论文精读(李沐老师)Attention Is All You Need
Posted 我是小蔡呀~~~
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了论文精读(李沐老师)Attention Is All You Need相关的知识,希望对你有一定的参考价值。
Abstract
在主流的序列转录(给你一个序列,生成另外一个序列)模型中主要是依赖复杂的RNN和CNN,一般包括encoder和decoder两个结构。在性能最好的模型里,通常使用注意力机制连接encoder和decoder。
(本文想做一个序列转录模型,讲述了一下现在主流的模型是什么)
本文提出了一个新的简单的架构——Transformer,本模型完全基于注意力机制,而没有用RNN和CNN。做了两个机器翻译的实验,显示出这个模型在性能上特别好,有更好的并行化以及需用更少的时间来训练。我们的模型在英语到德语上的翻译工作达到了28.4的BLEU score,比目前最好的结果高出2个BLEU score。在英语到法语的翻译工作上,做了一个单模型实验,比所有的模型效果都要好,只在8个GPU上训练了3.5天。Transformer模型在别的任务上泛化的都很好。
(本文本来是针对机器翻译这一小领域提出的transformer,其出圈是可以应用到nlp,video等领域并取得了很好的效果)
Conclusion
一、本文提出了transfomer模型,是第一个仅仅使用注意力机制的序列转录模型,把之前的循环层全部换成了muti-headed self-attention。
二、在机器翻译任务上,transformer要比基于RNN和CNN的架构快很多。在实际任务中,效果也比较好。
我们认为transformer可以用在文本以外的任务中,包括图片、语音和视频。使生成不那么时序化也是另外一个研究方向。
Introduction (对摘要的扩充)
一、在时序模型中,常用的是RNN(2017年提出)、LSTM和GRU。两个比较主流的模型是语言模式和Encoder-decoder架构。
二、(主要讲RNN的特点和缺点)假设你的序列是一个句子,RNN会一个词一个词的看,对第t个词,会计算其隐藏状态ht,ht是由h(t-1)和第t个词本身决定的。因此导致,难以并行化,计算量大以及会丢失距离较远的信息,如果不想丢失则需要付出较大的内存空间。虽然采用了一些因式分解等方法提升并行度,但是本质上还是没有解决太多的问题。
三、(主要讲Attention在RNN上的应用,如何将encoder的东西有效的传到decoder。)
四、(讲本文提出的transformer)transformer不再使用RNN,而是纯基于注意力机制,并行度很高,能在较短时间内做到很好的一个效果。
Background(相关工作)
一、如何使用CNN替换RNN来减少时序的计算,但CNN对于比较长的序列难以建模,Transfomer可以看到整个序列。但是卷积可以做多个输出通道,我们也想要这个效,所以提出了muti-headed attention来模拟CNN多输出通道的一个效果。
二、讲自注意力机制,这个工作已被提出,并不是本文的一个创新。
三、讲End-to-end Memory networks。
四、Transformer是第一个只依赖于自注意力机制,来做encoder-decoder架构的模型。
Model Architecture
一、序列模型中,现在比较好的是一个encoder-decoder的架构。encoder,是把x=(
x
1
x_1
x1,……,
x
n
x_n
xn)表示成z=(
z
1
z_1
z1,……,
z
n
z_n
zn)。decoder,放入z,生成一个(
y
1
y_1
y1,……
y
m
y_m
ym)的序列,在decode中,词是一个一个生成的,使用auto-regressive,即过去时刻的输出,作为当前时刻的输入。
二、Transformer是使用了一个encoder-decoder的架构,具体来说是将一些自注意力机制,Point-wise和fully connected layers堆积在一起。
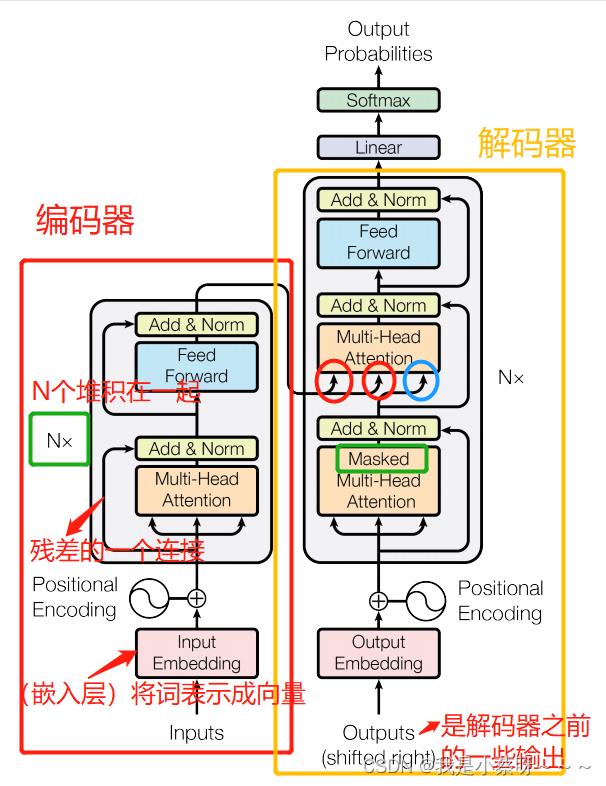
Encoder and Decoder Stacks
Encoder:
使用了N=6个完全一样的layer。每个layer有两个子层,第一个子层是multi-head self-attention mechanism,第二个子层是a simple, position-wise fully connected feed-forward network(其实就是一个MLP,多层感知机)。对每一个子层用了一个残差连接,最后使用(layer norm,对每一个样本做Norm)层归一化。为了简单起见,对每一层输出的维度都变成512。
Decoder:
使用了N=6个完全一样的layer。每个layer有三个子层,其中两个子层与encoder一样,第三个子层用了一个Masked Multi-Head Attention。Mask,当前时刻为t,mask只能让看到t时刻之前(为了保证和预测时保持一致,具体做法:将t时刻之后,包括t时刻,取一个很大的负数如
−
1
0
10
-10^10
−1010,这样进入softmax做指数后就会变成0)。
Attention(注意力层)
注意力函数是一个将query和一些key-value对映射成输出的一个函数。query,key-value和output都是一些向量。output是value的一个加权和(导致output和value的维度一样),每个value的权重是value对应的key与query的相似度算来的。
(在连接encoder和decoder时,key和value不会改变,随着query的改变,权重不同,输出也会不同)
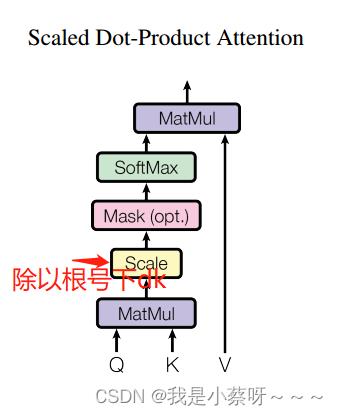
Scaled Dot-Product Attention(是最简单的注意力机制)
一、query和key长度都是等长的,为
d
k
d_k
dk。value是
d
v
d_v
dv(那么输出也是
d
v
d_v
dv)。对query和key做内积,然后将其作为相似度(内积越大,相似度越高),然后除以
d
k
\\sqrtd_k\\quad
dk,然后通过一个softmax(对每一行做softmax,每一行之间是独立的)来得到权重(非负加起来为一)。
二、query可以写成一个矩阵Q(因为可能不止一个query),key——K,value——V
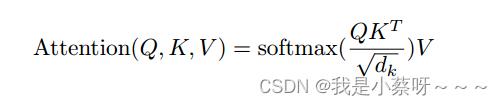
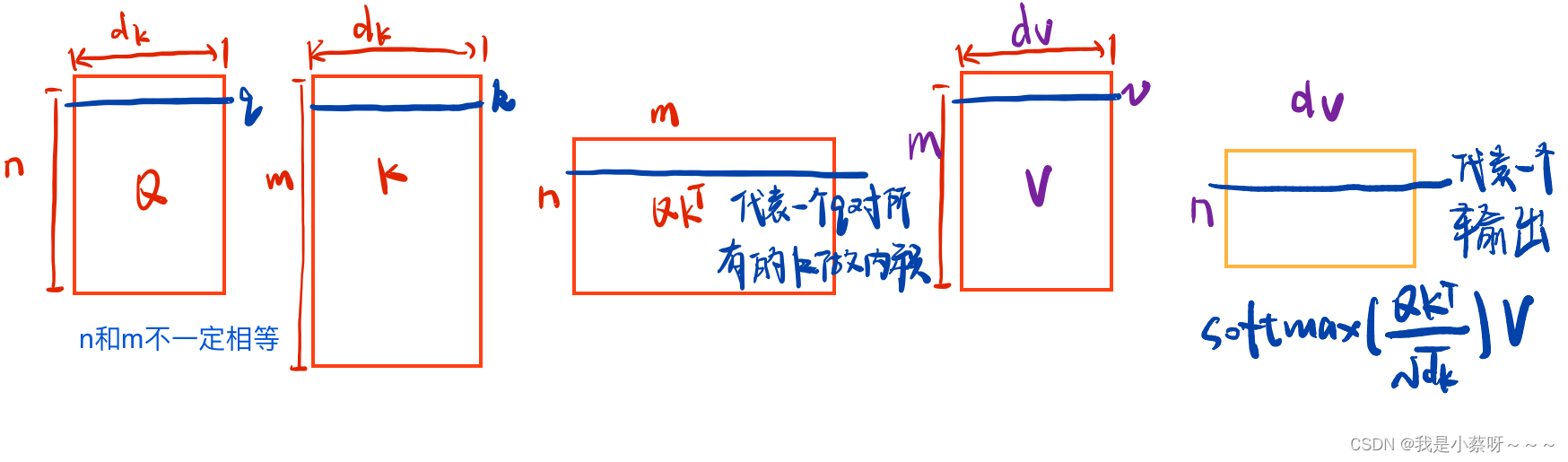
三、一般有两种比较常见的注意力机制:additive attention(可以处理query和key不等长的情况) 和 dot-product attention(本文用)。两种注意力机制其实差不多,本文选择的是点乘注意力机制,因为简单、高效。
四、(解释为什么除以一个
d
k
\\sqrtd_k\\quad
dk)当
d
k
d_k
dk(向量长度)比较大时,点积后的值可能会比较大/较小,就会导致softmax后的值向两端(0和1)靠拢,出现这种情况算梯度会比较小,所以除以一个
d
k
\\sqrtd_k\\quad
dk。
Multi-Head Attention
一、与其做一个单个的注意力函数,不如将整个k,v,q投影到低纬,投影h次(本文用了8个头),然后再做h次的注意力函数,然后将每一个注意力函数的输出并在一起,再投影回来得到一个最终的输出。
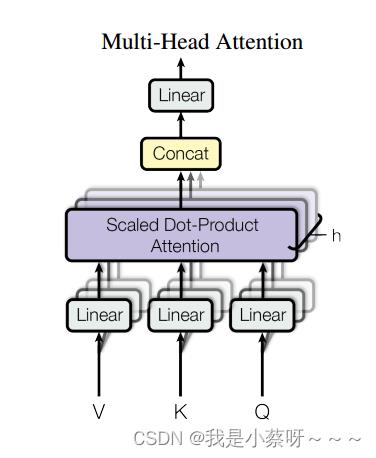

三、在我们的工作中,h=8。因为有残差连接的存在,我们输入和输出的维度要一样,所以投影的维度为
d
k
=
d
v
=
d
m
o
d
e
l
/
h
=
512
/
8
=
64
d_k=d_v=d_model/h=512/8=64
dk=dv=dmodel/h=512/8=64(我们每一次将其投影到64维,然后算注意力函数,最后在投影回来)。
Applications of Attention in our Model(讲在transformer中如何使用注意力机制的)
一、在编码器(encoder layers)这一层。假设句子长为n(n个词),则编码器的输入为n个长为d的向量。Q,K,V其实是一样的,复制了三份,只是
w
q
,
w
k
,
w
v
w_q,w_k,w_v
wq,wk,wv不同。
二、在解码器(decoder layers)这一层。唯一与编码器这一层的注意力机制,不一样的是有一个mask这个东西。
三、在连接encoder和decoder这一层,key和value来自编码器的输出(n个长为d的向量),query来自解码器下一个attention的输入(m个长为d的向量)。
Position-wise Feed-Forward Networks(下图中蓝色部分)
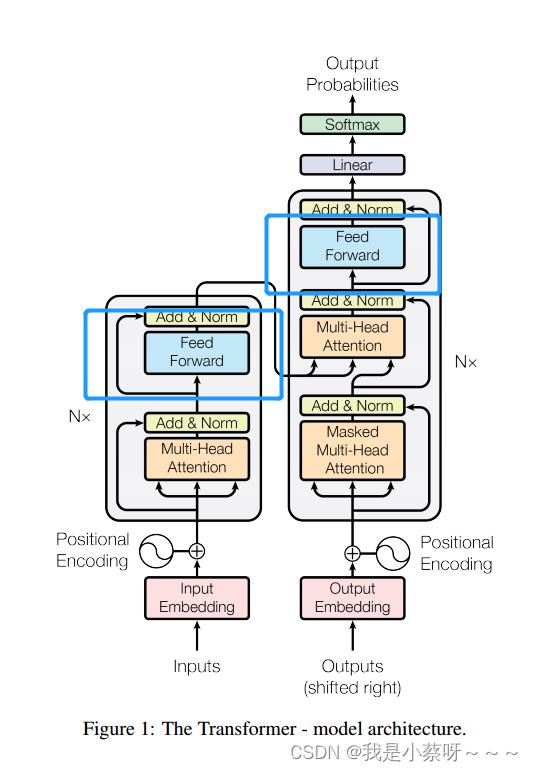
一、其实就是一个全连接的前馈网络(其实是一个MLP),不一样的是同一个MLP对每一个词都作用了一次(这个就是position-wise)。

二、x是一个512维,
W
1
W_1
W1会将其投到2048维(扩大了四倍),但是由于还要做残差连接,所以用
W
2
W_2
W2将其又投影到512维。FFN(x)说白了就是一个单隐藏层MLP,然后中间隐藏层把输入扩大了四倍,最后输出的时候又回到输入大小。
其实就是通过一个attention层全局的去拉了整个序列的信息,然后再用MLP做语义的转换。
Embeddings and Softmax
embedding,给任何一个词,学习一个长为d(本文d=512)的向量来表示。
编码器,解码器,在softmax之前,都需要一个embedding,本文为了方便,使用了相同的权重。在embedding layers乘了一个
d
m
o
d
e
l
\\sqrtd_model\\quad
dmodel(d=512)。因为在学习embedding的时候,会把每一个向量的L2 norm学成一个比较小的值,从而导致学习到的权重值比较小。因为要之后要加入Positional encoding,乘了一个
d
m
o
d
e
l
\\sqrtd_model\\quad
dmodel后这样会使得这两个在规模(scale)上差不多。
Positional Encoding
attention不会处理时序信息,当一句话的词颠倒时,对于attention来说没变化,但是这句话的语义已经发生了改变,所以需要positional encoding。
Why Self-Attention
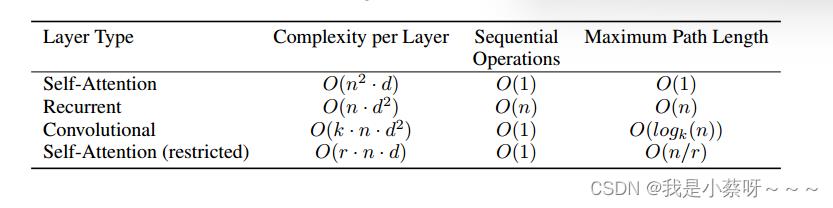
Complexity per Layer计算复杂度(越低越好)
Sequential Operations顺序的计算(越低越好,即下一步计算必须要等前面多少计算完成)
Maximun Path Length(越短越好,一个信息到另一个信息点的距离)
Training
Training Data and Bathing
byte-pair encoding (bpe)…
Hardware and Schedule
8 NVIDIA P100 GPUs…
Optimizer
Adam
模型越宽学习率越小
Regularization(正则化)
Residual Dropout
Transformer中对每个子层(self-attention层和全连接层)都进行了residual dropout。具体来说,在每个子层的输入和输出之间添加了一个残差连接,并在残差连接上应用了dropout。这样做的目的是防止过拟合和加速训练。
Label Smoothing
gitHubDailyShare深度学习论文精读
李沐老师在 GitHub 开源了一个《深度学习论文精读》项目。里面选取了近 10 年在深度学习领域比较有影响力的必读文章,并为之做视频讲解。
文章将覆盖 ResNet、Transformer、BERT、GPT3、GAN、AlphaGo 等深度学习领域的常用框架、算法以及实际应用等内容。
GitHub:github.com/mli/paper-reading
以上是关于论文精读(李沐老师)Attention Is All You Need的主要内容,如果未能解决你的问题,请参考以下文章
Transformer - Attention Is All You Need - 跟李沐学AI
Transformer - Attention Is All You Need - 跟李沐学AI
paper transformer - Attention Is All You Need - 跟李沐学AI笔记
Text to image论文精读 NAAF:基于负感知注意力的图像-文本匹配框架 Negative-Aware Attention Framework for Image-Text Matching