论文精读Deep Rectangling for Image Stitching: A Learning Baseline
Posted spearhead_cai
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了论文精读Deep Rectangling for Image Stitching: A Learning Baseline相关的知识,希望对你有一定的参考价值。
代码:https://github.com/nie-lang/DeepRectangling
链接:https://arxiv.org/abs/2203.03831
概览
目前图像拼接的一个问题是拼接后会产生不规则的边界,如下图1 b所示。目前解决这类问题主要是通过图像矩形化方法,并且通常是分为两个阶段,第一阶段搜索初始网格,第二阶段优化网格来完成网格变形,然后 warp 输入的拼接图像来生成矩形图像,不过这类方案只适合处理具有丰富线性结构的图像,对于带有非线性结构的人物和风景会有明显失真的情况。
本文通过提出第一个图像矩形的深度学习解决方案来解决这些问题。具体来说,我们预先定义了一个刚性目标网格,并且只估计一个初始网格以形成网格变形,从而有助于一个紧凑的单阶段解决方案。使用具有残差渐进回归策略的全卷积网络预测初始网格。为了获得具有高内容保真度的结果,提出了一个综合目标函数,以同时鼓励边界矩形、网格形状保持和内容感知自然。此外,我们构建了第一个图像拼接矩形数据集,在不规则边界和场景中具有很大的多样性。实验证明了我们在数量和质量上都优于传统方法。

主旨
作者想解决什么问题
由于图像拼接的时候,目前大多数方法主要重点优化全局或者局部 warp 来对其不同图像的重叠区域,而非重叠区域会受到不规则边界的影响。
作者通过什么理论/模型来解决这个问题
图像矩形化
作者给出的答案是什么?
提出一种一阶段的图像矩形化方法,具体来说就是设计了一个简单但有效的全卷积网络,以使用残差渐进回归策略从拼接图像中估计内容感知初始网格,然后使用预定义的刚性目标网格进行高效并行计算。此外,提出了一个由边界项、网格项和内容项组成的综合目标函数,以同时鼓励边界矩形、网格形状保持和内容感知自然。
作者为什么研究这个课题?
-
不规则的边界会影响观感;
-
目前采用的图像矩形化仅适合具有丰富线性结构的图像,对带非线性结构的人物和风景会有明显失真情况;
目前这个课题的研究进行到哪一个阶段?
对于不规则边界的处理,目前有这几种方法:
-
通过裁剪方法来处理,但是裁剪会降低拼接图像的 FOV,这和图像拼接的目的矛盾;
-
采用图像补全来将缺失区域合成为矩形图像,但目前还没有相关工作为不规则边界设计掩码,并且 SOTA 的图像补全工作对图像拼接的处理效果也不让人满意;并且可能添加一些看起来和谐但是和现实不同的内容,这在自动驾驶等高安全性应用中是不可靠的;
-
而图像矩形化方法主要是通过网格变形来将拼接图像 warp 为矩形,但它们只能保留具有线性结构,比如建筑物、盒子、柱子等,对非线性结构,比如肖像、风景,都会产生失真;另外就是它们采用两阶段,并不好实现并行加速;
研究方法
提出了第一阶段学习基线,即我们预定义了一个刚性目标网格并仅预测一个初始网格。具体来说,我们设计了一个简单但有效的全卷积网络,以使用残差渐进回归策略从拼接图像中估计内容感知初始网格。此外,提出了一个由边界项、网格项和内容项组成的综合目标函数,以同时鼓励边界矩形、网格形状保持和内容感知自然。与现有方法相比,由于我们的内容约束中的有效语义感知,我们的内容保存能力更通用(不限于线性结构)和更健壮。
Traditional Baseline
对于一个经典的传统方法,一般是分为两阶段的:局部阶段和全局阶段(如下图2 a 所示).
Stage 1:局部阶段。首先,在拼接图像中插入丰富的接缝,使用接缝雕刻算法 [1] 得到初步的矩形图像。然后,在初始矩形图像上放置一个规则网格并移除所有接缝以获得具有不规则边界的拼接图像的初始网格。
Stage 2:全局阶段。此阶段通过优化能量函数来解决最佳目标网格,以保留有限的感知属性,例如直线。
他们通过将拼接图像从初始网格扭曲到目标网格来生成矩形图像。

Learning Baseline
正如上图 b 所示,本文提出的学习基线是一种一阶段方法。
给定拼接图像,我们的解决方案只需要通过神经网络预测内容感知的初始网格。至于目标网格,我们将其预定义为刚性形状。此外,刚性网格形状可以很容易地使用矩阵计算来加速后向插值。通过将拼接图像从预测的初始网格扭曲到预定义的目标网格,可以获得矩形图像。
与传统的基线相比,学习基线由于是一阶段的管道,效率更高。内容保留能力使我们的矩形结果在感知上更加自然。
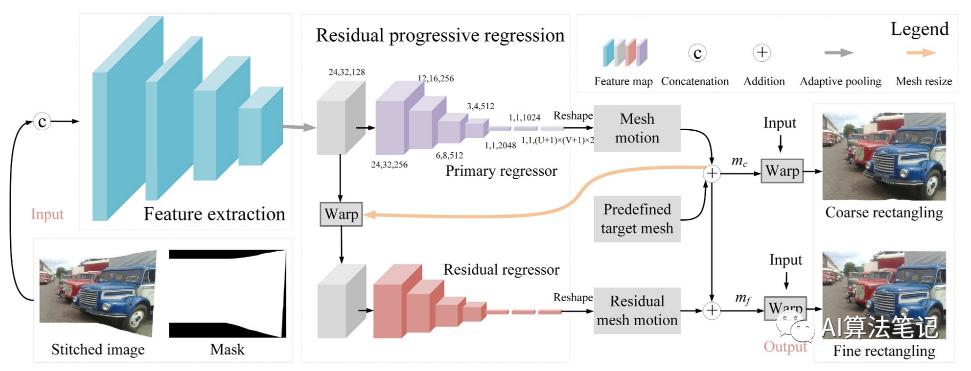
网络结构
与图像补全任务类似,缝合掩码也包含在建议网络的输入中。如下图所示,我们将通道维度上的拼接图像 I 和掩码 M 连接起来作为输入。输出是预测的网格运动。
特征提取器。我们堆叠简单的卷积池块以从输入中提取高级语义特征。形式上,采用 8 个卷积层,其滤波器数量分别设置为 64、64、64、64、128、128、128 和 128。在第 2、第 4 和第 6 卷积层之后使用最大池化层。
网格运动回归器。在特征提取之后,使用自适应池化层来固定特征图的分辨率。随后,我们设计了一个全卷积结构作为网格运动回归器,以基于常规网格预测每个顶点的水平和垂直运动。假设网格分辨率为 U × V ,输出体积的大小为 (U + 1) × (V + 1) × 2。
残差渐进回归。观察到扭曲的结果可以再次被视为网络输入,我们设计了一种残差渐进回归策略,通过渐进的方式估计准确的网格运动。首先,我们不直接使用扭曲图像作为新网络的输入,因为这会使计算复杂度加倍。相反,我们扭曲了中间特征图,在计算量略有增加的情况下提高了性能。然后,我们设计了两个具有相同结构的回归器来分别预测初级网格运动和残差网格运动。尽管它们共享相同的结构,但由于不同的输入特征,它们被指定用于不同的任务。
目标函数
我们采用包含三个损失函数的综合目标函数来优化网络参数。优化目标如下所示:
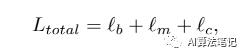
其中 分别表示边界项、网格项和内容项。
内容项
传统方法 [7, 14] 通过保留直线/测地线的角度来保留图像内容,无法处理其他非线性结构。为了克服它,我们建议从两个不同的角度学习内容保存能力。
外观损失 。给定预测的主网格 和最终网格 ,我们强制矩形结果在外观上接近矩形标签 R,如下所示:
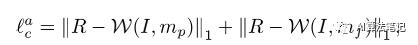
其中 W 表示 warp 操作。
感知损失。为了让结果感知上更加自然,我们在高级语义感知中最小化矩形结果和标签之间的 L2 距离,如等式3:
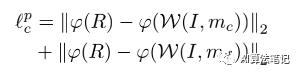
其中 φ(·) 表示从 VGG19 [25] 的“conv4 2”层提取特征的操作。以这种方式,可以感知各种感知特性(不限于线性结构)。
总之,内容损失是通过同时强调外观和语义感知的相似性形成的,如下所示:
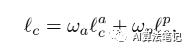
其中 分别表示两个损失的权重。
网格项
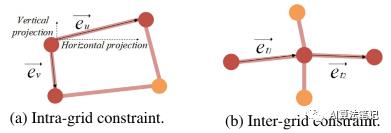
为了防止矩形图像中的内容失真,预测的网格不应过度变形。因此,我们设计了一个网格内约束和一个网格间约束来保持变形网格的形状。
网格内约束。在网格中,我们对网格边缘的大小和方向施加约束。如下图a所示,我们鼓励每个水平边缘 的水平投影方向向右,连同其范数大于阈值 α(假设拼接图像的分辨率为H×W)。我们使用惩罚 来描述这个约束如下:
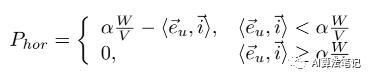
其中 i 是指向右侧的水平单位向量。对于每个网格中的垂直边 ,我们施加类似的惩罚 ,如下所示:
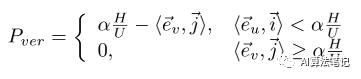
其中 j 是指向底部的垂直单位向量。网格内约束损失如下式所示,它可以有效防止网格内形状变形。
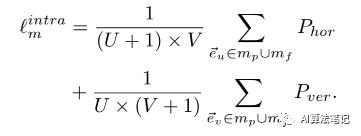
网格间约束。我们还采用网格间约束来鼓励相邻网格一致地变换。如上图b所示,两个连续的变形网格边缘 被鼓励共线.

我们如上所述制定网格间网格损失,其中 N 是网格中两个连续边的元组数。
总之,总的网格项总结如下:
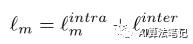
边界项
至于边界项,我们约束掩码而不是预测网格。给定拼接图像的 0-1 蒙版(如图 3 所示),我们扭曲蒙版并将扭曲蒙版约束为接近全一矩阵 E,如下所示:
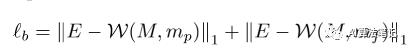
数据准备
为了训练深度图像矩形网络,我们构建了一个图像矩形数据集(DIR-D),其中每个样本都是由拼接图像(I)、掩码(M)和矩形标签(R)组成的三元组。我们通过以下步骤准备此数据集:
第1 步:采用 ELA [16] 拼接来自 UDISD 数据集 [24] 的图像,以收集大量真实拼接图像。然后我们忽略那些外推面积小于整个图像 10% 的图像。
第 2 步:使用 He 等人 [7]的算法从这些真实拼接图像中生成丰富的不同网格变形 (),如图 5(右)所示。
第 3 步:应用网格变形的逆向()将真实矩形图像(来自 MS-COCO [20] 和收集的视频帧)扭曲到合成拼接图像,如下图 5(左)所示。可以通过扭曲全为一的矩阵来获得掩码。然后我们得到真实矩形图像 ®、合成拼接图像 (I) 和扭曲矩阵 (M) 的三元组。
第 4 步:手动消除三元组中 I 有失真的数据。每次手动操作需要 5-20 秒。形式上,我们将这个过程重复三个时期,并从 60,000 多个样本中保留 5,705 个三元组。
第 5 步:将真实拼接图像混合到我们的训练集以增加泛化能力。具体来说,我们在步骤 2 中从 5000 多个样本中过滤掉了 653 个 R 没有失真的样本。
总之,我们准备了具有广泛不规则边界和场景的 DIR-D 数据集,其中包括 5,839 个用于训练的样本和 519 个用于测试的样本。数据集中的每张图像的分辨率为 512 × 384。

实验结果
实验配置
网络的优化方法采用 Adam 优化器,学习率初始值为 ,并采用指数衰减的学习率下降策略,总共迭代次数是 100k。Batch 大小为 4,激活函数采用 RELU,但回归器的最后一层不采用激活函数。分别设置为 1,以及 0.125。UXV 设置为 8x6,并且采用 Tensorflow 实现。采用一个NVIDIA RTX 2080 Ti 的 GPU来完成训练和推理过程。
处理一张 10 兆像素的图像只需不到 0.4 秒。与 [7] 的实验配置类似,输入图像将首先被下采样到 1 兆像素,并以下采样分辨率解决网格变形。然后网格变形将被上采样,并且可以通过使用该上采样变形扭曲全分辨率输入图像来获得矩形结果。运行时间主要是扭曲(插值)全分辨率图像。
比较结果
定量比较
我们将我们的解决方案与 He 等人 [7] 在 DIR-D 上的方法进行了比较,其中每种方法测试了 519 个样本。我们用标签计算平均 FID [9]、SSIM 和 PSNR 来评估这些解决方案。定量结果如表 1 所示,其中‘Reference’以拼接图像作为矩形结果供参考。
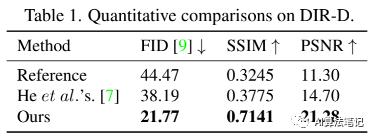
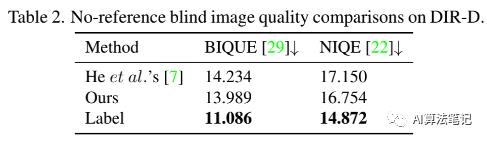
从这个表中可以看出,在 DIR-D 的每个指标中,所提出的学习解决方案都明显优于传统解决方案。这种显着的改进归功于我们可以保留线性和非线性结构的内容保留属性。此外,当矩形结果中物体的位置稍有变化时,它看起来也很自然,但度量可能会有所不同,这使得定量实验不能完全令人信服。因此,我们进一步进行了盲图像质量评估的比较。如表 2 所示,我们采用 BIQUE [29] 和 NIQE [22] 作为“无参考”评估指标,我们的解决方案可以产生更高质量的结果。这些评估方法是无意识的方法,试图在不需要任何训练数据的情况下量化失真。我们添加了“标签”的评估以供参考,这表明了性能的上限。
定性比较
为了全面比较定性结果,我们将测试集分为两部分。第一部分包含丰富的线性结构,适合传统的基线,而第二部分包含大量的非线性结构,例如肖像。
从图 7 的结果中,我们可以观察到我们的方法在两个场景中明显优于传统解决方案。我们的优势在于能够保持网格形状保持和内容感知自然的内容保留能力。由于线检测能力有限,传统解决方案在具有线性结构的场景中表现不佳。失败发生在具有非线性对象的肖像中,因为非线性属性不包括在其优化的能量中。

用户研究
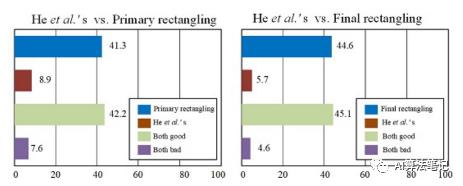
图像矩形的动机是用户对拼接图像中不规则的边界不满意。因此,我们的目标是制作让大多数用户满意的矩形图像。
我们对视觉偏好进行用户研究。形式上,我们将 He 等人的算法与我们的初级矩形和最终矩形(如图 3 所示)一一进行比较。每次,三个图像都显示在一个屏幕上:输入、He 等人的矩形和我们的(主要或最终)。我们每次都打乱不同方法的顺序。用户可以放大图像并且需要选择哪个结果是优选的。在这项研究中,我们邀请了 10 名参与者,其中包括 5 名具有计算机视觉背景的研究人员/学生和 5 名社区以外的志愿者。结果如图6所示,我们的解决方案受到更多用户的青睐。
跨数据集比较
在跨数据集评估中,我们采用 DIR-D 数据集训练模型,然后用其他数据集进行测试。
形式上,我们采用不同的图像拼接方法(SPW [18]、LCP [10] 和 UDIS [24])来拼接经典图像拼接数据集 [4,5,10,30]。然后,使用不同的算法将拼接的图像用于矩形。结果如图 8a 所示,我们的解决方案在矩形结果中产生的失真更少。
为了展示我们在更一般的场景中的有效性,其中没有消除伪影和投影失真,我们展示了图像拼接失败案例的矩形结果。如图 8b 所示,我们的方法仍然有效。

消融实验
本文提出的方法简单但有效。我们在 DIR-D 上验证每个模块的有效性。
损失函数。我们将残差回归器作为基线结构,并评估目标函数中不同约束项的有效性。如表 3 的实验 1-3 所示,内容项和网格项都可以显着提高我们的性能。
网格分辨率。我们测试了 4×3、8×6 和 16×12 的不同网格分辨率。如表 3 的实验 3-5 所示,4×3 网格降低了矩形性能,而 8×6 网格和 16×12 网格给出了相似的结果。然而,16 × 12 网格带来了更多的计算成本,因此我们在实现中采用了 8 × 6 网格。
残差渐进回归。我们在表 3 的实验 6-7 中验证了我们的残差渐进回归策略的有效性,其中残差回归器继续基于主回归器细化矩形结果。尽管对 DIR-D 数据集的改进很小,但这种策略增强了我们的泛化能力,以避免其他数据集的边界不均匀,如图 9 所示。


推荐阅读的学习笔记
公众号后台回复这些关键词,可以获得相应的资料:
-
回复”入门书籍“,获取机器学习入门资源,包括书籍、视频以及 python 入门书籍;
-
回复”数据结构“,获取数据结构算法书籍和 leetcode 题解;
-
回复”多标签“,获取使用 keras 实现的多标签图像分类代码和数据集
-
回复“pytorch 迁移学习”,获取 pytorch 的迁移学习教程代码
-
回复“py_ml",获取初学者的机器学习入门教程代码和数据集
如果想评论可以点击阅读原文,进行评论互动,谢谢!
以上是关于论文精读Deep Rectangling for Image Stitching: A Learning Baseline的主要内容,如果未能解决你的问题,请参考以下文章