paper transformer - Attention Is All You Need - 跟李沐学AI笔记
Posted 一杯敬朝阳一杯敬月光
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了paper transformer - Attention Is All You Need - 跟李沐学AI笔记相关的知识,希望对你有一定的参考价值。
摘要
主流序列转录模型(sequence transduction models)是基于复杂的RNN和CNN模型,其包含编码器-解码器(encoder-decoder)架构。性能最好的模型里通常也会在编码器-解码器之间使用注意力机制。文章提出了一个简单的新模型Transformer--仅仅依赖于注意力机制,不使用RNN和CNN。在两个机器翻译任务上展示了特别好的性能--更好的并行度,训练时间更短。在WMT 2014 Englishto-German翻译任务上达到了28.4的BLUE score,比目前最好的结果提升了2个BLUE。在WMT 2014 English-to-French翻译任务中,做了一个单模型,效果优于其他的模型,在8个GPU上训练了3.5天达到了41.8的BLUE,其训练时间相对于文献中其他模型的训练时间来说很少。Transformer架构能够很好的泛化到其他任务。
导言
在RNN里面是把序列从左到右一步一步的往前计算。假设序列是一个句子,他就是一个词一个词的往前看,对t个词会计算一个输出(隐藏状态) ,其是由前一个时刻的隐藏状态
,其是由前一个时刻的隐藏状态 和当前
和当前 时刻的输入决定的。它是一个时序即一步一步的计算过程,难以并行。如果序列比较长的话,很早期的那些时序信息在后面的时候可能会丢掉,若不想丢掉,会需要比较大的,但是每一个时间步的都得存下来,会导致内存开销比较大。
时刻的输入决定的。它是一个时序即一步一步的计算过程,难以并行。如果序列比较长的话,很早期的那些时序信息在后面的时候可能会丢掉,若不想丢掉,会需要比较大的,但是每一个时间步的都得存下来,会导致内存开销比较大。
已经有相关工作将attention应用到了编码器-解码器里面了,主要是用于如何将编码器的东西有效的传给解码器,即和RNN是一起使用的。
背景
卷积网络替换循环神经网络来减少时序的计算。但是卷积神经网络难以建模长序列,因为卷积计算每次去看一个比较小的窗口(例如一个3*3的像素块),若两个像素隔得比较远,得用很多层卷积,一层一层堆上去才能把隔的较远的像素融合起来。但是使用Transformer里面的注意力机制,每次能看到所有的像素,一层就能看到整个序列。但是卷积可以有多输出通道,每一个输出通道可以认为是识别不一样的模式,想要获得类似多输出通道的效果,提出了多头的注意力机制(Multi-Head Attention)。
自注意力机制(self-attention)将单个序列的不同位置联系起来以计算序列的表示,之前的有些工作已经使用了自注意力机制。
基于循环attention机制的端到端的memory networks,而不是序列对齐的循环,在简单语言中的问答和语言建模任务中表现良好。
Transformer是第一个仅依赖于自注意力机制来做的编码器-解码器框架。
模型架构
编码器将序列的符号表示 映射成相同长度的序列的矩阵表示
映射成相同长度的序列的矩阵表示 。对于句子来说,
。对于句子来说, 可以看作是句子中第t个词在词表中的下标,
可以看作是句子中第t个词在词表中的下标, 代表的向量表示,n表示序列的长度。给定编码器的输出
代表的向量表示,n表示序列的长度。给定编码器的输出 ,解码器会生成长为m的序列
,解码器会生成长为m的序列 ,这里的n可以不等于m。解码器的词是一个一个生成的(自回归,例如生成
,这里的n可以不等于m。解码器的词是一个一个生成的(自回归,例如生成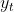 ,可以拿到编码器输出和t时刻前的解码器的输出
,可以拿到编码器输出和t时刻前的解码器的输出 ,过去时刻的输出会作为当前时刻的输入),这一点与编码器不同,编码器一次很可能能看完整个句子。
,过去时刻的输出会作为当前时刻的输入),这一点与编码器不同,编码器一次很可能能看完整个句子。
Transformer使用了一个编码器解码器的架构,将self-attention、point-wise、fully connecte layers堆叠在一起的。

编码器的输入:例如中译英,就是中文的句子。解码器的输入:解码器在做预测的时候是没有输入的,实际上解码器之前时刻的一些输出作为输入。(shifted right一个一个往右移)。
编码器解码器堆叠
编码器:由 个完全一样的层(layers)堆叠起来。每一个层里面有两个子层(sub-layers)。第一个子层是多头注意力子层(multi-head self-attention mechanism),第二个子层是一个全连接层(就是一个MLP)。每一个子层都用了一个残差连接,再接上layer normalization。每个子层的输出用式子可表示为
个完全一样的层(layers)堆叠起来。每一个层里面有两个子层(sub-layers)。第一个子层是多头注意力子层(multi-head self-attention mechanism),第二个子层是一个全连接层(就是一个MLP)。每一个子层都用了一个残差连接,再接上layer normalization。每个子层的输出用式子可表示为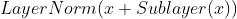 。因为残差网络需要输入x和子层的输出
。因为残差网络需要输入x和子层的输出 的维度是一样的,否则得做投影,简单起见,将embedding层和所有子层的输出维度统一为
的维度是一样的,否则得做投影,简单起见,将embedding层和所有子层的输出维度统一为 。
。
结论
文中提出的Transformer,是第一个完全基于注意力机制的序列转录模型--将编码器-解码器架构常用的循环层替换成了multi-headed self-attention。在机器翻译的任务上,Transformer的训练要比比循环层卷积层快很多。在WMT 2014 English-to-German 和 WMT 2014 English-to-French翻译任务上,达到了最好的效果。在 WMT 2014 English-to-German 任务上,效果优于所有的模型。很看好基于注意力机制模型的前景,并打算运用到其他任务上。我们计划将Transformer扩展到涉及输入和输出模式的文本以外的任务上,并研究local, restricted注意机制,以有效处理图像、音频和视频等。generation less sequential 也是一个研究方向。
附
batch norm VS layer norm
考虑二位输入的情况,每一行是样本,每一列是特征,batch norm就是每次在一个batch内将每一个列(每一个特征)变成均值0方差1。训练阶段在小批量里面的均值方差;算出全局的均值方差存起来在预测的时候用。还会学一个 出来,即可以把这个向量通过学习变为方差为某个值均值为某个值的东西。
出来,即可以把这个向量通过学习变为方差为某个值均值为某个值的东西。
同考虑二维输入,layer norm在很多时候和batch norm是一样的,不过layer norm是对每个样本做了normalization,即把每一行变为均值0方差1的向量,可以认为是把矩阵转置一下,做一个batch norm,再转置回去。
但是transformer里面的输入是三维的,输入的是一个序列的样本,每一个样本里面有很多个元素,每个元素有自己的embedding,形状是 ,这时候若用batch norm,每次取一个特征,把他的序列的元素以及batch全部搞出来
,这时候若用batch norm,每次取一个特征,把他的序列的元素以及batch全部搞出来 展平成一个向量
展平成一个向量 ,将其变为均值0方差1。对于layer norm,就是每次取一个样本,把它的embedding和batch全搞出来
,将其变为均值0方差1。对于layer norm,就是每次取一个样本,把它的embedding和batch全搞出来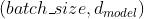 展平成一个向量
展平成一个向量 ,将其变为均值0方差1。对于这种变长的序列通常 layer norm 用的比较多,因为序列,每个样本的长度
,将其变为均值0方差1。对于这种变长的序列通常 layer norm 用的比较多,因为序列,每个样本的长度 可能会发生变化,见图蓝色batch norm,黄色layernorm,主要就是两种切法的不同,会带来计算均值方差的不同,若样本长度变化比较大,每次算一个batch里面的均值方差抖动相对较大,还有一点,预测的时候我们会记下全局的均值方差,若预测的样本比较长,我们在训练的时候没见到伸出去那么长的之前算出的均值方差不那么好用。layernorm是每一个样本自己算均值方差,也不需要存下全局均值方差,毕竟是针对样本的,反正无论长短都是在各自样本里面算的,相对来说稳定一些。
可能会发生变化,见图蓝色batch norm,黄色layernorm,主要就是两种切法的不同,会带来计算均值方差的不同,若样本长度变化比较大,每次算一个batch里面的均值方差抖动相对较大,还有一点,预测的时候我们会记下全局的均值方差,若预测的样本比较长,我们在训练的时候没见到伸出去那么长的之前算出的均值方差不那么好用。layernorm是每一个样本自己算均值方差,也不需要存下全局均值方差,毕竟是针对样本的,反正无论长短都是在各自样本里面算的,相对来说稳定一些。

以上是关于paper transformer - Attention Is All You Need - 跟李沐学AI笔记的主要内容,如果未能解决你的问题,请参考以下文章