一身,就此催生出了性能出众的 YOLOv4 网络。
话不多说,让我们来看。
同样这里不止会讲原理也会讲实践。
文章目录
1、YOLOv4 原理
老规矩,先上性能数据:

上图测试数据集为 MS COCO,推理硬件为 Nvidia V100,横轴为帧率 FPS,纵轴为精度 AP,所以从 兼顾效率和精度 角度来看,越往右上越好。可以看到 YOLOv4 相比 EfficientDet 要快两倍,相比 YOLOv3,AP 和 FPS 分别提升了 10% 和 12%。
来看一个分别跑在 Maxwell、Pascal、Volta 架构上的 AP&FPS 性能图:

可以看到作者对比了很多先进的目标检测网络,但不管是在 Maxwell、Pascal 还是 Volta 架构上,YOLOv4 总是右上角最闪亮的那颗星。
再来看一组更加详细的性能数据,这组数据是在 Volta 架构的 GPU 上测得:

上图性能数据是在 batch=1 且没有使用 TensorRT 进行加速的情况下测得,蓝色条表示帧率 FPS > 30,也即可以达到实时检测。可以看到 YOLOv4 的三个输入分辨率都能轻松达到实时,另外像 CenterMask-Lite、EFGRNet-VGG16-320、HSD-VGG16-320、DAFS-VGG16-512 也可以达到实时。另外在精度方面, AP、AP50、AP75、APs、APm 已经被 YOLOv4-CSPDarknet53-608 霸榜了,在 APl 上 CenterMask-Lite-VOVNet39-FPN-600x 要略优 0.2 个点。
从以上实验数据可以看出 YOLOv4 的性能是非常强悍的,它的提出主要有以下两个贡献:
(1) 提出了一个高效又强大的检测模型,任何人都可以只用一张 2080Ti GPU 卡就可训练出一个好用的检测器;
(2) 试验了众多 state-of-the-art 的检测 tricks,并融入到 YOLOv4 中,使其更加的高效和强大;
下面让我们来好好研究一下。
YOLOv4 的网络结构划可分为 Input、Backbone、Neck、Head 四个模块,可以用下图表达:
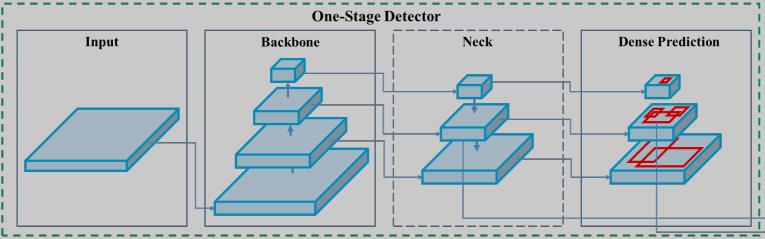
然后在模型结构和训练策略上分别加入了一些被称为 “Bag of freebies” 和 “Bag of specials” 的 tricks,解释一下这两个词:
- Bag of freebies (BoF):只改变训练策略或只增加训练成本,而不增加推理成本从而提高性能的方法,如数据增强;
- Bag of specials (BoS):稍微增加一点推理成本,但可以极大提升检测精度的方法,如插件模块和后处理方法;
YOLOv4 中融入了大量的 BoF 和 Bo
YOLOv4 的网络结构划分为 Input、Backbones、Neck、Heads 四个模块组成,差不多像下图:
下面来看各个模块中的 tricks。
1.1 Input
YOLOv4 在训练时对输入进行了很多创新性改进,包括 Mosaic 数据增强、cmBN、SAT 自对抗训练等,下面进行详细介绍。
1.1.1 Mosaic
Mosaic 是在 CutMix 数据增强的基础上进化而来的,CutMix 是使用两张图片拼接进行数据增强,而 Mosaic 拓展到了使用四张图片拼接,且这四张图片是随机缩放、随机裁剪和随机排版的,这样可以一下子极大的丰富数据集。Mosaic 数据增强的效果如下:

1.1.2 CmBN
CmBN 是 CBN 的改进版,而 CBN 又是 BN 的改进版。BN 是对当前 mini-batch 数据进行归一化,CBN 可以看做是 Cross Batch Normalization,是对当前以及往前数 3 个 mini-batch 数据进行归一化,而 CmBN 可以看做是 Cross mini-Batch Normalization,只统计一个大 batch 中 4 个 mini-batch 之间的数据,对外隔离。BN、CBN、CmBN 的流程示意如下:

1.1.3 SAT
SAT (Self-Adversarial Training) 自对抗训练也是一种数据增强的方法,它包括两个阶段:
(1) 1st stage:使用神经网络去改变图片数据,而不是更新权重数据,可以理解为图像数据生成;
(2) 2nd stage:神经网络以正常方式在扩充后的图像数据集上进行训练。
1.2 Backbone
1.2.1 CSPDarknet53
我们知道在 YOLOv2 中 backbone 为 Darknet19,YOLOv3 中 backbone 为 Darknet53,在 YOLOv4 中 backbone 又进行了一次升级,这次称为 CSPDarknet53,主要参考了论文《CSPNet:A New Backbone that can Enhance Learning Capability of CNN》,然后和 Darknet 相结合,来看主结构:

再来看一下 CSPDarknet53 对比其他一些优秀 backbone 的参数量及性能情况,如下:

可以看到在相同输入分辨率的情况下,CSPDarknet53 具有更高的 FPS,这说明效率更高;也具有更多的参数量,说明有更多的参数可以去学习特征,往往特征学习能力会更强。
1.2.2 Mish
YOLOv4 backbone 是由很多的 CBM block (Conv + BN + Mish) 和 残差结构组成,CBM block 差不多长这样:

Mish 激活函数在论文《Mish: A Self Regularized Non-Monotonic Activation Function》中提出,其数学表达为:

函数的图像表达如下,其中:
- 蓝色曲线为:Mish;
- 橙色曲线为:ln(1 + e^(x))

当然在实现的时候,也可以把 Mish 拆成由 tanh 和 softplus 组成,如在 TensorRT 的实现中往往需要这么做,即:

对比 Relu,Mish 不像 Relu 那样是两阶段的,Mish 没有明显的折点,所以经 Mish 出来的梯度更加平滑,对比效果如下:

1.3 Neck
1.3.1 SPP
SPP 指的是这个东西:

这个结构其实在 YOLOv3-SPP.cfg 中早就存在,不过在 YOLOv3 时期还没有真正上位,在 YOLOv4 的时候才算真正上位了。SPP 结构在论文《DC-SPP-YOLO: Dense Connection and Spatial Pyramid Pooling Based YOLO for Object Detection》中提出,其主要目的是增加感受野。
1.3.2 FPN + PAN
FPN 结构在 YOLOv3 中也存在,以输入分辨率 608 x 608 为例,在 YOLOv3 中通过 upsample 上采样和 Conv 下采样后,最后形成了 19 x 19、38 x 38、76 x 76 的三分支结构,示意如下:

而 YOLOv4 的不同之处在于,在 YOLOv3 FPN 的基础上再接一个 Botton-up 结构,Botton-up 中用 PAN 进行衔接,整个 YOLOv4 FPN + PAN 的结构示意如下:

YOLOv4 中的 PAN 修改了传统 PAN 中 addition 为 concatenation,这里有些不同,addition 不改变通道维度,concatenation 则会改变通道维度,示意如下:

1.4 Dense Prediction
1.4.1 Yolo
YOLOv4 中最后的 yolo 预测层沿用了 YOLOv3 的 yolo,不过需要注意的是 YOLOv4 在经过了如上的 FPN + PAN 的 Neck 后,又形成了一个很容易让人迷惑的点:
YOLOv3 的最后三个 yolo 层分别为:
(1) 第一个 yolo 层:feature map 19 x 19 ==> mask = 6, 7, 8 ==> 对应最大的 anchor;
(2) 第二个 yolo 层:feature map 38 x 38 ==> mask = 3, 4, 5 ==> 对应中等的 anchor;
(3) 第三个 yolo 层:feature map 76 x 76 ==> mask = 0, 1, 2 ==> 对应最小的 anchor;
而在 YOLOv4 中情况是相反的:
(1) 第一个 yolo 层:feature map 76 x 76 ==> mask = 0, 1, 2 ==> 对应最小的 anchor;
(2) 第二个 yolo 层:feature map 38 x 38 ==> mask = 3, 4, 5 ==> 对应中等的 anchor;
(3) 第三个 yolo 层:feature map 19 x 19 ==> mask = 6, 7, 8 ==> 对应最大的 anchor;
这个差异在开发过程中需要特别注意,很容易就把顺序搞错了。
1.4.2 IOU Loss
YOLOv4 在 Bounding box Regeression Loss 上也做了一些创新,采用 CIOU_Loss 进行回归预测,使得预测框的速度和精度更加高。
说到 CIOU_Loss,它经历了从最开始直接计算预测框的坐标点 Loss 到 IOU_Loss ,然后再进行了一系列优化的过程。这个过程差不多是这样:Smooth L1_Loss -> IOU_Loss -> GIOU_Loss -> DIOU_Loss -> CIOU_Loss。
- Smooth L1_Loss: 使用 Smooth L1_Loss 计算预测框的中心点或顶点相对于真实框的损失,无约束,反向传播时很容易导致梯度消失;
- IOU_Loss:IOU_Loss 主要考虑检测框和真实框的交集 / 并集,存在问题:当 IOU=0时(边界框不重合) 或 IOU值一定时,情况是多样的 ;
- GIOU_Loss:GIOU_Loss 在 IOU_Loss 的基础上,增加了相交尺度的衡量方式,解决了边界框不重合时的问题,不过还存在问题:IOU 值一定时,情况是多样的;
- DIOU_Loss:DIOU_Loss 进一步在 GIOU 的基础上,考虑了 重叠面积 和 中心点距离,覆盖的情况更多了,但还不够全面:当多个预测框的中心点刚好在以真实框中心为圆心的圆上时,情况是多样的;
- CIOU_Loss:CIOU_Loss 在 DIOU_Loss 的基础上再增加了一个影响因子,加入了预测框和真实框的长宽比,可以说覆盖的情况十分全面了。
好了,以上主要介绍了 YOLOv4 的原理和改进点,下面进入实践环节。
2、YOLOv4 实现
这里实践了两种框架的 YOLOv4。
2.1 训练
2.1.1 darknet 训练
darknet 下训练数据集为 COCO,关于 COCO 数据集的制作过程就不多说了,上一篇 YOLOv3 中已经详细说过,不会的同学可以移步到上一篇。下面直接开始。
在 cfg 目录下创建 yolov4 文件夹,加入 yolov4.cfg、coco.data、coco.names,并在 yolov4 文件夹下创建 backup 文件夹用于存放中间权重,形成目录树如下:
执行训练指令:
./darknet detector train cfg/yolov4/coco.data cfg/yolov4/yolov4.cfg
当然也可以加预训练权重:
./darknet detector train cfg/yolov4/coco.data cfg/yolov4/yolov4.cfg cfg/yolov4/yolov4.conv.137
附上 yolov4.conv.137 的传送:https://github.com/AlexeyAB/darknet/releases/download/darknet_yolo_v3_optimal/yolov4.conv.137
然后可以看到已经开始训练:

经过很长的训练时间应该可以看到网络在慢慢收敛:

2.1.2 pytorch 训练
pytorch 是现在使用十分广泛的训练框架,以动态图和灵活性著称,当然这里少不了 YOLOv4 的 pytorch 实现了。
相关 YOLOv4-pytorch 工程代码我已为你们整理好,关注我的公众号 [极智视界] 回复 yolov4 即可领取。
我这里提供的工程内还放了 VOC 数据集格式,只需要根据提供的格式制作一下训练数据集就可以轻松跑起来。
让我们来跑一跑,直接执行工程下 train.sh 即可开始训练:
./train.sh
这样的执行方式应该非常的友好,另外你可能还想着要修改一些参数,在 train.py 脚本内做相应修改即可,比如修改是否进行 Mosaic 数据增强等:

来看看训练过程:
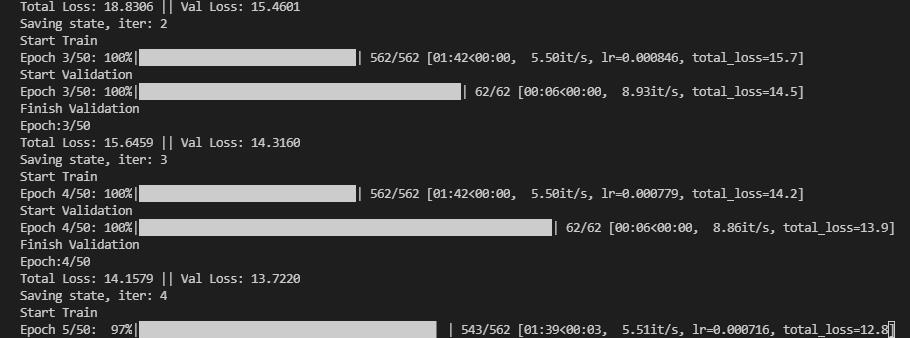
2.2 验证
好了,接下来我们进行验证一下,训练出来的模型是否有效。
这里拿 darknet 的模型进行验证,验证场景为春运现场,执行如下命令进行检测:
./darknet detector demo cfg/yolov4/coco.data cfg/yolov4/yolov4.cfg cfg/yolov4/backup/yolov4.weights data/chunyun.mp4
检测效果如下:

可以看到检测效果还是不错的。
也借此视频愿山河无恙、疫情早日消散,同胞们可以快快乐乐、平平安安回家过年。
以上分享了 YOLOv4 算法设计与实践,希望我的分享能对你的学习有一点帮助。
【公众号传送】
扫描下方二维码即可关注我的微信公众号【极智视界】,获取更多AI经验分享,让我们用极致+极客的心态来迎接AI !

以上是关于yolov3算法详解的主要内容,如果未能解决你的问题,请参考以下文章