Text to image论文精读 NAAF:基于负感知注意力的图像-文本匹配框架 Negative-Aware Attention Framework for Image-Text Matching
Posted 中杯可乐多加冰
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Text to image论文精读 NAAF:基于负感知注意力的图像-文本匹配框架 Negative-Aware Attention Framework for Image-Text Matching相关的知识,希望对你有一定的参考价值。
NAAF:Negative-Aware Attention Framework for Image-Text Matching是基于负感知注意力的图文匹配,其利用匹配片段的积极影响和不匹配片段的消极影响来共同推断图像-文本的相似性,文章由中国科学技术大学和北京邮电大学学者在2022CVPR上发表。
论文地址:https://ieeexplore.ieee.org/document/9879764
代码地址:https://github.com/CrossmodalGroup/NAAF.
作者博客地址:https://www.cnblogs.com/lemonzhang/p/16456403.html

注意:这篇论文主要讨论的是图像和文本的匹配,即语义一致性的方法。不是专用于做文本生成图像的系列论文,本篇文章是阅读这篇论文的精读笔记。
一、原文摘要
图文匹配作为一项基本任务,弥合了视觉和语言之间的鸿沟。这项任务的关键是准确测量这两种模式之间的相似性。先前的工作主要基于匹配的片段(即,具有高相关性的单词/区域)来测量这种相似性,同时低估甚至忽略了不匹配的片段的影响(即,低相关性的单词或区域),例如,通过典型的LeaklyReLU或ReLU操作,该操作迫使负分数接近或精确到零。这项工作认为,不匹配的文本片段(包含丰富的不匹配线索)对图像文本匹配也至关重要。
因此,我们提出了一种新的消极意识注意框架(NAAF),该框架明确地利用匹配片段的积极影响和不匹配片段的消极影响来共同推断图像-文本的相似性。NAAF(1)精心设计了一种迭代优化方法,以最大限度地挖掘不匹配的片段,促进更具辨别力和鲁棒性的负面影响,(2)设计了双分支匹配机制,以精确计算具有不同掩码的匹配/不匹配片段的相似性/不相似性程度。在两个基准数据集(即Flickr30K和MSCOCO)上进行的大量实验证明了我们的NAAF的卓越性能,达到了最先进的性能。
二、图像-文本匹配
图像文本匹配任务定义:也称为跨模态图像文本检索,即通过某一种模态实例, 在另一模态中检索语义相关的实例。例如,给定一张图像,查询与之语义对应的文本,反之亦然。具体而言,对于任意输入的文本-图像对(Image-Text Pair),图文匹配的目的是衡量图像和文本之间的语义相似程度(这也是文本生成图像中很重要的一个点)。
图片和文字由于模态的异构,存在极大的语义鸿沟。图文匹配的关键挑战在于准确学习图片和文本之间的语义对应关系,并度量它们的相似性。在现有的图像文本匹配方法中有两种范式:
- 第一种方法倾向于执行全局级匹配,即找到文本和整个图像之间的语义对应。他们通常将整体图像和文本投射到一个共同的潜在空间,然后匹配这两种模式。(CLIP可以被分为此类,其将图像和文本同时投影到一个计算矩阵中,计算其相似度)。
- 第二种范式侧重于检查局部级匹配,即图像中的显著区域和文本中的单词之间的匹配。局部级别匹配考虑了图像和文本之间的细粒度语义对应。AttnGAN的DAMSM就是基于这个原理,其将句子的图像和单词的子区域映射到一个公共语义空间,从而在单词级别测量图像-文本相似度,以计算图像生成的细粒度损失。
在局部级匹配的领域,基于注意力的匹配框架最近迅速成为主流,其关键思想是通过注意力关注来自另一模态的每个查询片段的相关片段来发现所有单词-图像区域对齐。
三、为什么提出NAAF?
显然匹配的片段(即,具有高相关性分数的单词区域对)将对最终的图像-文本相似性做出很大贡献,而不匹配片段(即具有低相关性分数的词区域对)的影响将被削弱甚至消除,例如,通过在注意力过程中迫使负分数接近或精确为零的典型LeakyReLU或ReLU。
现有的很多方法主要寻找匹配的片段,而低估或忽略了不匹配片段的影响,完全忽略了不匹配的文本片段在证明图像文本不匹配中的关键作用,将不可避免地容易产生假阳性匹配:
假阳性匹配:
包含许多匹配片段但有一些不匹配的文本片段的图像-文本对(直接表明图像-文本不匹配)仍然可以获得高相似度,并且可以正确地排在最前面,这肯定不是一个令人满意的结果,比如说下例两个男孩在一些树旁的路上踢足球:现有的方法主要寻找匹配的片段,例如“男孩”、“树”,以计算图像-文本(I-T)相似性,而不匹配的片段(例如“足球”)的影响被典型的LeaklyReLU或ReLU削弱或忽略,显然这并不是一个很优秀的匹配,但是由于他在大部分关键词上匹配得分高,其匹配结果会非常靠前,这就属于假阳性。
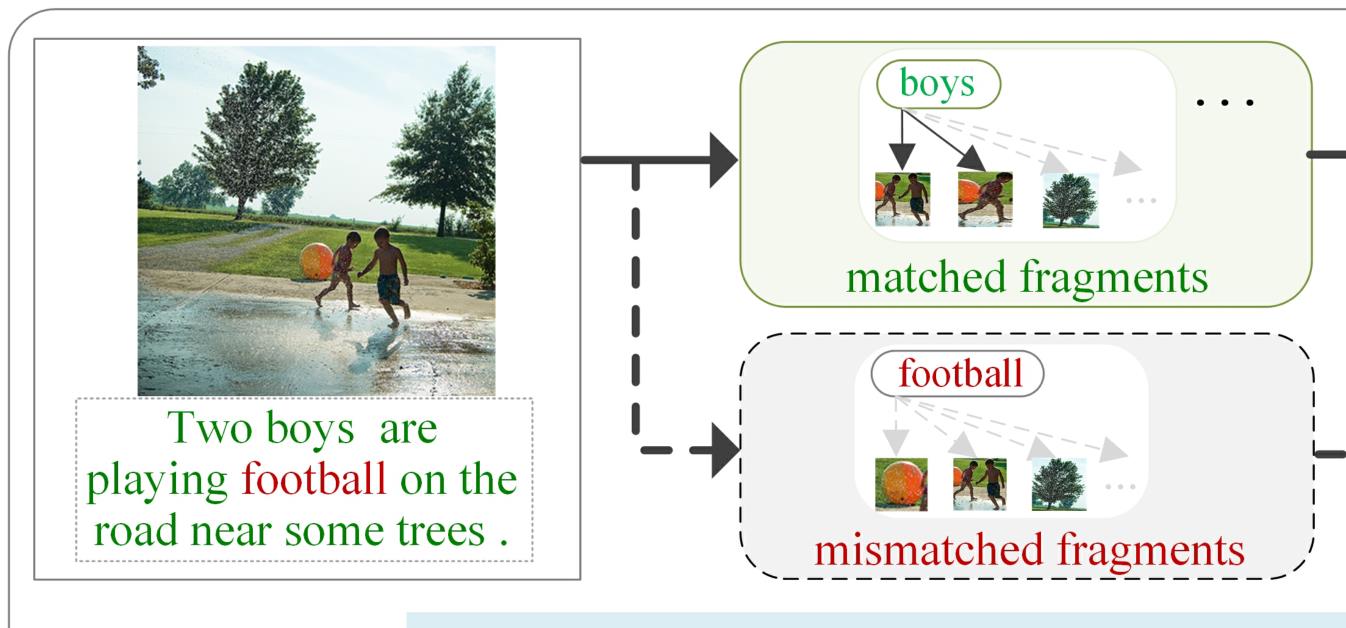
其主要集中于最大化匹配(即对齐)片段的效果,而低估或忽略了不匹配片段的线索作用。而合理的匹配框架应该同时考虑两个方面,即图像文本对的总体匹配分数不仅由匹配片段的积极影响决定,而且由不匹配片段的消极影响决定。可以充分的挖掘非对齐片段的负面作用,使原本检索在Top位置的错误匹配降低相似分值,对图像匹配度进行减分,如下图所示,就可以很容易消除假阳性。
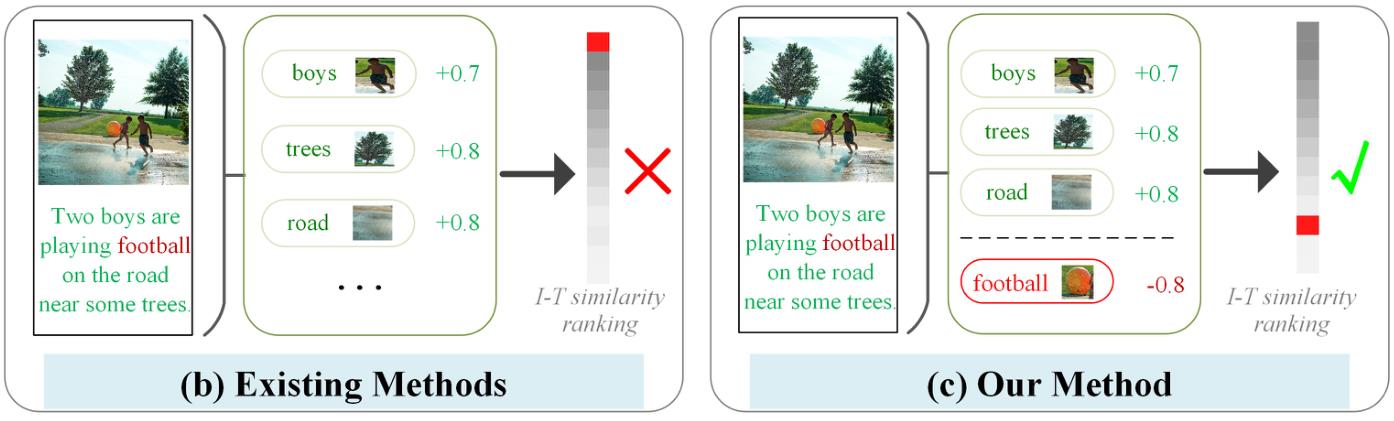
因此,作者提出了一种新的负感知注意力框架,该框架首次明确考虑了正匹配和负不匹配的片段,以联合测量图像-文本的相似性。与片面关注匹配片段的传统匹配机制不同,该注意力框架可以有效地挖掘不匹配的文本片段,以进一步利用这两种类型的线索进行联合相似性推断。并使用它们准确地反映两种模式之间的差异。消极感知注意框架NAAF由两个模块组成:
- 设计了一种双分支匹配来解决不匹配片段的利用率不足的问题,它包含了不同掩码下的消极和积极注意,一种用于精确计算不匹配片段之间的相似度,另一种用于计算匹配片段之间相似度。分别测量精确的相似度/相异度,以联合推断整体图像-文本相似度。
- 提出了一种新的迭代优化方法来显式地建模和挖掘不匹配的片段。
四、NAAF
NAAF的总体框架如图所示,可以看到,首先Feature Extraction提取图像特征和文本特征(这里不再展开),然后Negative-aware Attntion使用负效应和正效应进行负意识注意以测量图像和文本的相似性,其包括两个主要模块,用于显式地利用负不匹配和正匹配的文本片段来联合推断图像-文本相似性。1.不匹配挖掘模块使失配线索产生更稳健的负面影响。2.正负双分支匹配模块精确计算两种类型片段的正面和负面影响,从而测量总体相似性。
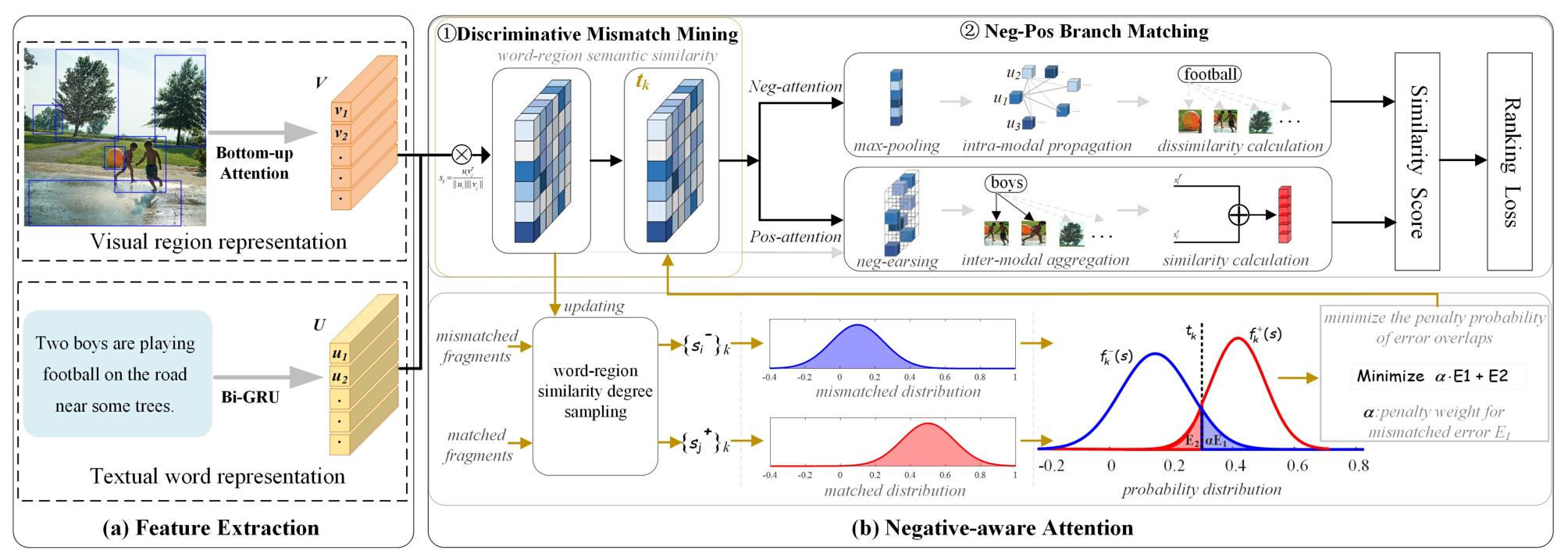
4.1、特征提取
- 视觉表征:给定图像V,利用
Visual Genome预训练的FasterRCNN检测显著对象和其他区域。然后,通过预训练的ResNet-101过平均池卷积特征提取检测区域。采用全连接层将每个区域映射到1024维特征。 - 文本表征:给定由m个单词组成的文本U,我们将每个单词热编码为1024维向量,并嵌入预先训练的
GloVe向量中,然后,向量被馈送到双向门控循环单元(BiGRU)中,以整合前向和后向上下文信息。最终的单词表示 u i u_i ui是双向隐藏状态的平均值。
4.2、Negative-aware Attntion
给定一个图像-文本对,它可能包含丰富的匹配和不匹配片段。本模块的目标就是充分利用这两类线索,以实现更准确的匹配性能。在NAAF框架中主要有两个模块:
- 不匹配挖掘模块:旨在通过最小化训练过程中匹配和不匹配相似性分布之间错误重叠的惩罚概率,明确建模和最大限度地挖掘不匹配片段。
- 正负双分支匹配模块:旨在通过设计的两个分支匹配,即负和正注意分支,精确计算负失配和正匹配的影响,以共同推断相似性。
1️⃣:不匹配挖掘模块
不匹配挖掘模块期望显式地和自适应地建模失配和匹配片段的相似性分布,旨在最大限度地分离它们,以实现有效的不匹配片段挖掘。
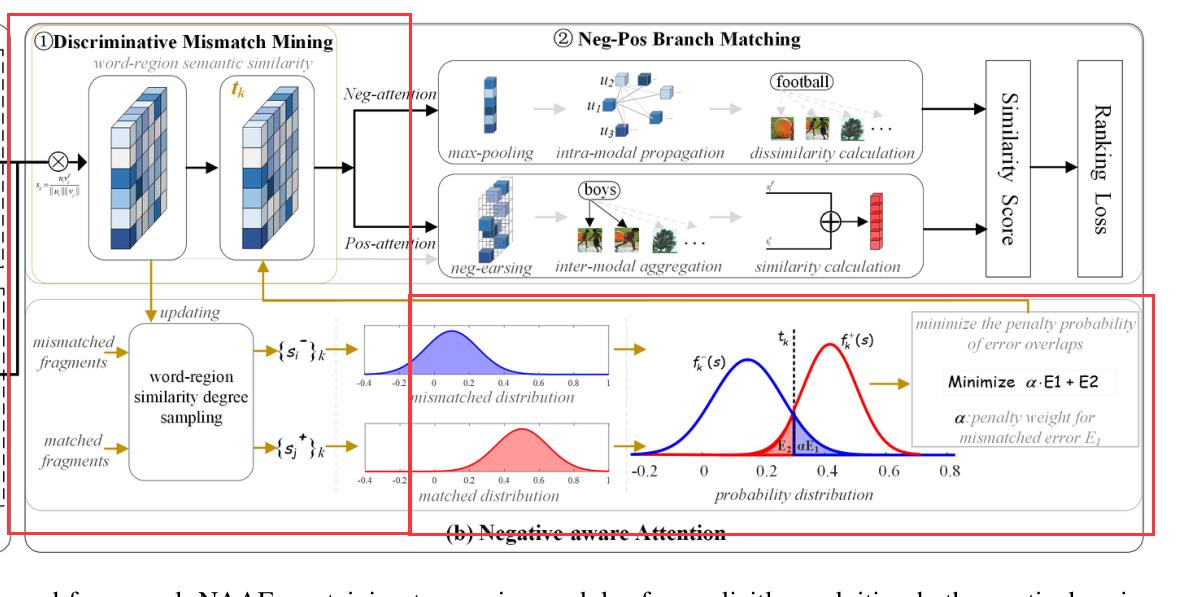
为此,在训练过程中,对于不匹配和匹配的单词区域片段对,首先对它们的相似度进行采样:
S k − = [ s 1 − , s 2 − , s 3 − , … , s i − , … ] S k + = [ s 1 + , s 2 + , s 3 + , … , s i + , … ] \\beginaligned S_k^- &=\\left[s_1^-, s_2^-, s_3^-, \\ldots, s_i^-, \\ldots\\right] \\\\ S_k^+ &=\\left[s_1^+, s_2^+, s_3^+, \\ldots, s_i^+, \\ldots\\right] \\endaligned Sk−Sk+=[s1−,s2−,s3−,…,si−,…]=[s1+,s2+,s3+,…,si+,…]
其中S-表示不匹配区域-单词的相似度分数,S+表示匹配区域-单词的相似度分数。
基于构造出的两个集合,可以分别建立匹配片段和不匹配片段的相似度分数s的概率分布模型:
分布模型公式表示为: f k − ( s ) = 1 σ k − 2 π e [ − ( s − μ k − ) 2 2 ( σ k − ) 2 ] , f k + ( s ) = 1 σ k + 2 π e [ − ( s − μ k + ) 2 2 ( σ k + ) 2 ] f_k^-(s)=\\frac1\\sigma_k^- \\sqrt2 \\pi e^\\left[-\\frac\\left(s-\\mu_k^-\\right)^22\\left(\\sigma_k^-\\right)^2\\right], f_k^+(s)=\\frac1\\sigma_k^+ \\sqrt2 \\pi e^\\left[-\\frac\\left(s-\\mu_k^+\\right)^22\\left(\\sigma_k^+\\right)^2\\right] fk−(s)=σk−2π1e[−2(σk−)2(s−μk−)2],fk+(s)=σk+2π1e[−2(σk+)2(s−μk+)2]
其中(µ−k,σ−k)和(µ+k,σ+k)分别是两种分布的平均值和标准差:
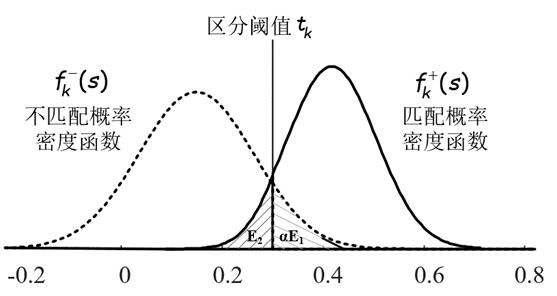
分别得到两个相似度分布建模后,可以用一个显式的边界t在匹配片段和不匹配片段之间进行区分,如图所示,相似度分数大于 t k t_k tk的区域-单词对被视为匹配片段,反之则为不匹配片段,但是不可避免的就会出现两种误判:将实际上不匹配的片段区分为匹配的 和 将实际上匹配的片段误认为是不匹配的。而此模块的目的是最大限度的挖掘出不匹配片段,找出一个最优的边界t,使得区分错误的概率最低,保证识别的准确性,即解决如下优化问题:
min t α ∫ t + ∞ f k − ( s ) d s + ∫ − ∞ t f k + ( s ) d s , s.t. t ≥ 0 \\beginarrayll \\min _t & \\alpha \\int_t^+\\infty f_k^-(s) d s+\\int_-\\infty^t f_k^+(s) d s, \\\\ \\text s.t. & t \\geq 0 \\endarray mint s.t. α∫t+∞fk−(s)ds+∫−∞tfk+(s)ds,t≥0
其中t是该问题的决策变量,α是惩罚参数。
对于该问题的最优解求解,我们首先搜索它的一阶导数的零点,并根据可行域的约束条件在(t ≥ 0)处截断,得到最优解为: 以上是关于Text to image论文精读 NAAF:基于负感知注意力的图像-文本匹配框架 Negative-Aware Attention Framework for Image-Text Matching的主要内容,如果未能解决你的问题,请参考以下文章 论文精读Deep Rectangling for Image Stitching: A Learning Baseline 论文精读Deep Rectangling for Image Stitching: A Learning Baseline 论文精读Deep Rectangling for Image Stitching: A Learning Baseline
t
k
=
[
(
(
β
2
k
2
−
4
β
1
k
β
3
k
)
1
2
−
β
2
k
)
/
(
2
β
1
k
)
]
+
其中
β
1
k
=
(
σ
k
+
)
2
−
(
σ