机器学习面试题
Posted 把把C的程序猿
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习面试题 相关的知识,希望对你有一定的参考价值。
机器学习面试题
1.机器学习项目流程详细
1.1定位数学问题
首先进行机器学习项目时,需要对自己的训练目标进行明确定位,明确可以获取怎么样的数据(离散、连续)。目标是一个分类还是回归或者聚类,明确自己可以获得的数据量,选择合适的算法
1.2获取数据
数据决定了机器学习的结果上限,对于数据的选取,对于分类问题的,数据不能偏斜太过严重。
了解数据的量级,比如说有多少样本,多少个特征,可以估算出其对内存的消耗程度,判断训练过程中内存是否能够放得下。如果放不下就得考虑改进算法或者使用一些降维的技巧了。
1.3特征预处理与特征选择
对于模型来说,良好的数据能够提取出很好的特征,使得模型发挥出很好的效果。
特征预处理、数据清洗就是对于模型来说很关键的一步。在模型训练优化中,往往使算法效果和性能到达显著提高点效果,都是特征预处理与特征选择中做出调整。
具体步骤包含:归一化、离散化、因子化、缺失值处理、去除共线性等。
1.4训练模型与调优
对于基于python实现算法训练,现在大部分算法都已经实现python库封装了,直接调用即可,真正考验水平的是调整这些算法的参数,使得算法更加优良。
1.5模型判定
模型判定就是告诉模型调优的具体调整方向和思路的。
过拟合、欠拟合是判断模型好不好的重要一步。常见的方法有交叉验绘制学习曲线等。
过拟合的基本思路是增加数据降低模型复杂度。欠拟合的基本思路是提高特征数量和质量,增加模型复杂度。
1.6模型集成
对于一些单个模型无论怎样调优模型效果都不是很好的,这时候需要对模型进行集成融合,常见的模型集成如基于决策树的随机森林。类似的还有Bagging、Boosting等。
1.7上线测试
对于开发模型,模型的成与败取决于在线上真实运行下,观察运行的效果。这里不单需要评估模型的准确误差等情况,还包括模型运行的时间复杂度,空间复杂度、稳定性等。
2.有监督学习和无监督学习的区别
2.1监督学习
监督学习是指学生从老师那里获取知识、信息,老师提供对错指示、告知最终答案。学生在学习过程中借助老师的提示获得经验、技能,最后对没有学习过的问题也可以做出正确解答。
在监督学习中,我们只需要给定输入样本集,机器就可以从中推演出指定目标变量的可能结果。机器只需从输入数据中预测合适的模型,并从中计算出目标变量的结果。要实现的目标是“对于输入数据X能预测变量Y”
2.2无监督学习
无监督学习是指在没有老师的情况下,学生自学的过程。学生在学习的过程中,自己对知识进行归纳、总结。无监督学习中,类似分类和回归中的目标变量事先并不存在。要回答的问题是“从数据X中能发现什么”。
2.3常用算法

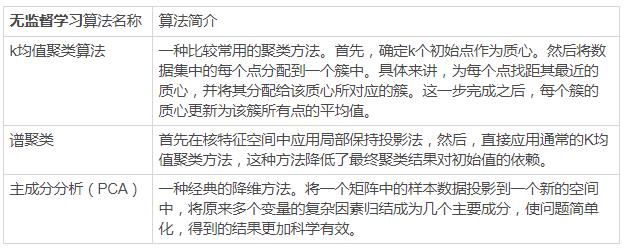
在深度学习应用中实现的机器学习的技术,也包含监督学习与无监督学习。常见的卷积神经网络就是一种监督学习方法,比如说图像分类(人脸识别,猫狗识别、行为识别等)。对于无监督学习方法中,有生成对抗网络(GAN),GAN经常被用来做图像生成。
3.数据归一化处理的作用
注意:对于需要做归一化的数据,是因为数据各维度之间量纲不同(数据的单位属性不同,如体重与身高,当然这里需要对选取的算法来判断),对于没有量纲问题的,最好不要做归一化处理。
做数据归一化处理是需要结合选取的算法综合考虑的,比如:
- SVM:数据在各维度进行不均匀的伸缩后,最优解于原来不等价需要归一化。
- LR:数据在各维度不均匀伸缩与原来等价的,不需要做归一化,但在模型进行跌代算法的时候,如果看下随着迭代次数,损失值不收敛的话,就需要对数据进行归一化。
4.不需要做归一化处理的算法有哪些
需要做归一化的模型
- 基于距离计算的模型:KNN
- 通过梯度下降法求解的模型:线性回归、逻辑回归、支持向量机、神经网络
不需要做归一化的模型
树形模型不需要做归一化,原因是它只关注输入变量的分布和变量之间的条件概率(熵)。如决策树、随机森林。
5.数据预处理
- 1.缺失值:填充缺失值fillna:
- i. 离散:None,
- ii. 连续:均值。
- iii. 缺失值太多,则直接去除该列
- 2.连续值:离散化。有的模型(如决策树)需要离散值
- 3.对定量特征二值化:核心在于设定一个阈值,大于阈值的赋值为1,小于等于阈值的赋值为0。如图像操作
- 4.皮尔逊相关系数:去除高度相关的列
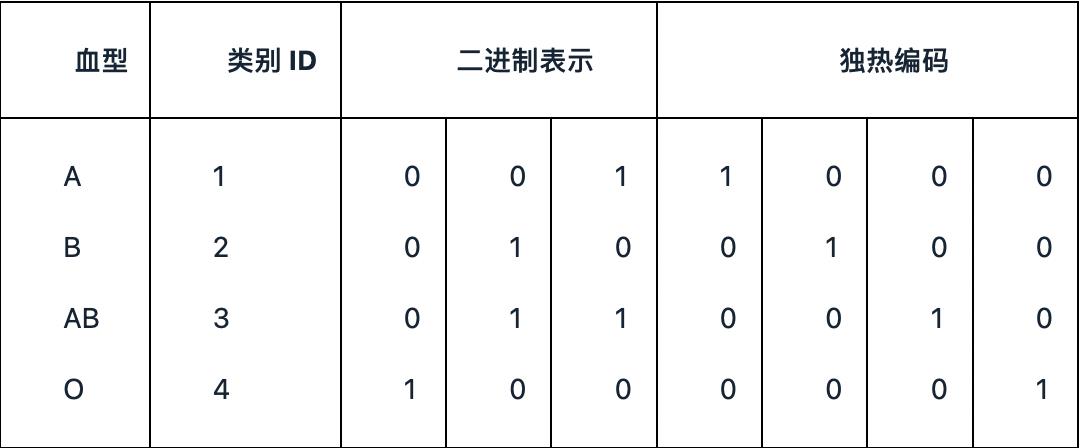
6.类别型特征如何数据处理
类别型特征主要是指像性别(男、女)、血型(A、B、AB、O)这样有限选项的取值特征。
对于这类的数据,除了使用决策树这样的树形模型可以直接处理以外,对于逻辑回归、支持向量机等模型,都需要对数据进行处理
具体处理方法有序号编码、独热编码、二进制编码。
6.1序号编码
使用相应的数字,根据数字大小对应到相应的类别中,比如说成绩的不及格、良好、优秀,可以用1、2、3数字来相应表示。
6.2独热编码
独热编码通常是类别转换成对应稀疏向量,比如血型(A、B、AB、O)
A向量为:(1,0,0,0)
B向量为:(0,1,0,0)
AB向量为:(0,0,1,0)
O向量为:(0,0,0,1)
6.3二进制编码
二进制编码分二步,第一步先用序号编码给每个类别赋予一个类别,然后将类别ID对应的二进制编码作为结果。
7.介绍一下逻辑回归LR
对于逻辑回归模型它其实就是一个真实的二分类器模型,线性分类器。
给定一些数据点,它们分别属于两个不同的类。现在要找到一个线性分类器把这些数据分成两类。
如果用
x
x
x表示数据点,用
y
y
y表示类别(y可以取1或者-1,分别代表两个不同的类),一个线性分类器的学习目标便是要在n维的数据空间中找到一个超平面(hyper plane),这个超平面的方程可以表示为(
w
T
w^T
wT中的
T
T
T代表转置)
w
T
x
+
b
=
0
w^Tx+b=0
wTx+b=0
这里的
y
y
y取1或-1分类标注是源于logistic回归。
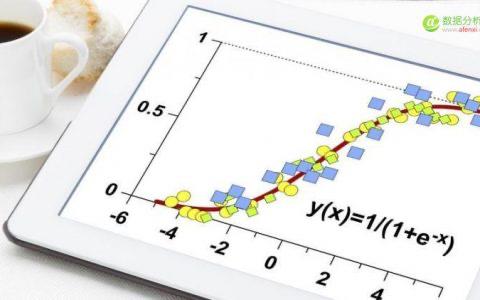
Logistic回归目的是从特征学习出一个0/1分类模型,而这个模型是将特性的线性组合作为自变量,由于自变量的取值范围是负无穷到正无穷。因此,使用logistic函数(或称作sigmoid函数)将自变量映射到(0,1)上,映射后的值被认为是属于y=1的概率。
h ( x ) = g ( w T x ) = 1 1 + e − w T x h(x)=g(w^Tx)=\\frac{1}{1+e^{-w^Tx}} h(x)=g(wTx)=1+e−wTx1
其中命
z
=
w
T
x
z=w^Tx
z=wTx,函数图像如下图所示。
8.逻辑回归与线性回归的区别与联系
第一逻辑回归和线性回归都是广义的线性回归,
其次经典线性模型的优化目标函数是最小二乘,而逻辑回归则是似然函数,
另外线性回归在整个实数域范围内进行预测,敏感度一致,而分类范围,需要在[0,1]。逻辑回归就是一种减小预测范围,将预测值限定为[0,1]间的一种回归模型,因而对于这类问题来说,逻辑回归的鲁棒性比线性回归的要好
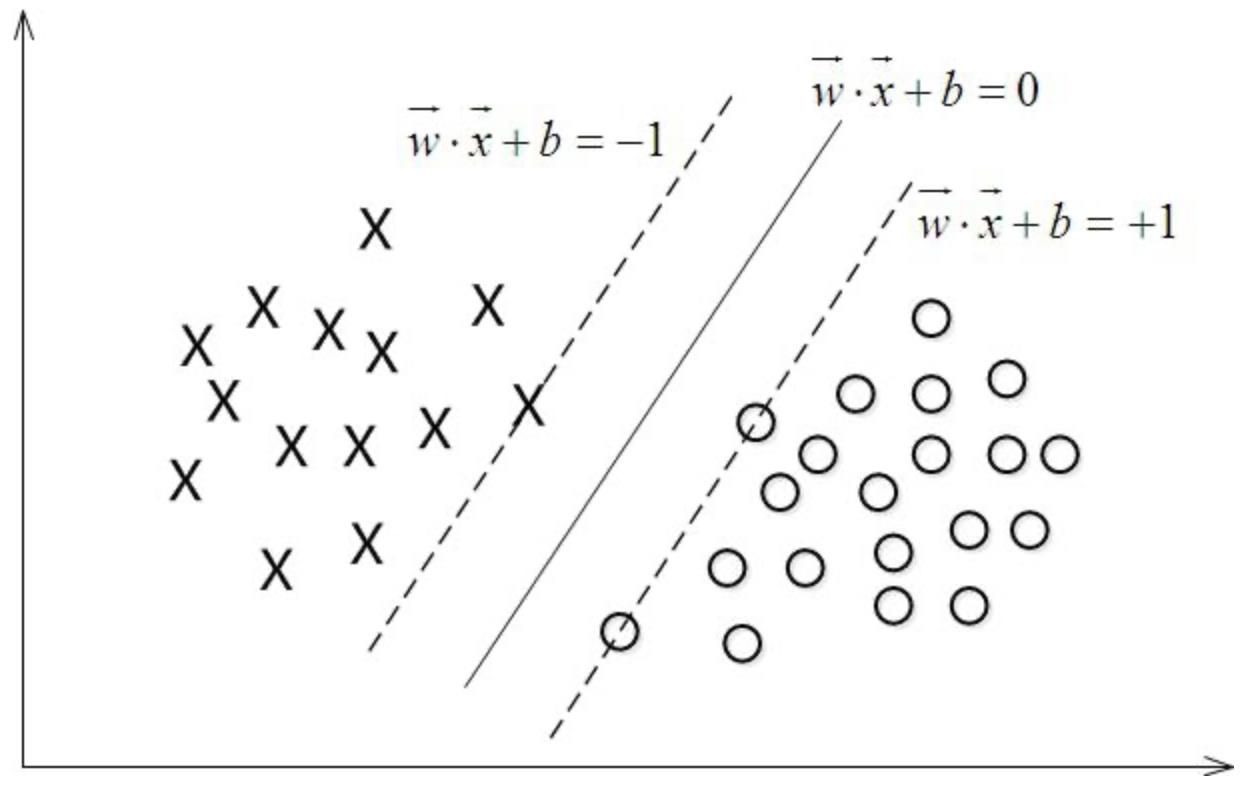
9.SVM原理
对于线性可分的两类点(或多类点),通过一个超平面或多个(三维平面),实现这几类点的完全分开。
其基本模型定义为特征空间上的间隔最大的线性分类器,其学习策略便是间隔最大化,最终可转化为一个凸二次规划问题的求解。
以二分类模型为列,如果用
x
x
x表示数据点,用
y
y
y表示类别(1,-1分别代表两种不同的类),将这样的数据点放入到对应的空间中,对于SVM分类器学习目的就是在这样一个空间中,找到一个超平面使这个超平面到二类数据点之间的距离最大。
这个超平面可以用分类函数
w
T
x
+
b
=
0
w^Tx+b=0
wTx+b=0表示,当f(x) 等于0的时候,x便是位于超平面上的点,而f(x)大于0的点对应 y=1 的数据点,f(x)小于0的点对应y=-1的点,如下图所示:
10.LR与SVM的相同点与不同点
10.1相同点
- 都是线性分类器,都是要求一个最佳的分类超平面
- 都是监督学习算法
- 都是判别模型,判别模型,不关心数据是怎么生成的,它只关心数据之间的差别,然后用差别来简单对数据进行分类。
10.2不同点
- 损失函数不同
LR的损失函数是交叉熵:
J ( θ ) = − 1 m [ ∑ i = 1 m y i l o g h θ ( x i ) + ( 1 − y i ) l o g ( 1 − h θ ( x i ) ) ] J(\\theta)=-\\frac{1}{m}[\\sum_{i=1}^m{y^{i}logh_{\\theta}(x^i)+(1-y^i)log(1-h_{\\theta}(x^i))}] J(θ)=−m1[∑i=1myiloghθ(xi)+(1−yi)log(1−hθ(xi))]
SVM的损失函数是:
L ( w , b , a ) = 1 2 ∣ ∣ w ∣ ∣ 2 − ∑ i = 1 n α i ( y i ( w T x i + b ) − 1 ) L(w,b,a)=\\frac{1}{2}||w||^2-\\sum_{i=1}^n\\alpha_{i}(y_{i}(w^Tx_{i}+b)-1) L(w,b,a)=21∣∣w∣∣2−∑i=1nαi(yi(wTxi+b)−1) - 两种模型对数据和参数的敏感度程度不同,对于SVM模型,在分类边界线附近的数据点对模型的影响更多,对于LR,受所有数据点的影响,模型的好坏依赖于数据分布
- SVM基于距离分类、LR基于概率分类
- SVM损失函数自带正则化,而LR必须格外在损失函数之外添加
11.欠拟合和过拟合如何解决
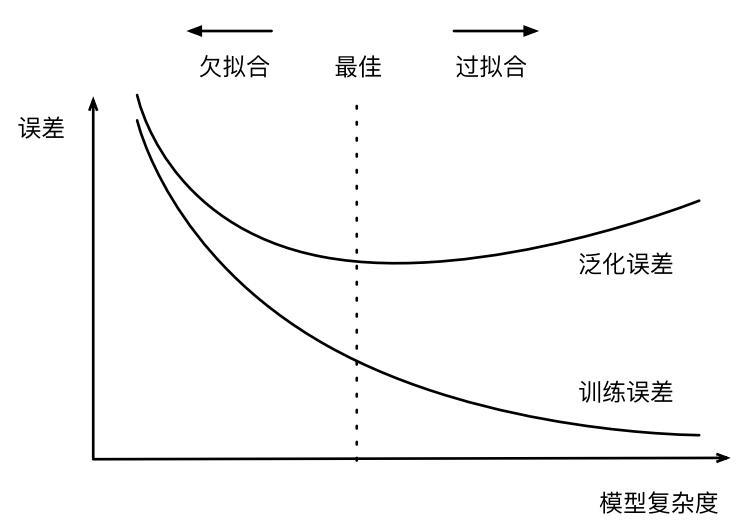
欠拟合与过拟合从直观上看如下图所示,在机器学习项目中,我们不仅要降低训练的误差,同时我们的模型也要用到实际应用中,使实际的误差(泛化误差)较低。由下图看出:
- 随着模型的训练过程进行,模型的复杂度越高,训练误差就低,但是模型在泛化误差上很高(模型做的太专一了,对于其他的数据集它不能很好的适应),这就是过拟合
- 随着模型训练过程进行,模型的复杂度越低,训练误差就低,模型的泛化误差自然就很高。
11.1欠拟合解决方法
- 减少正则化参数
- 尝试使用更高级的模型(如使用SVM、神经网络等)
- 添加其他特征项、添加多项式特征
11.2过拟合解决方法
- 正则化(L1和L2)
- 随机失活(dropout):这个方法主要使用在神经网络中,具体方法让神经网络中部分神经元没有被激活(也就是不使用这部分神经元)。
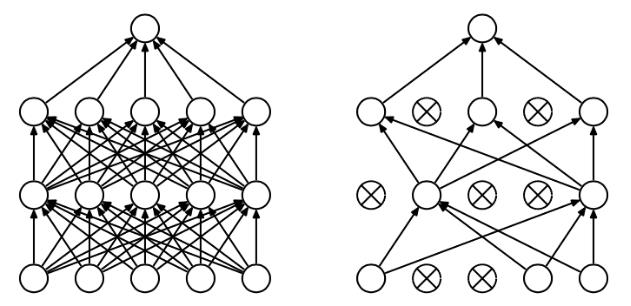
- 逐层归一化:也主要使用在神经网络中,具体方法在神经元每一层输出后,再进行一次归一化。
12.正则化的含义
以线性回归损失函数为列,加入正则化后函数如下:
L
o
s
s
=
1
N
∑
i
=
1
N
(
y
i
−
f
(
x
i
)
)
2
+
r
(
d
)
Loss=\\frac{1}{N}\\sum_{i=1}^N{(y_{i}-f(x_{i}))^2}+r(d)
Loss=N1∑i=1N(yi−f(xi))2+r(d)
其中
1
N
∑
i
=
1
N
(
y
i
−
f
(
x
i
)
)
2
\\frac{1}{N}\\sum_{i=1}^N{(y_{i}-f(x_{i}))^2}
N1∑i=1N(yi−f(xi))2表示全模型的损失函数,
r
(
d
)
r(d)
r(d)表示正则项惩罚复杂模型。
其中,损失函数鼓励我们的模型尽量去拟合训练数据,使得最后的模型会有比较少的 bias。而正则化项则鼓励更加简单的模型。因为当模型简单之后,有限数据拟合出来结果的随机性比较小,不容易过拟合,使得最后模型的预测更加稳定
对损失函数加入正则化的目的是为了防止过拟合,这里就针对不同情况的过拟合问题进行分析。
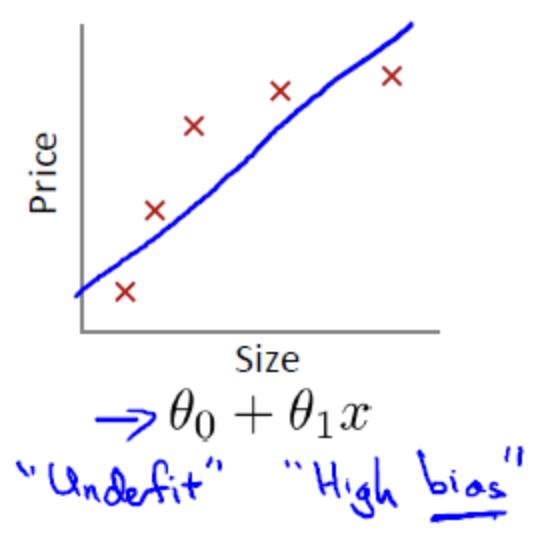
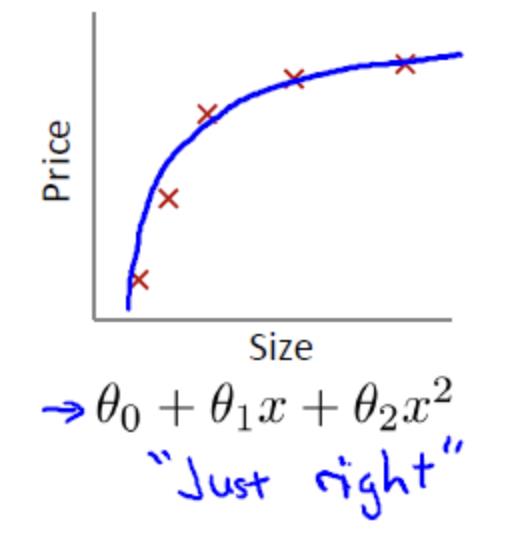
设置size为模型参数个数,price为模型损失值大小
12.1线性回归拟合问题
欠拟合(underifit,也称高偏差high bias)
合适的拟合
过拟合(overfit,也称高方差high variance)
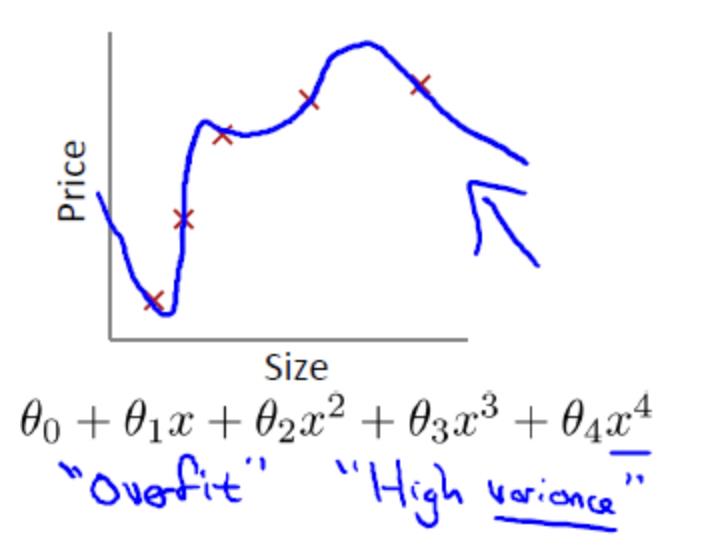
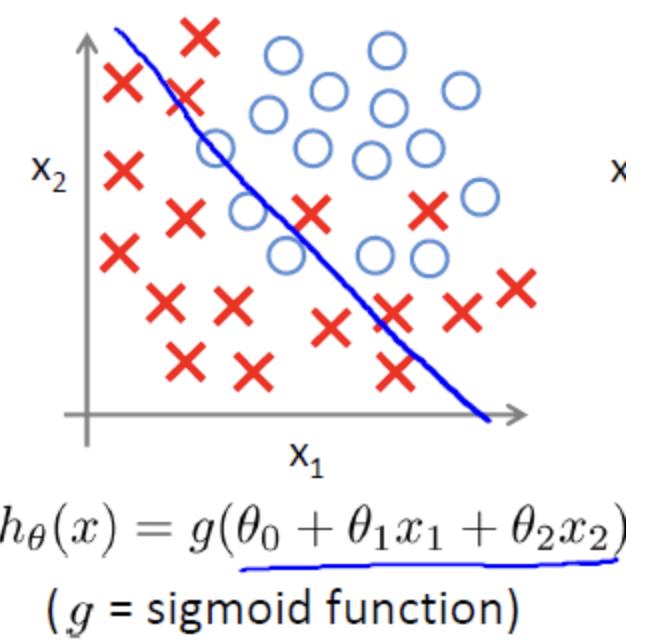
12.2逻辑回归拟合问题
欠拟合
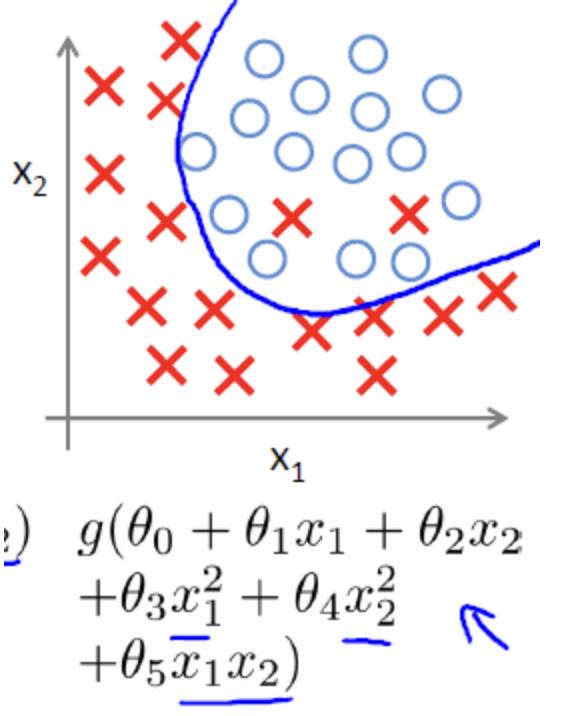
合适的拟合
过拟合
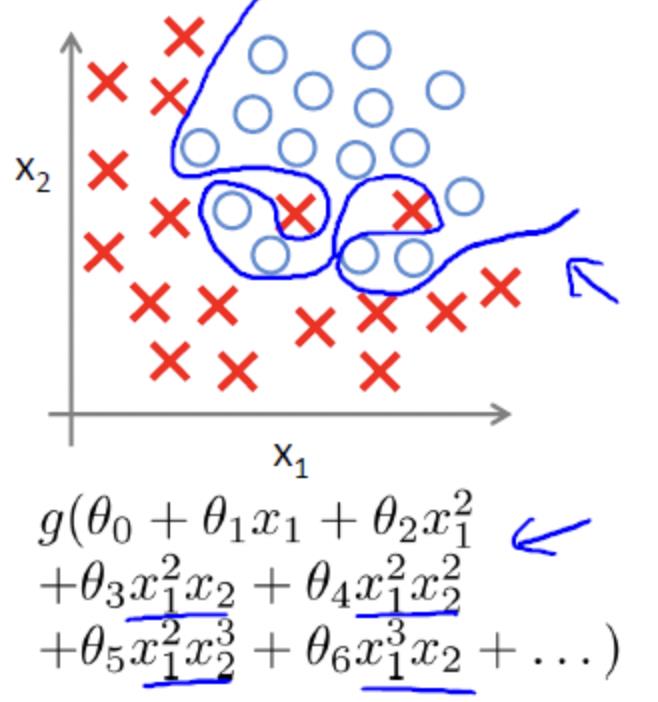
对于解决过拟合问题,通常考虑两种途径来解决:
a) 减少特征的数量:
-人工的选择保留哪些特征;
-模型选择算法
b) 正则化
-保留所有的特征,但是降低参数的量/值;
-正则化的好处是当特征很多时,每一个特征都会对预测y贡献一份合适的力量
13.L1和L2的区别
L1范数(L1 norm)是指向量中各个元素绝对值之和,L2范数(L2 norm)是指向量各个元素平方和的1/2次平方。
比如 向量A=[1,-1,3], 那么A的L1范数为
∣
1
∣
+
∣
−
1
∣
+
∣
3
∣
|1|+|-1|+|3|
∣1∣+∣−1∣+∣3∣。那么A的L2范数为