归一化处理
Posted 魔法少女斯内普
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了归一化处理相关的知识,希望对你有一定的参考价值。
1. 为什么要进行归一化处理?
例:假设放假预测,自变量为面积,房间数两个,因变量为房价。得到等式:
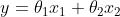
其中 代表房间数,
代表房间数,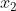 代表面积。
代表面积。
在实验中寻找最优解的过程也就是在使得损失函数值最小的theta1,theta2。
数据没有归一化的时候,面积数的范围可以从0~1000,房间数的范围一般为0~10,可以看出面积数的取值范围远大于房间数。数据没有归一化的表达式,可以为:
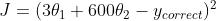
而数据归一化之后,损失函数的表达式可以表示为:
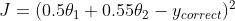
两张图代表数据是否归一化的输出结果寻优过程,两幅图代码的是损失函数的等高线。
未归一化: 归一化:
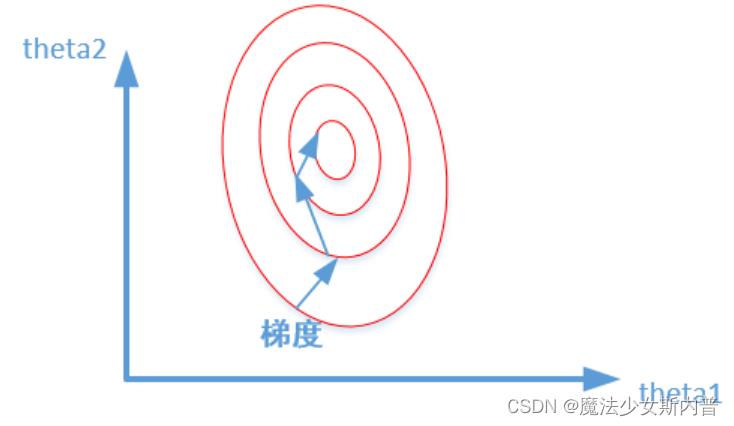
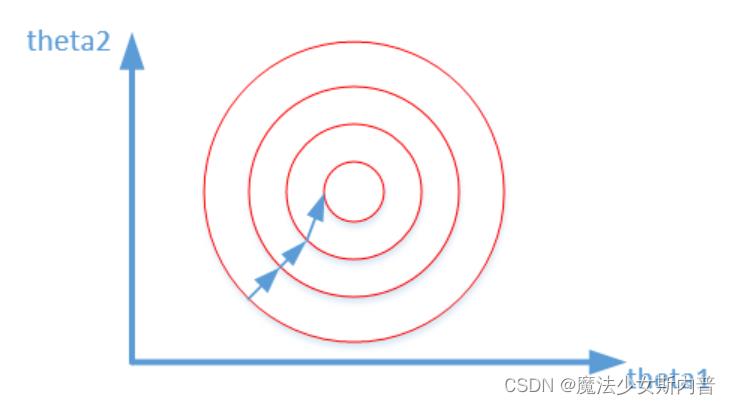
2. 好处与目的
由上可知,在机器学习领域中,不同评价指标(即特征向量中的不同特征就是所述的不同评价指标)往往具有不同的量纲和量纲单位,这样的情况会影响到数据分析的结果,
为了消除指标之间的量纲影响,需要进行数据标准化处理,以解决数据指标之间的可比性。原始数据经过数据标准化处理后,各指标处于同一数量级,适合进行综合对比评价。其中,最典型的就是数据的归一化处理。
简而言之,归一化的目的就是使得预处理的数据被限定在一定的范围内(比如[0,1]或者[-1,1]),从而消除奇异样本数据导致的不良影响。
奇异样本数据的存在会引起训练时间增大,同时也可能导致无法收敛,因此,当存在奇异样本数据时,在进行训练之前需要对预处理数据进行归一化;反之,不存在奇异样本数据时,则可以不进行归一化。
- 目的: 将不同尺度上的评判结果统一到一个尺度上,从而可以作比较,作计算
- 好处:1)加快了梯度下降求最优解的速度,加快训练网络的收敛性;2)有可能体高精度
3.归一化的方法
(1)线性归一化。 也称min-max标准化、离差标准化;是对原始数据的线性变换,使得结果映射到【0,1】之间。转换函数如下:

较适用在数值比较集中的情况;缺陷:如果max和min不稳定,很容易使得归一化结果不稳定,使得后续使用效果也不稳定。实际使用中可以用经验常量来替代max和min。
应用场景:在不涉及距离度量、协方差计算、数据不符合正太分布的时候,可以使用第一种方法或其他归一化方法(不包括Z-score方法)。比如图像处理中,将RGB图像转换为灰度图像后
将其值限定在[0 255]的范围
(2)Z-score标准化
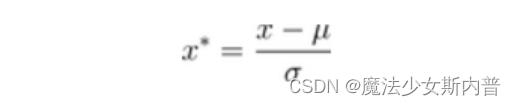
其中,μ、σ分别为原始数据集的均值和方法。
- 将原始数据集归一化为均值为0、方差1的数据集
- 该种归一化方式要求原始数据的分布可以近似为高斯分布,否则归一化的效果会变得很糟糕。
应用场景:在分类、聚类算法中,需要使用距离来度量相似性的时候、或者使用PCA技术进行降维的时候,Z-score standardization表现更好。
(3)神经网络归一化
本归一化方法经常用在数据分化比较大的场景,有些数值很大,有些很小。通过一些数学函数,将原始值进行映射。
该方法包括 log,正切等,需要根据数据分布的情况,决定非线性函数的曲线:
-
log对数函数归一化
y = log10(x)
即以10为底的对数转换函数,对应的归一化方法为:
x' = log10(x) /log10(max)
其中max表示样本数据的最大值,并且所有样本数据均要大于等于1.
-
反正切函数归一化
x' = atan(x)*(2/pi)
使用这个方法需要注意的是如果想映射的区间为[0,1],则数据都应该大于等于0,小于0的数据将被映射到[-1,0]区间上.
(4)L2范数归一化
定义:特征向量中每个元素均除以向量的L2范数:

4. 标准化和归一化
- 区别: 标准化是指在不改变数据分布情况下,将数据处理为均值为0,标准差为1的数据集合。 归一化是指将数据缩放到[0,1]范围内。
- 区别和用途: 归一化和标准化虽然都是在保持数据分布不变的情况下(为什么能够保持数据的分布不变?因为两者本质上都只是对数据进行线性变化),对数据进行处理,但是从公式上面还是能够明显看出来,归一化的处理只是和最大值最小值相关,标准化却是和数据的分布相关(均值,方差),所以标准化的统计意义更强,是是对于数据缩放处理的首选。只是有些特殊场景下,比如需要数据缩放到[0,1]之间(标准化并不保证数据范围),以及在一些稀疏数据场景,想要保留0值,会采用到归一化,其他的大部分时候,标准化是首选。
5.什么时候用归一化
(1)如果对输出结果范围有要求,用归一化。
(2)如果数据较为稳定,不存在极端的最大最小值,用归一化。
(3)如果数据存在异常值和较多噪音,用标准化,可以间接通过中心化避免异常值和极端值的影响。
【参考】
2. 如何理解归一化(normalization)? - 知乎
数据的归一化处理
我输入一些数据比如说,a,b,c,d……,经过归一化处理后得到一组数据,我用归一化后的这组数据进行计算得到x,y,z……,我怎样将x,y,z……,反归一化处理,他们的比例还能按照以前的计算吗?
谢谢!
那我该怎么办呢?
是的,把需要处理的数据经过处理后(通过某种算法)限制在你需要的一定范围内。首先归一化是为了后面数据处理的方便,其次是保证程序运行时收敛加快。
归一化的具体作用是归纳统一样本的统计分布性。归一化在0-1之间是统计的概率分布,归一化在某个区间上是统计的坐标分布。归一化有同一、统一和合一的意思。
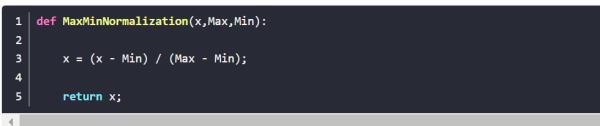
1、(0,1)标准化:
这是最简单也是最容易想到的方法,通过遍历feature vector里的每一个数据,将Max和Min的记录下来,并通过Max-Min作为基数(即Min=0,Max=1)进行数据的归一化处理:
LaTex:{x_normalization=\\fracx-MinMax-Min
Python实现:
2、Z-score标准化:
这种方法给予原始数据的均值(mean)和标准差(standard deviation)进行数据的标准化。经过处理的数据符合标准正态分布,即均值为0,标准差为1,这里的关键在于复合标准正态分布,个人认为在一定程度上改变了特征的分布,关于使用经验上欢迎讨论,我对这种标准化不是非常地熟悉。

归一化方法
有两种形式,一种是把数变为(0,1)之间的小数,一种是把有
量纲
表达式
变为无量纲表达式。
1、把数变为(0,1)之间的小数
主要是为了数据处理方便提出来的,把数据映射到0~1范围之内处理,更加便捷快速,应该归到
数字信号处理
范畴之内。
2、是把有量纲表达式变为无量纲表达式
归一化是一种简化计算的方式,即将有量纲的表达式,经过变换,化为无量纲的表达式,成为纯量。 参考技术B 那你就看看你的处理流程,你觉得是可能的吗?
至少我的感觉是,你归一化了,那么很多不同的数据可能会在归一化后得到相同的结果,那你肯定无法区分这些数据吧
----------------------------------------------------------
额。。我根本不知道你在做的什么,怎么知道该怎么办呢。。
笼统的来讲,如果你需要那些归一化之前的数据,就应该保留他们的一个副本啊 参考技术C 归一化以后,数据本身已经发生变化了,或者说被替代了,不可能有反归一化这个过程~~
以上是关于归一化处理的主要内容,如果未能解决你的问题,请参考以下文章
机器学习系列文章——特征的处理与选择(归一化标准化降维PCA)