论文笔记:Depth-supervised NeRF: Fewer Views and Faster Training for Free
Posted BlueagleAI
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了论文笔记:Depth-supervised NeRF: Fewer Views and Faster Training for Free相关的知识,希望对你有一定的参考价值。
中文标题:深度信息监督的神经辐射场:需要更少的视角并且更快的训练
解决的问题:
- 在缺少视野的情况下,神经辐射场不能拟合正确的几何结构。
创新点
- NeRF的第一步需要对场景图像做SFM(structure from motions),这个过程不光会获得场景间的位姿变换信息,同时会获得一部分特征点的“免费”深度。
- 使用这些深度信息引导NeRF学习场景几何信息。
- 设计了一个损失函数鼓励射线终止位置的分布符合3D关键点。
解决方案
由深度监督的射线终止位置
终止位置分布分析
- 根据NeRF的积分公式,近表面深度为D的图像点的理想射线分布为
δ
(
t
−
D
)
\\delta (t - D)
δ(t−D)
 #### 深度建模及监督
#### 深度建模及监督 - (a) 即便绘制出的体密度在穿过多个物体后可能是多峰的,但终止分布仍会是单峰的。
- (b) 如果在缺乏场景数量的情况下,NeRF有可能学习出多峰(3D结构不清晰)。
- (c ) NeRF 会随着训练视场数增加而更多呈现出单峰趋势(学习了准确的3D结构)。
深度建模及监督
- 将射线遇到的第一个表面位置建模为随机变量 D i j \\mathbb D_ij Dij, 该变量正态分布在COLMAP估计的深度 D i j D_ij Dij周围,方差为 σ ^ i \\hat\\sigma_i σ^i: D i j ∼ N ( D i j , σ ^ i ) \\mathbb D_ij \\thicksim \\mathbb N(D_ij,\\hat\\sigma_i) Dij∼N(Dij,σ^i)
- 最终目标是减少渲染权重和加噪深度分布的KL散度
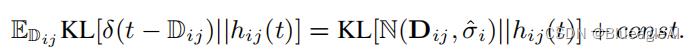
:又称为相对熵,衡量两个概率分布的相似性,用 D K L ( P ∣ ∣ Q ) 表示 D_KL(P||Q)表示 DKL(P∣∣Q)表示,参考机器学习:KL散度详解
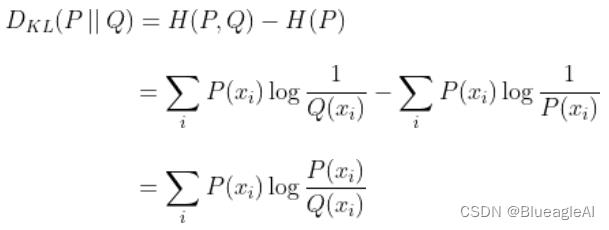
-
射线分布损失

-
List item
参考文献
Deng K, Liu A, Zhu J Y, et al. Depth-supervised nerf: Fewer views and faster training for free[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2022: 12882-12891.
以上是关于论文笔记:Depth-supervised NeRF: Fewer Views and Faster Training for Free的主要内容,如果未能解决你的问题,请参考以下文章