智能插帧,打造丝滑视频体验
Posted 字节跳动技术团队
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了智能插帧,打造丝滑视频体验相关的知识,希望对你有一定的参考价值。
动手点关注 干货不迷路 👆
暑假期间小跳出去旅游,沿途用手机记录下了许多美丽景色。回家路上,小跳打开手机想用慢倍速去细细品味自己拍摄的视频,发现视频强烈的卡顿感让其“黯然失色”。失望的小跳想起前段时间在抖音上看到的剪映 APP 丝滑慢放教程,抱着试一试的态度打开了剪映,几番操作下来,视频发生了质的改变,像是回到了拍摄的那瞬间,把当下没被记录的片段统统还原出来,卡顿感“一键”全无。是什么技术让视频还原出当下的瞬间,让卡顿视频变得如此丝滑?本文对字节跳动智能创作团队自研视频插帧技术进行了深度解剖,为大家找到了丝滑视频的秘诀。
视频帧率(单位:fps)指的是每秒播放的画面数。在一定范围内,帧率越高,视频观感越流畅。早期电影的帧率在 20~60 fps,现代电视广泛使用的帧率标准是 25 fps 和 30 fps。
随着技术的发展,电视、手机等播放设备能够支持播放更高帧率的视频。如今用户已经不满足陈旧的 20~30 fps 视频标准。由于网络传输、拍摄丢帧、后期编辑等原因,线上甚至存在不少实际帧率低于 15 fps 的视频。为了消除低帧率视频的卡顿感,需要使用插帧技术来提升视频的帧率,从而给观众带来丝滑流畅的播放体验。
插帧算法通过计算原视频的帧间运动关系,在两帧之间插入符合运动关系的中间帧,从而提升视频的帧率。
两帧之间插入新的中间帧
字节跳动智能创作团队打造了一套多端视频智能插帧解决方案,在抖音、剪映、西瓜等多个业务场景落地。该方案能对低帧率短视频进行帧率提升,改善短视频观看体验;同时还为视频创作者提供了高阶视频剪辑工具,对变速视频进行补帧、生成丝滑慢动作效果。除此之外,还衍生出多种特效玩法,在多个业务上取得了投稿、拉新、留存、DAU 等指标的显著收益。
视频插帧业界解决方案
低帧率视频产生的原因有很多,视频从创作到消费的链路上,拍摄、剪辑、编解码、下发策略等因素都可能会对视频帧率造成影响。因此在各个环节上,插帧技术都有应用价值。需要构建一套多端视频插帧解决方案,才能最大程度地将帧率问题优化到极致。
针对不同的使用场景、不同的后端设备,算法方案也有所不同。当前业界常用的解决方案有:
帧融合或重复帧
直接将前后两帧的融合结果或重复帧作为新增的中间帧,插入到原视频中。该方法计算简单,但会产生拖影感和卡顿感,并没有起到提升视频观看体验的作用。通常可作为特殊场景、低端设备的兜底方案。
Adobe Premiere,Final Cut Pro 等专业剪辑软件中也集成了该方法,作为插帧的一个可选方法
传统 MEMC 方案
MEMC (Motion Estimation, Motion Compensation) 是一类运动补偿算法。此类算法会对相邻两帧进行运动估计,补偿出原视频中本身没有的画面,达到提升视频帧率的目的。MEMC 所生成的中间帧符合原视频的平滑运动关系,因此可以使视频更流畅。但对于运动复杂的场景,很难在有限的算力条件下得到精确的结果。
Adobe Premiere 、Final Cut Pro 中的光流法插帧( Pr 中也叫“时间插值”)中就是采用此类方法。

运动补偿示意
深度学习方案
基于深度学习的方案,通常将原视频相邻两帧作为神经网络的输入,结合光流神经网络、遮挡估计等技术,来预测两帧之间的中间帧。深度学习方法可以提取图像语义信息,因此往往在遮挡估计等方面表现更优。但深度学习方法往往计算量大,很难在移动设备上应用。
目前基于深度学习的光流算法较为成熟,可以计算两帧之间的密集光流。用了光流信息,可以将前后两帧图像 Warp 到中间时刻,从而合成中间帧。
Nvidia SuperSlomo 提供一个在 Nvidia GPU 上运行的深度学习插帧算法,但对显卡性能有较高的要求。
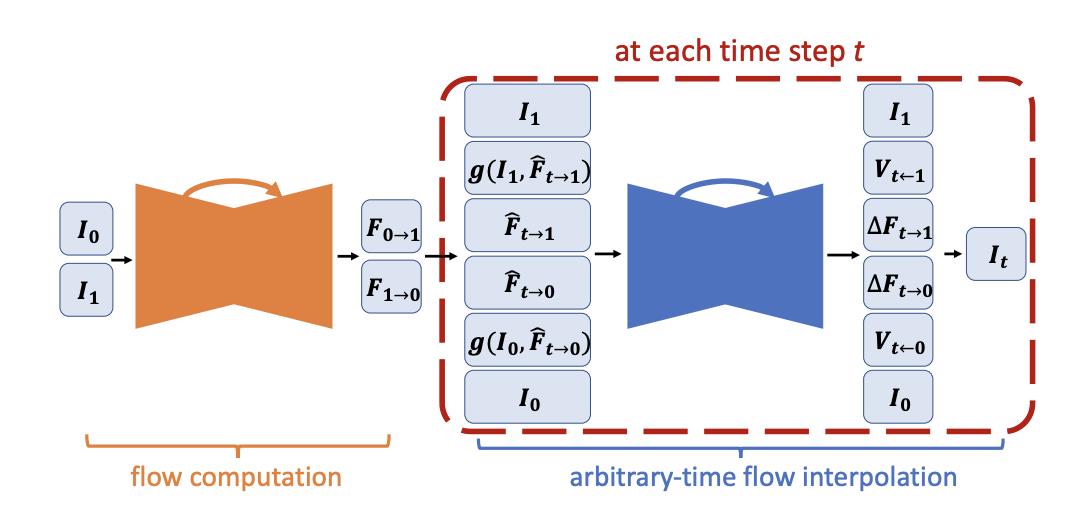
图源 Nvidia SuperSlomo 论文
自研插帧算法的突破与优化
多端插帧算法能力矩阵
为了服务抖音、西瓜、剪映、火山引擎等不同业务场景的需求,同时全链路优化帧率问题,我们构建了一套视频插帧多端解决方案。

视频插帧多端解决方案
服务端
服务端拥有 GPU 算力,因此适合采用深度学习方案来获得更平滑的插帧效果。自研服务端插帧算法为抖音业务提供了云端帧率提升转码能力,以改进低帧率短视频的观看体验。日后也会以云服务的形式,逐步对更多业务线、ToB 客户开放。
移动端
如果能直接在移动设备上使用插帧算法,那么算法能力可以触达更多的视频创作者,在视频生产环节即可提升视频流畅度。针对移动端使用场景,我们研发了基于 MEMC 的插帧算法,并针对 MEMC 算法存在的问题做了细致的优化。
PC 端
专业视频创作者往往使用桌面端专业剪辑软件进行视频创作。自研的视频插帧解决方案也为 PC 端的剪映专业版提供了插帧能力。对于配备有独立显卡的 PC 设备,可采用深度学习方案来保证更好的插帧效果;其他 PC 设备可复用移动端的核心算法,来保证算法运行的性能。
优化方案
尽管插帧技术已有较长的发展历史,业界也有成熟的应用案例,但仍然面临着性能和效果的巨大挑战。在性能方面,服务端 GPU 算力成本大,移动端算力局促且机型分布复杂。在效果方面,插帧效果依赖于准确的运动估计,如果视频中存在大幅运动、前后遮挡等复杂运动场景,生成的中间帧可能会产生模糊、拖影、块状破碎感等现象。针对这些难点,字节跳动智能创作技术团队,从算法与工程多个维度对多端插帧算法进行了优化。
神经网络模型压缩
我们采用模型剪枝技术,减少神经网络中冗余的权重。并且通过特征共享,减少双向光流的计算量。除此之外,根据光流的平滑特性,我们采用在小分辨率光流推理、在原分辨率进行中间帧合成的策略,减小复杂网络的计算量。

插帧网络结构示意
内容自适应的插帧可行性分析
并不是所有的视频的内容都适合使用插帧,对于相邻帧变化剧烈的场景(例如转场、剧烈运动),插帧算法无法生成一个合理的结果,甚至可能引入严重伪影。因此我们对视频内容进行插帧可行性判断,根据图像特征、运动幅度等信息,自适应地决定是否为当前帧进行插帧。
更高效的 MEMC 策略
块匹配是一个基于搜索的运动估计算法,需要在前后帧的一定领域内搜索最匹配的图像块。对于运动复杂的视频,这种方法往往需要较大的搜索空间,才能搜索出最优运动向量。这给移动端应用带来了算法瓶颈。我们研发了一套光流指导的块搜索策略,来解决块匹配的性能和效果的问题。
自研方法首先在相邻两帧之间,计算一个多尺度快速光流。图像金字塔多尺度策略,可以使得算法对大运动场景更鲁棒。得到初步光流信息后,可以以光流作为指导,在金字塔最大尺度上做进一步块搜索。此时,块搜索只需在较小的搜索空间即可快速搜索出最优运动向量。

基于多尺度金字塔的快速光流
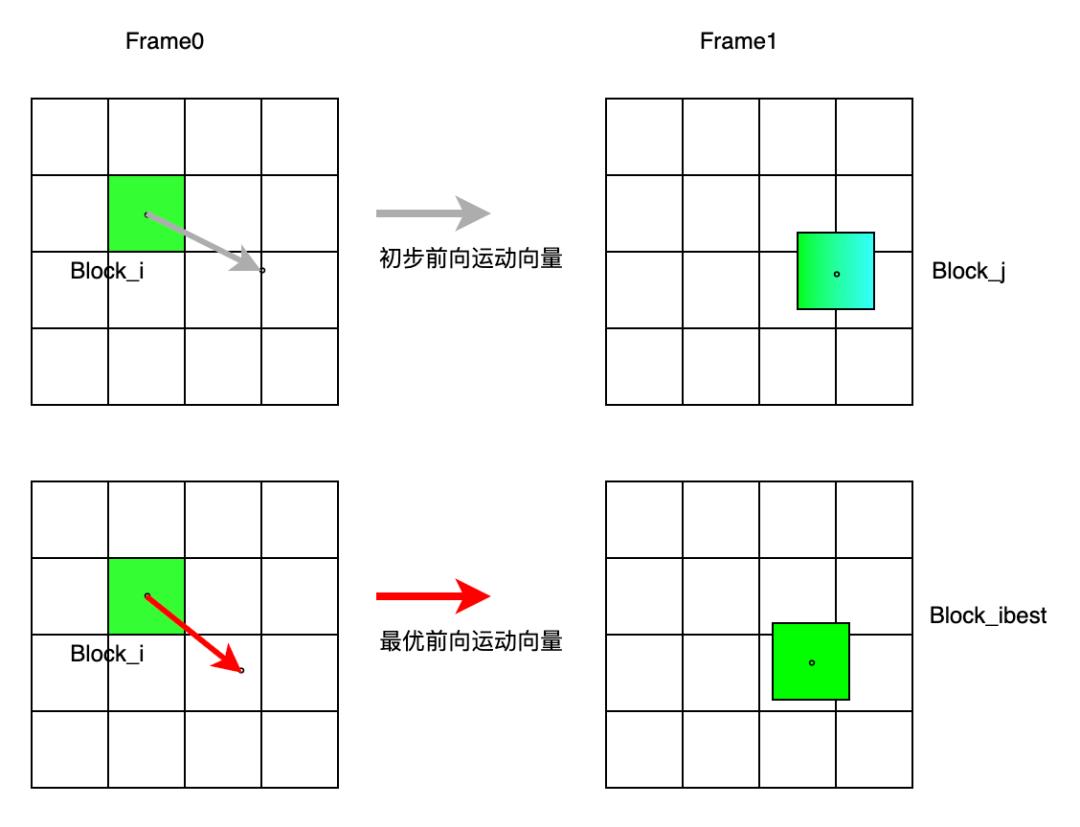
在金字塔最大尺度上做块搜索
无论是多尺度快速光流,还是光流指导的块搜索,整个计算过程都可并行计算。使得算法在移动设备上,也能高效运行。
端上异构计算
在端上使用了 CPU+GPU 的计算方式,将计算密集型任务分配给 GPU,使用 opencl 或 metal 实现算子,并根据平台做特定的性能调优;而计算稀疏型任务则在 CPU 上完成计算,并使用多线程等操作进行性能优化。通过异构计算,在端上可以实现 5 倍左右的加速比,性能达到落地需求。
端上算法分级策略
抖音、剪映等 app 覆盖用户量级大,用户机型多样。为了保证算法的机型覆盖率,让不同机型用户获得最佳体验,我们采用了端上算法分级的策略。根据用户机型的计算能力,端上插帧算法分为高、中、低三个档位,高档位优先保证效果,适合高端机型;低档位优先保证性能,适合低端机型。
智能补帧及其衍生应用
剪映变速-智能补帧
我们的插帧能力已上线剪映“变速”面板。视频素材慢放后,可勾选“智能补帧”选项,让慢动作更丝滑。

剪映智能补帧入口
自动变速创意玩法
剪映已在抖音玩法一栏上线“丝滑变速”效果,可以一键生成卡点变速效果。该玩法的“丝滑”效果,也少不了插帧能力的支持。海外版 CapCut 上线了同样的能力,上线两周即形成爆款。
帧率提升
除了让慢放更丝滑,帧率提升也是插帧算法的一大应用。西瓜视频“玩法库”面板提供了帧率提升的体验入口,可将用户上传的低帧率视频提升为高帧率视频,提升视频的流畅度。
王家卫电影风格
“王家卫电影风格”特效是插帧算法的一个衍生玩法,已上线剪映拍摄器及特效。该风格通常是在拍摄阶段通过摄像机慢快门来产生“拖影”的效果。而通过插帧算法的运动估计及补帧能力,在视频后期阶段,即可一键生成符合视频场景运动关系的“拖影”效果。
辅助其他视频算法节省算力
一些效果惊艳的 GAN 特效算法,往往复杂度高。在视频特效场景需要逐帧进行神经网络推理,很难到达实时性能。但在插帧算法性能优于 GAN 特效效法的前提下,可以使用“特效+补帧”的策略来加速视频处理。复杂度高的GAN 特效只需要以一定间隔处理更少的帧数,其余中间帧使用插帧算法生成。

插帧辅助其他算法减小耗时
未来展望
除了视频编辑、特效玩法,未来我们将持续探索插帧技术在视频高清低码场景的应用价值。插帧技术不仅可以提升视频内容质量,还能在带宽节省、低延传输等方面发挥价值。
低功耗实时视频插帧
结合厂商能力,在算法与工程上极致优化插帧性能。服务端只需下发更低帧率的低码率视频,使用高性能、低功耗的插帧算法,端上进行实时插帧还原高帧率视频。不仅保证用户体验,还能节省带宽成本。
结合编解码器进行智能补帧
H.264 编码器内部会进行运动估计,通过编码运动补偿残差来进行帧间编码。新一代 H.266 编码器在运动估计准确性、运动补偿准确性上进行了更深入的优化。将编解码器与插帧进行结合,运动估计信息能够被插帧算法复用,插帧算法也能够进一步优化帧间编码的压缩率。
参考文献
[1] Jiang, Huaizu, et al. "Super slomo: High quality estimation of multiple intermediate frames for video interpolation." Proceedings of the IEEE conference on computer vision and pattern recognition. 2018.
[2] Niklaus S, Liu F. Context-aware synthesis for video frame interpolation[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2018: 1701-1710.
[3] Choi B D, Han J W, Kim C S, et al. Motion-compensated frame interpolation using bilateral motion estimation and adaptive overlapped block motion compensation[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2007, 17(4): 407-416.
关于我们
字节跳动智能创作团队是字节跳动音视频创新技术和业务中台,覆盖了计算机视觉、图形学、语音、拍摄编辑、特效、客户端、服务端工程等技术领域,在部门内部实现了前沿算法-工程系统-产品全链路的闭环,旨在以多种形式向公司内部各业务线以及外部合作客户提供业界最前沿的内容理解、内容创作、互动体验与消费的能力和行业解决方案。
目前,智能创作团队已通过字节跳动旗下的火山引擎向企业开放技术能力和服务。
火山引擎联系方式
业务咨询:service@volcengine.com
市场合作:marketing@volcengine.com
电话:400-850-0030
🙋♂️ 点击“阅读原文“,获取最新招聘资讯!
达摩院OpenVI几行代码,尽享丝滑视频观感
随着网络电视、手机等新媒体领域的快速发展,用户对于观看视频质量的要求也越来越高。当前市面上所广为传播的视频帧率大多仍然处于20~30fps,已经无法满足用户对于高清、流畅的体验追求。而视频插帧算法,能够有效实现多倍率的帧率提升,有效消除低帧率视频的卡顿感,让视频变得丝滑流畅。配合其它的视频增强算法,更是能够让低质量视频焕然一新,让观众享受到极致的播放和观看体验。点击如下链接,立即体验。
学术版模型:https://www.modelscope.cn/models/damo/cv_raft_video-frame-interpolation/summary
应用版模型:https://www.modelscope.cn/models/damo/cv_raft_video-frame-interpolation_practical/summary
视频插帧算法,顾名思义,需要计算原始视频中相邻(多)帧间的运动关系,在相邻帧间插入符合逻辑的中间帧,使中间帧能与原始帧无缝衔接,达到提升视频流畅度的效果

插帧前后的效果对比(左:插帧前,右:插帧后)
一、背景
当前,插帧算法在学术界不断取得突破,多篇文章通过transformer的引入能够有效提升PSNR等验证指标。但当前大多数SOTA模型在一些通用视频的困难场景下(包括但不限于:大运动场景、重复纹理场景、电影中的台标、字幕)生成的中间帧存在明显的瑕疵现象。而上述所提到的场景,也成为了当前视频插帧在业界所面临的最大挑战。此外,当前的大多数插帧算法仅支持生成t=0.5时刻的中间帧,即2倍插帧,无法一次性实现高倍率插帧以及任意指定帧率转换。针对以上问题,达摩院视觉增强团队在Modelscope上线了自研的插帧算法,该算法能够有效提升上述困难场景下的插帧质量,同时该算法支持任意时刻的中间帧生成,输出帧率可由用户任意指定。
二、方法
ours算法采用深度学习方案,完整链路可分为四部分:原始帧间光流预测、光流修复(refine)、中间帧光流估计、中间帧生成。
原始帧间光流预测
当前,绝大多数插帧算法都是基于光流来实现运动估计的。光流能够表征相邻两帧间对应像素点的运动距离大小,反映同一物体的位置对应关系。通常来说,光流预测的精准程度越高,生成的中间帧也更准确。在我们的算法中,复用了RAFT这一光流模型,用于生成F0->1和F1->0。和其它的光流模型相比,RAFT所提出的convex upsample使其在估计快速运动小物体有着更高的准确率。

(输入img0、img1)

Ft->1

Ft->0
光流修复
针对RAFT模型所生成的光流,我们引入了基于cross-attention transformer结构来对原始光流进行修复。该结构能够扩大感受野,结合Unet能够有效捕捉大运动场景下的光流。经过修复,我们可以得到对原始帧间的光流F0->1和F1->0实现精准估计
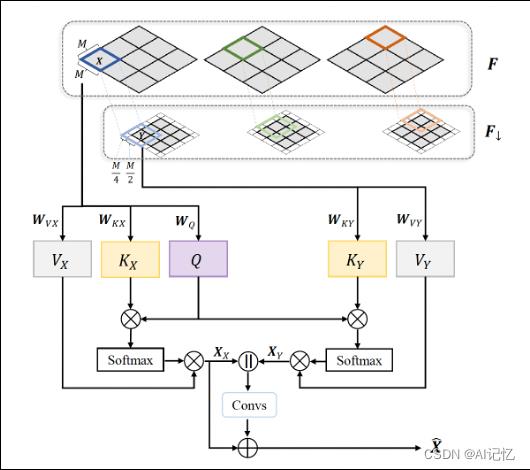
cross-attention transformer[3]
中间帧光流估计
这一步的主要目的是通过F0->1和F1->0去估计Ft->1和Ft->0,这里我们引入了基于四帧输入的光流估计算法。和两帧输入算法相比,该算法能够更好地捕获快速运动物体的加速度,此外,多帧信息的引入,又能够有效提升重复纹理场景光流估计错误的问题。

中间帧光流估计[4]
中间帧生成
这一步借由I1和Ft->1、I0和Ft->0,通过backward warping各自生成中间帧。考虑到潜在的遮挡问题,通过mask对两张图像进行加权融合,即可得到最终的中间帧图像。该部分算法和当前大多数插帧算法无异。
三、效果
1.算法优势和功能支持
基于深度学习方法,针对大运动、重复纹理等困难场景进行了算法改进。针对电影、电视剧、体育赛事视频中常出现的台标、字幕等场景,进行了训练数据构造和增强,大幅提升了算法的实用性。
支持用户指定任意帧率输出,算法可自动计算插帧时刻,并支持任意时刻的插帧
针对部分镜头切换或其它不适合插帧的场景,可进行自动检测和筛选
算法嵌入modelscope开源平台,用户可免费体验。模型调用简单方便,几行代码即可调用pipeline。不仅如此,modelscope兼容主流深度学习框架,提供灵活简单的python SDK,开发者可以方便地对算法进行二次开发,构建自己的专属模型
点击链接 https://www.modelscope.cn/home 进入魔搭社区
2.视频、图像综合增强
插帧算法作为视频增强的一部分,能够有效解决视频卡顿的问题。此外,modelscope社区还上线了包括去噪、超分、调色、上色等多种视频图像修复增强算法。任何低质量的原始视频,都能够在增强修复后变得焕然一新,让你享受到极致高清、饱满、丝滑的视频观看体验。
点击链接https://www.modelscope.cn/models?page=1&tasks=vision-editing&type=cv 可体验多种视觉编辑功能
四、展望
除了视频编辑和修复功能,未来我们还将持续探索插帧技术更为广阔的应用场景。当前随着大模型的兴起和层出不穷的AIGC玩法,插帧在图生视频、图片场景串联转换等领域,仍然存在巨大的潜力等待我们去发掘。
五、参考
[1] Teed, Zachary, and Jia Deng. "Raft: Recurrent all-pairs field transforms for optical flow." European conference on computer vision. Springer, Cham, 2020
[2] Huang, Zhewei, et al. "Real-time intermediate flow estimation for video frame interpolation." Computer Vision–ECCV 2022: 17th European Conference, Tel Aviv, Israel, October 23–27, 2022, Proceedings, Part XIV. Cham: Springer Nature Switzerland, 2022.
[3] Lu, Liying, et al. "Video Frame Interpolation with Transformer." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2022.
[4] Xu, Xiangyu, et al. “Quadratic video interpolation.” Advances in Neural Information Processing Systems 32 (2019).
以上是关于智能插帧,打造丝滑视频体验的主要内容,如果未能解决你的问题,请参考以下文章
如何打造 iOS 短视频的极致丝滑体验,阿里工程师用了这些方案