YOLO算法之YOLOv3精讲
Posted 羽峰码字
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了YOLO算法之YOLOv3精讲相关的知识,希望对你有一定的参考价值。
目录
大家好,我是羽峰,今天要和大家分享的是YOLOv3算法。YOLOv3算法是在YOLOv2算法的基础上继续进行改进的,本文章不仅包括YOLOv3的改进原理,而且还包括YOLOv3的代码实例讲解,希望通过本视频讲解,各位朋友能够更好的应用YOLOv3去训练自己的项目。
如果想要YOLOv3代码,欢迎关注“羽峰码字”公众号,并回复“YOLOv3”获取相应代码。
YOLOv3的改进
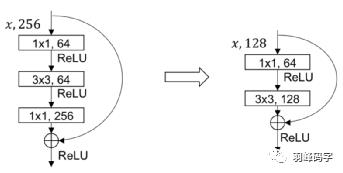
1. YOLOv3的第一个改进是网络的结构的改变
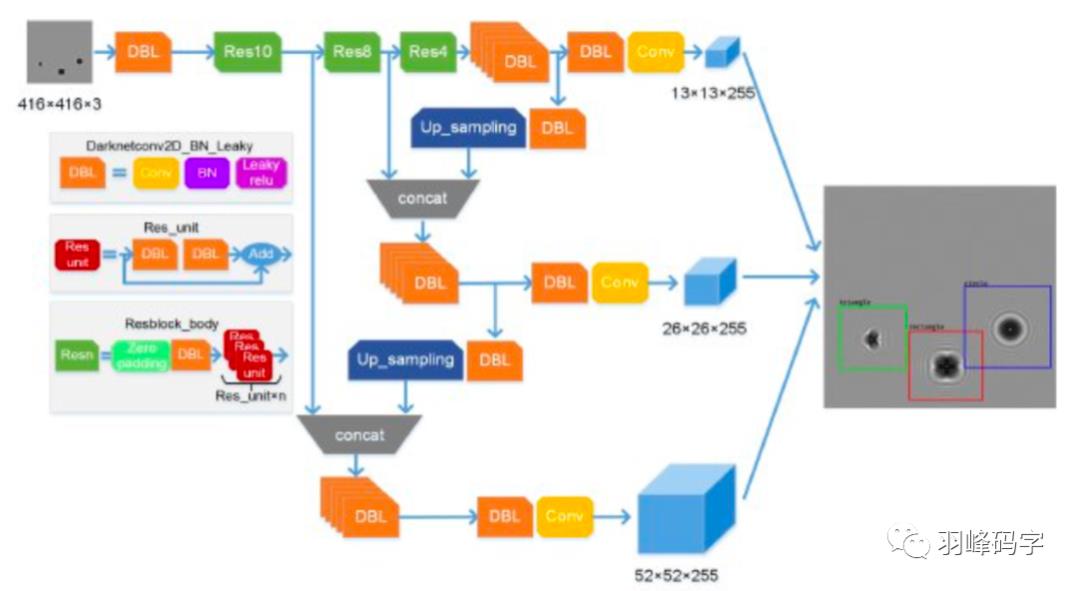
引入了ResNet思想,但是如果将ResNet模块完全引进是整个模型就很大,所以直接将ResNet模块的最后一层1*1*256去掉,而且将倒数第二层3*3*64直接改成3*3*128。整个网络结构如图所示,输入的是416*416*3的RGB图像,网络会输出三种尺度的输出,最后输出每个目标物体的类别和边框。
2. YOLOv3的第二个改进是多尺度训练
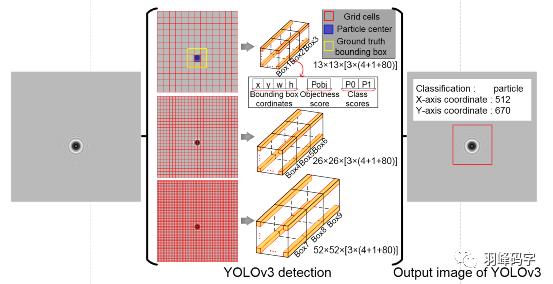
这个多尺度训练是真正的多尺度,一共有3种尺度,分别是13*13,26*26,52*52三种分辨率,分别负责预测大,中,小的物体边框,这种改进对小物体检测更加友好。

YOLOv3多尺度训练的原理如图所示,首先一个图像输入,被YOLOv3分割成13*13,26*26,52*52的网格,每种分辨率的每个网格分别对应一个包含255个参数的向量,每个向量包括三个边框(,每个边框中包含85个参数,分别是边框的中心位置(x,y),边框的宽和高(w,h)边框的置信度,还有80个类别概率。最后输出每个物体的类别概率和边框。
YOLOv3代码实战
1. 数据集标注
训练YOLOv3首先要进行LabelImg标注,
LabelImg的网址为:https://github.com/tzutalin/labelImg,
安装程序如图所示:

安装好之后,界面如图所示:
首先点击”open”打开图片,如图所示,打开的是一个狗和猫的图片,然后选择边框进行标注。
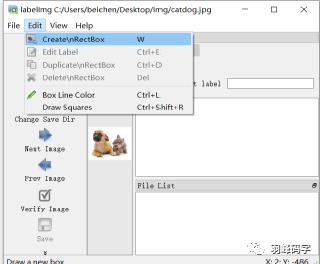
标注好之后应该,应该备注目标物体类别,如图所示:
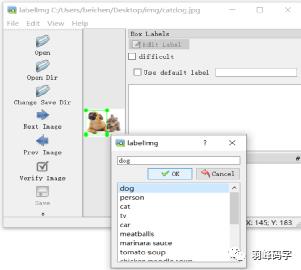
标注好之后会生成“catdog.xml”文件,
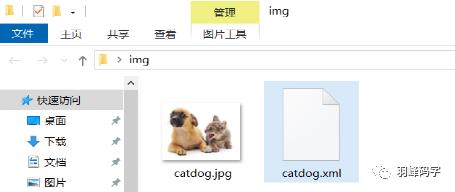
文件内容如图所示:

最后分别将图片(catdog)放入./VOCdevkit/VOC2007/JpegImages, LabelImg标注图像放进“Annotations”中。如图所示:

2. 数据预处理
当图片和xml文件都准备好之后 ,运行“voc2yolo3.py”程序,生成数据集列表文件,将图片上对应的”voc_classes.txt”换成你自己的分类标签,如果有多个类别,请将每个类别单独放一行。
由于我这里是零时加入进来的数据,不是本YOLOv3所执行的,后边图片中的数据都是原yolov3的数据,所以有些数据对应不上,但执行整个过程是接下来要说的。如果训练自己的数据集,需要将自己的数据粘贴到对应位置。
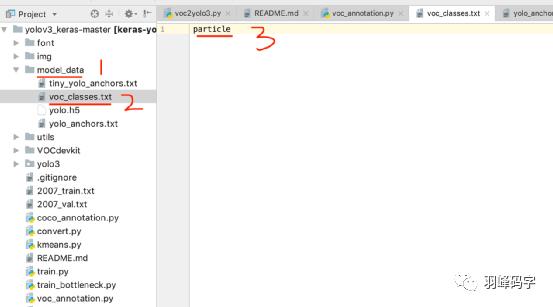
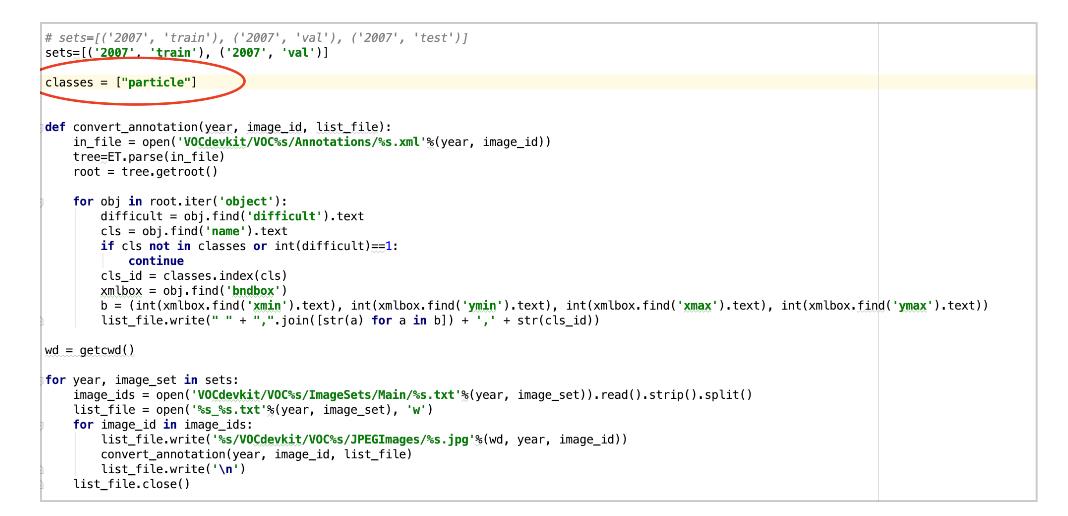
之后在运行“voc_annotation.py”程序,运行之前,首先将程序中的类别改成你自己的类别,我这里类别只有一个“particle”
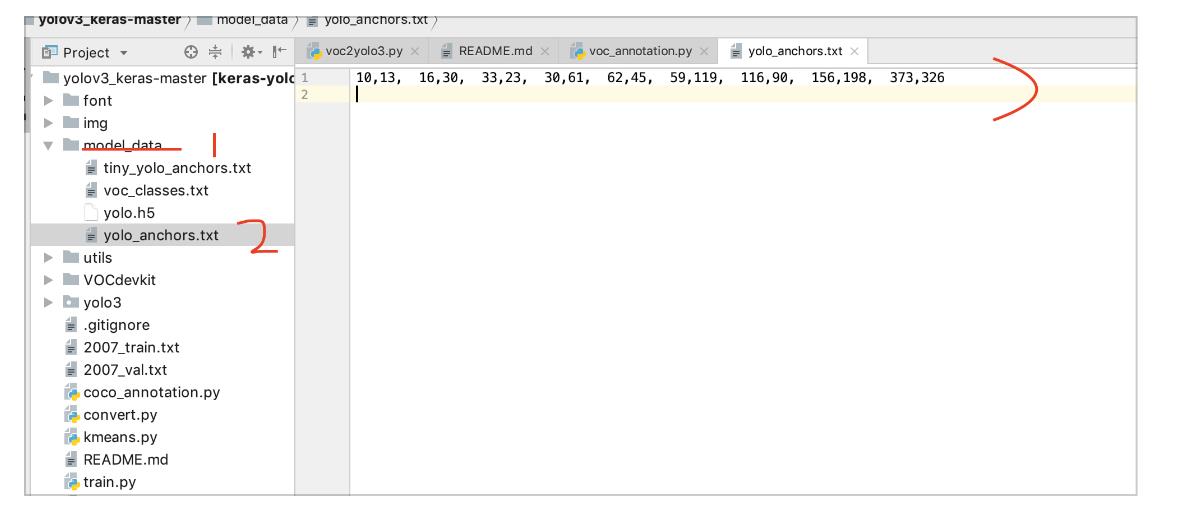
之后在运行“kmeans.py”程序,运行好之后会生成k anchor,这些数字代表了你的预生成的标注框大小,将这些标注框数据首先放入如图所示的位置,并按照“yolo_anchors.txt”原有格式进行修改。

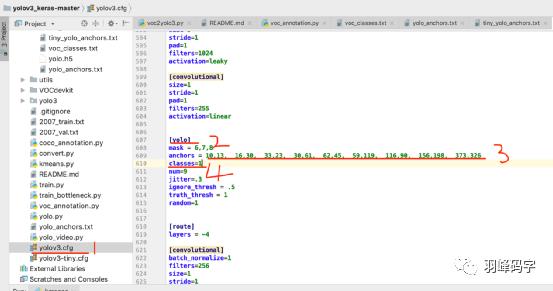
接下来在复制这些数字到“yolov3.cfg”中,搜索”yolo”将对应的anchors 和classes 进行修改,classes选择你要分类的类别,我这里只有1个类别,就改成了1。一共有3个“yolo”,都要修改,修改之后就执行直接执行“train.py”了。
如果训练完成之后,执行“yolo_video.py”进行测试就行。如果是从我公众号下载的yolov3,需要将yolo_video.py做如下修改:


YOLO系列总结
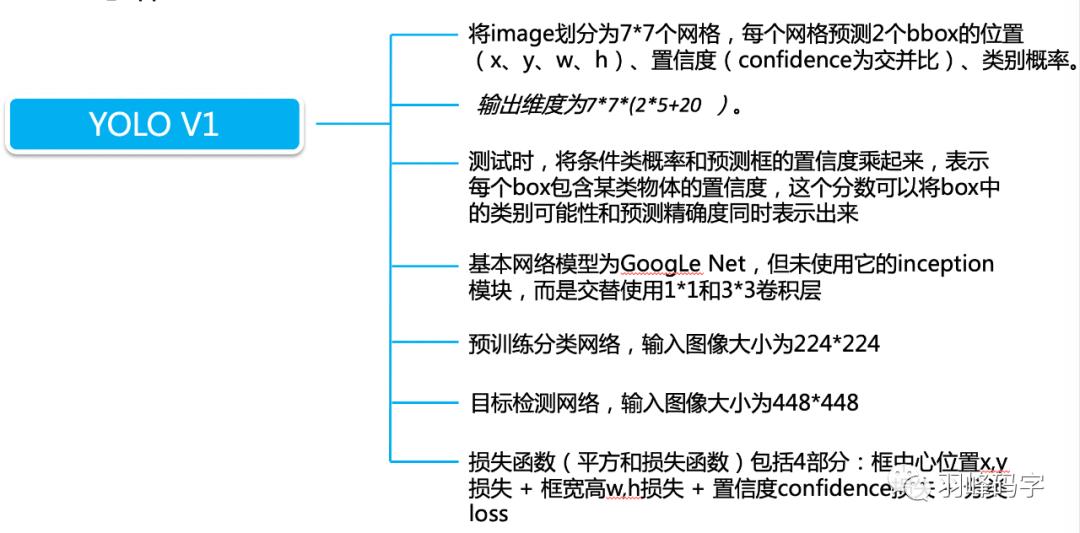
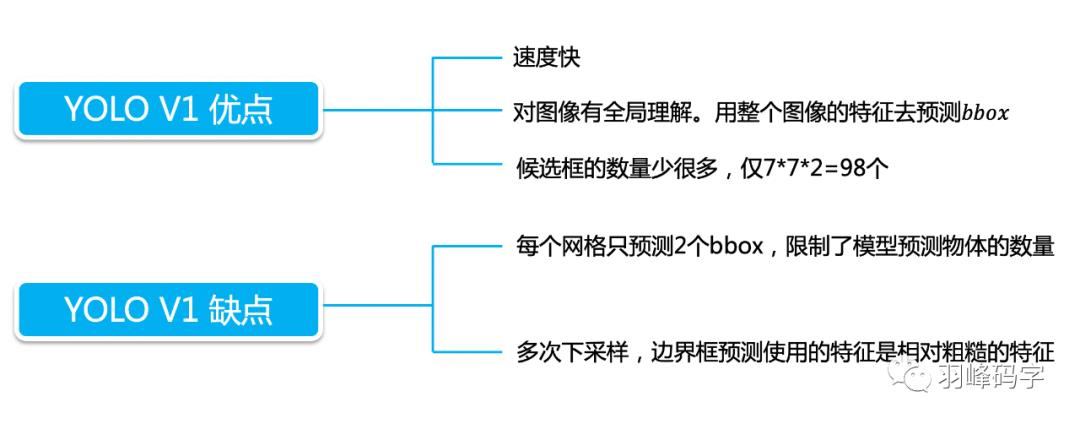
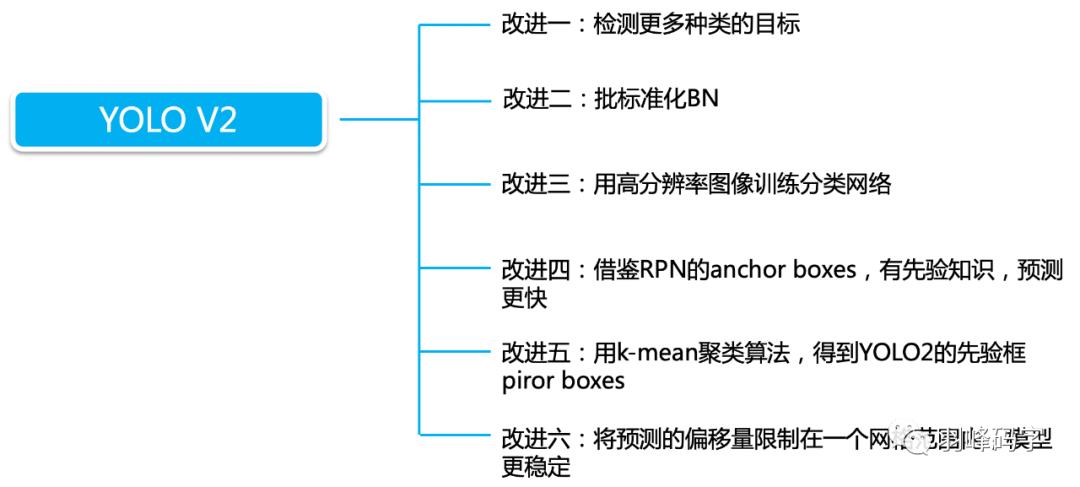
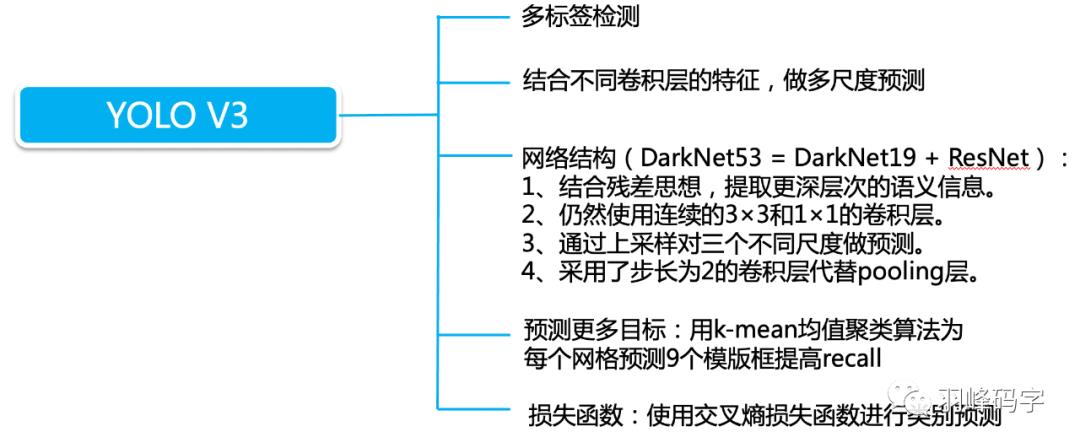
以上 就是我今天要分享的内容,谢谢各位。如有错误,欢迎批评指正。
想要ppt,欢迎关注“羽峰码字”公众号,回复“PPT”即可获取。b站up主:羽峰码字,也分享了相关视频,欢迎浏览呀!
以上是关于YOLO算法之YOLOv3精讲的主要内容,如果未能解决你的问题,请参考以下文章