Training free Transformer Architecture Search
Posted juanpingzhao
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Training free Transformer Architecture Search相关的知识,希望对你有一定的参考价值。
这篇文章简称为TF-TAS, 首次通过Zero Shot NAS方式实现 ViT (Vision Transformer) 结构搜索。
文章作者来自腾讯优图、厦门大学、鹏城实验室等机构,是2022年CVPR的一篇oral论文。
开源代码:https://github.com/decemberzhou/TF_TAS
目录
研究背景
ViT 已经在CV和NLP领域展现出了很优越的性能,但其性能和算力等仍然与模型结构息息相关,因此,研究人员们通过自动搜索的手段去寻找更好的ViT。
在此之前已经有一些通过NAS (Neural Architecture Search)的方式去搜索到性能表现更佳的ViT结构,但是仍然存在以下几方面问题:
- 模型搜索非常耗时,搜索效率不高
- 由于ViT网络结构与CNN的结构存在较大差异,导致上述方法无法直接移植到ViT结构到高效搜索中;
- 因此,有必要研究针对ViT高效搜索的zero-cost score,从而实现Zero Shot NAS 在ViT搜索中的技术突破。
Zero Shot NAS 因其在搜索过程中无需训练模型,在网络结构搜索中表现出了异常高效的搜索特点,个人认为在实际项目中潜力非常大,但这类方法的普适性不够高,通常需要针对不同的模型结构或任务设计不同的zero-cost proxy。
与此同时,针对任何网络结构/任务设计的zero-cost proxy 必须同时满足以下两个条件:
- 必须能够与搜索的目标成正相关关系
- 必须能够加速模型/结构评估效率
本文方法
前人研究表明,ViT模型中存在两个重要的结构,分别是MSA (multi-head self-attention)和MLP (multi- layer perceptron)。作者重点对这两个结构进行分析,试图找到能够量化zero-cost score的评估方式。图2(a)是作者给出的MSA和MLP zero-cost score 和模型精确度一致性评估情况,试验结果显示kentall系数为0.65,因此证明本文提出的代理分数与精确度的一致性是可接受的。

MSA结构分析
从 AutoFormer 搜索空间中随机抽样 5 个 ViT 架构,分析 MSA 和 MLP 对剪枝的敏感性
图2(b)和图2(c)分别是2个ViT模型对pruning的敏感度的分析。不难从这两幅图中看出:MLP对pruning更加敏感,相反地,MSA结构对pruning rate相对不敏感。这也就意味着MSA的权重参数冗余度更高,因此,MSA模块中参数矩阵的秩对网络性能的影响非常重要。
另外,从已有的研究工作中可知:MSA 模块学到的特征表示比较容易存在秩崩溃(rank collapse)的现象。并且随着输入在网络中前向传播和深度的不断加深,ViT 中 MSA 的输出会逐渐收敛到秩为 1、并最终退化为一个秩为 1 的矩阵(每一行的值不变,即多样性出现稀疏的情况)。秩崩溃意味着 ViT 模型效果很差。因此,我们可以通过估计秩崩溃的程度来推测 ViT 模型的效果。
直接计算MSA参数矩阵的秩存在计算量大的问题,这不利于网络结构搜索,也在某种程度上违背了本文的初衷。
为了加速计算,作者利用 MSA 权重矩阵的核范数近似其秩作为多样性指标。理论上,当权重矩阵的 Frobenius 范数(F 范数)满足一定条件时,权重矩阵的核范数可视为其秩的等价替换。具体计算公式为:

上述公式为作者最终给出的第 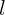 个MSA模块的衡量方式。
个MSA模块的衡量方式。
为了验证 MSA 的突触多样性与给定 ViT 架构的测试精度之间的正相关关系,研究者对从 AutoFormer 搜索空间中采样的 200 个 ViT 网络进行完整的训练,得到其对应的 MSA 模块的分类效果和突触多样性。它们之间的 Kentall’s τ 相关系数为 0.65,如下图 3a 所示。表明 MSA 的突触多样性与每个输入 ViT 架构的效果之间的正相关联系。
MLP结构分析
类似地,图2可以得出结论:MLP模块的冗余度相对较低,因此作者提出用权重参数的敏感度作为zero-cost score的衡量指标,具体的计算公式如下:

DSS-indicator
DSS 指示器是MSA的突触多样性和MLP的显著性综合,具体计算公式为:
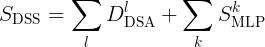
总的来说,TF-TAS的实施步骤依次是:
- 在ViT搜索空间内随机采样若干个子网络(通常会在1000左右,甚至更多)
- 计算采样到的每个子网络的DSS-indicator作为模型精度衡量指标
- 选取DSS-indicator最高的子网作为搜索出的最佳网络
- 重新训练该子网络得到最终模型
- 测试模型精确度
实验验证
数据集
ImageNet, CIFAR10/CIFAR100, COCO2017
搜索阶段
网络权重随机初始化,随机采样8000个子网络,输入为全1的数据,找到DSS-indicator最高的网络结构作为搜索得到的结构。
重新训练阶段
参考AutoFormer的训练配置。
结论
本文提出了面向ViT模型性能评估的DSS-indicator作为zero-cost proxy,实现了无需训练即可搜索的ViT搜索方法。
从结果来看,经过搜索和重新训练之后,模型在保持SOTA精确度的情况下,能够达到约50X的搜索效率提升。这个搜索的效率还是很惊人的,从下图可以看出具体搜索时长对比:24 vs. 0.5 GPU days。
 论文中还有其他实验结果来证明该结论,具体请参考作者原论文。
论文中还有其他实验结果来证明该结论,具体请参考作者原论文。
以上是关于Training free Transformer Architecture Search的主要内容,如果未能解决你的问题,请参考以下文章
论文笔记:Depth-supervised NeRF: Fewer Views and Faster Training for Free
paper 阅读 - BERT: Pre-training of Deep Bidirectional Transformers forLanguage Understanding
paper 阅读 - BERT: Pre-training of Deep Bidirectional Transformers forLanguage Understanding
MoCo v3: An Empirical Study of Training Self-Supervised Vision Transformers
文本分类BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding