YOLOv1详解
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了YOLOv1详解相关的知识,希望对你有一定的参考价值。
参考技术A 从目标检测任务(Object Detection Task)发展来看,主要有两类方法。一类是R-CNN系列及其类似算法,称为two-stage,将目标检测任务分为边界框回归和物体分类两个模块。虽然模型前面大量的提取特征以及候选框的选取都是单个网络完成,但回归和分类任务毕竟还是分开的,分开训练造成网络较难收敛,且预测时速度慢,但准确度较高。另一类是本文描述以及后面会更新换代的YOLO算法,称为one-stage,将目标检测任务单纯看做回归任务。YOLOv1使用端到端的网络训练模型,速度快,但准确度相对低些,主要用于实时检测,例如视频目标检测。由于YOLOv1是端到端进行训练,因此YOLOv1只有一条单一的网络分支。YOLOv1输入为 的图像,经过一个修改的GoogLeNet网络(网络到底什么样的其实不用管,只要知道是一堆卷积和池化的堆叠即可),后面接一些全连接层(同样无所谓接什么全连接层,看下参数或者源码就直接懂了),最后接到一个 的全连接层,直接reshape为 (这里reshape成这样是有意图的,具体参见下面部分)。
YOLOv1将一张图像(例如 )划分为 个网格(YOLOv1中 ,如下图所示),一共 个网格。
损失函数有多个部分,我们现在把它们分开来说,后面直接挨个加起来即可。
第一部分如下所示,计算预测边界框和GT框中心点之间的差距。其中 表示第 个网格的第 个边界框是否负责一个物体,是为1,不是为0。
第二部分类似第一部分,主要计算预测宽高和GT宽高损失。这里加上根号表示大边界框小偏差应该比小边界框小偏差更重要。
第三部分计算对于每个边界框的置信度分数与预测的置信度分数之间差距。 表示置信度分数, 表示预测的边界框和对应GT框的IoU。
最后一部分计算类概率损失, 表示当网格中没有物体时不惩罚。
其中, , 。
论文原文: https://arxiv.org/pdf/1506.02640.pdf
英文博客: https://medium.com/hackernoon/understanding-yolo-f5a74bbc7967
NMS参考: https://docs.google.com/presentation/d/1aeRvtKG21KHdD5lg6Hgyhx5rPq_ZOsGjG5rJ1HP7BbA/pub?start=false&loop=false&delayms=3000#slide=id.p
YOLOv5网络详解
0 前言
YOLOv5项目的作者是Glenn Jocher并不是原Darknet项目的作者Joseph Redmon,并且这个项目至今都没有发表过正式的论文。
官方源码仓库,目前更新到v6.1:https://github.com/ultralytics/yolov5
如果对YOLO系列没有了解:
YOLO系列理论合集(YOLOv1~v3)
YOLOv4网络详解
1 YOLOv5网络模型
YOLOv5整体结构:
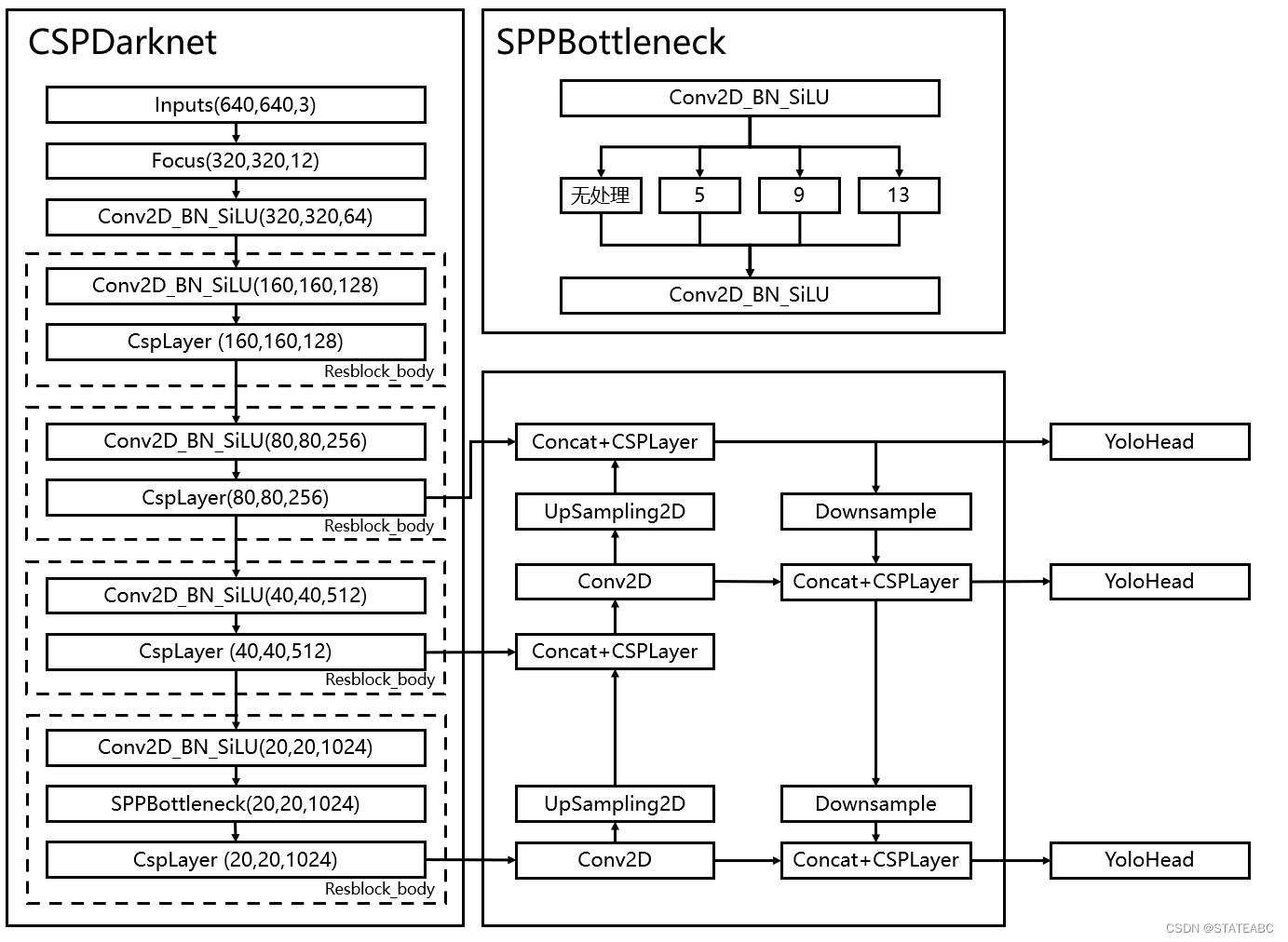
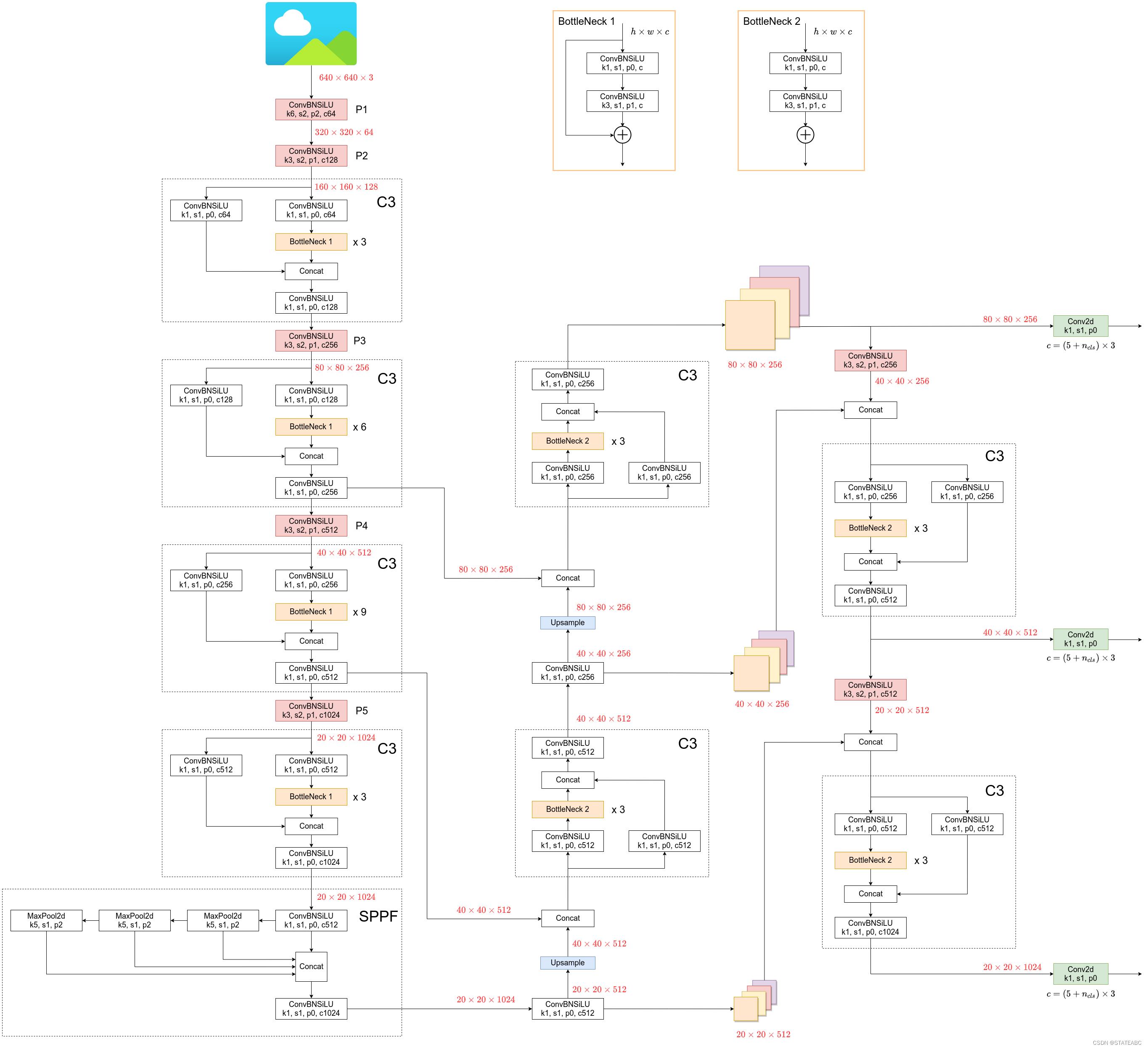
YOLOv5l网络结构:
2 网络结构改进
YOLOv5共给出了五个版本的目标检测网络:YOLOv5n、YOLOv5s、YOLOv5m、YOLOv5l、YOLOv5x
2.1 Backbone改进
YOLOv5所使用的特征提取网络仍为CSPDarknet
Focus网络结构
在之前的YOLO网络中并没有使用Focus网络结构
Focus模块在YOLOv5中是图片进入backbone前,每隔一个像素取一个值,可以获得4个独立的特征层,将这4个特征层进行堆叠,此时就将宽高维度上的信息转换到了通道维度,输入通道扩充了四倍,再通过进行特征的提取。

将每个2x2的相邻像素划分为一个patch,然后将每个patch中相同位置(同一颜色)像素给拼在一起就得到了4个feature map,然后在接上一个3x3大小的卷积层。
作者提到使用focus层可以减少参数计算,减少cuda的使用内存。
但是在v6.0版本后的YOLOv5没有并用Focus结构,把Backbone的第一层(原来是Focus模块)换成了一个6x6大小的卷积层,两个理论等价,但是对现有的一些GPU和优化算法,使用6x6的卷积层更加高效。
SiLU激活函数
SiLU 函数也称为 swish 函数,具有处处可导、连续光滑、非单调的特性,可以看作是平滑的ReLU激活函数。
f(x)=x⋅sigmoid(x)

SPPF结构
使用SPP结构,通过不同池化核大小的最大池化进行特征提取,提高网络的感受野。在YoloV4中,SPP是用在FPN里面的,在YoloV5中,SPP模块被用在了主干特征提取网络中。

SPPF结构是将输入串行通过多个5x5大小的MaxPool层,这里需要注意的是串行两个5x5大小的MaxPool层是和一个9x9大小的MaxPool层计算结果是一样的,串行三个5x5大小的MaxPool层是和一个13x13大小的MaxPool层计算结果是一样的。
SPPF结构与SPP结构作用一样,但SPPF结构效率更高、速度更快
2.2 Neck改进
在YOLOv5中的FPN特征金字塔结构中引入了CSP结构,在网络结构图中可以看到每个C3模块中都含有CSP结构。

在特征提取部分,YoloV5提取多特征层进行目标检测,一共提取三个特征层。
三个特征层位于主干部分CSPdarknet的不同位置,分别位于中间层,中下层,底层,当输入为(640,640,3)的时候,三个特征层的shape分别为feat1=(80,80,256)、feat2=(40,40,512)、feat3=(20,20,1024)。
在获得三个有效特征层后,利用这三个有效特征层进行FPN层的构建,构建方式为:
1.feat3=(20,20,1024)的特征层进行1次1X1卷积调整通道后获得P5,P5进行上采样UmSampling2d后与feat2=(40,40,512)特征层进行结合,然后使用CSPLayer进行特征提取获得P5_upsample,此时获得的特征层为(40,40,512)。
2.P5_upsample=(40,40,512)的特征层进行1次1X1卷积调整通道后获得P4,P4进行上采样UmSampling2d后与feat1=(80,80,256)特征层进行结合,然后使用CSPLayer进行特征提取P3_out,此时获得的特征层为(80,80,256)。
3.P3_out=(80,80,256)的特征层进行一次3x3卷积进行下采样,下采样后与P4堆叠,然后使用CSPLayer进行特征提取P4_out,此时获得的特征层为(40,40,512)。
4.P4_out=(40,40,512)的特征层进行一次3x3卷积进行下采样,下采样后与P5堆叠,然后使用CSPLayer进行特征提取P5_out,此时获得的特征层为(20,20,1024)。
特征金字塔可以将不同shape的特征层进行特征融合,有利于提取出更好的特征。
2.3 Head改进
Head部分,YOLOv3, v4, v5都是一样的。
还有一些损失计算、正负样本匹配的问题,后续在训练时候再看
参考文献:
YOLOv5网络详解
搭建自己的YoloV5目标检测平台
以上是关于YOLOv1详解的主要内容,如果未能解决你的问题,请参考以下文章