论文解读系列NER方向:FGN (2020)
Posted JasonLiu1919
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了论文解读系列NER方向:FGN (2020)相关的知识,希望对你有一定的参考价值。
文章目录
FGN(2020)
论文地址:
https://arxiv.org/abs/2001.05272
论文代码:FGN
摘要
汉字作为象形文字有其潜在的特殊字形信息,而这一点经常被忽视。FGN是一种将字形信息融入网络结构的中文NER方法。除了用一个新型CNN对字形信息进行编码外,该方法可以通过融合机制提取字符分布式表示和字形表示之间的交互信息。
FGN主要有2个创新点:
- (1)FGN 提出一种新型的CNN结构,即CGS-CNN,以获取字形信息和相邻图之间的交互信息。
- (2)提出一种滑动窗口和注意机制来融合每个字符的BERT表示和字形表示。这种方法可以捕获语境和字形之间潜在交互知识。
FGN在4个中文NER数据集上进行了实验。实验表明,FGN+LSTM-CRF在中文NER上刷新记录。
模型结构
FGN可以分为三个阶段:表示阶段、融合阶段和标记阶段。文章也遵循基于字符的序列标签的策略进行中文NER。
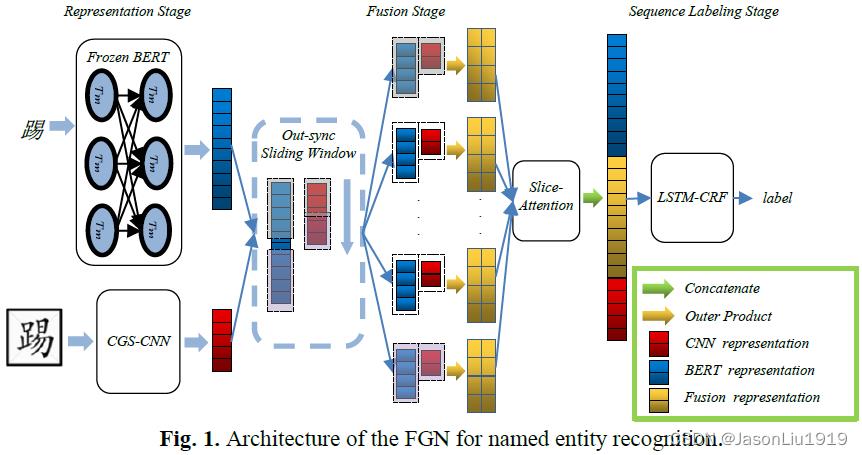
表示阶段
汉字表示主要包括来自BERT的字符表示和基于CGS-CNN的字形表示。这些代表的细节表示方法如下。
BERT:BERT是一个多层Transformer编码器,可以对单词或字符进行分布式表示。文章使用预先训练好的中文BERT来编码句子中的每个字符。与一般的fine-tuning策略不同,首先在train data上对BERT进行微调并使用CRF层作为序列标注器(即tagger)。再冻结BERT的参数并将其转移到FGN中。实验表明这一策略确实有效。
CGS-CNN: Figure 2描述了CGS-CNN的结构。
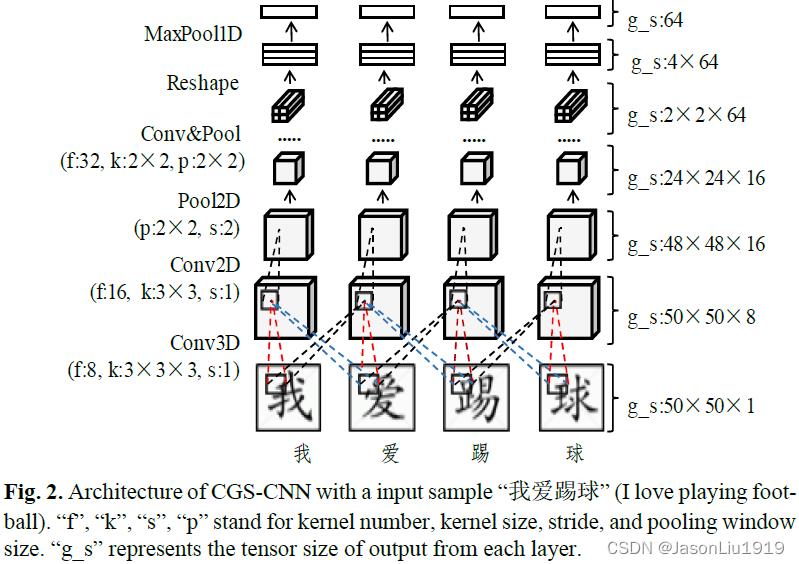
文章只选择简体中文字体来生成字形向量。这是因为之前的学者研究表明,只使用一种中文字体就能达到与七种字体相媲美的性能。CGS-CNN的输入格式是字符图序列。首先将句子转换为图序列,其中每个字符被替换成50×50的灰度图。非中文字符参数矩阵初始化为0到1之间。再使用2个3×3×3的3D卷积层来编码图序列,每个50×50的图输出8个通道,即8个filter。3D卷积可以从空间和时间两个维度上提取特征,这意味着每个字形向量可以从邻近的图形中获得额外的字形信息。使用填充(padding)对图序列的维度进行填充,以确保通过3D卷积后保持图序列的长度不变,这对基于字符的标注任务来说是必要的。3D卷积的输出再过几组2D卷积和2D最大池化,将每个图压缩成64个通道的2×2田字格结构。为了过滤噪音和空白像素,将2×2结构拉平,并使用1D最大池化来提取每个字符的字形向量。字形向量的向量的大小被设定为64,这比Tianzige-CNN输出1024维小得多。与Glyce模型不同,Glyce使用图像分类任务来学习字形表示,而CGS-CNN在领域数据集中训练整个NER模型时学习CGS-CNN的参数。
融合阶段
文章中使用一个滑动窗口来滑动BERT表示结果和字形表示结果。在滑动窗口中,对每个slice pair计算外积(outer product)以捕捉局部的交互特征。再用Slice-Attention来平衡每个slice pair的重要性,并将它们结合起来,输出一个融合表征。
不同步的滑动窗口(Out-of-sync Sliding Window):
滑动窗口此前已被应用于多模态情感计算。使用滑动窗口的原因是,直接用外积融合向量将指数级地扩大向量大小。这会增加后续网络结构的空间复杂性和时间复杂性。同时,这种方法要求多模态表征具有相同的维度尺寸,这不适合同时滑动BERT向量和字形向量。因为BERT的字符表示比字形表示有更丰富的语义信息,需要更大的向量尺寸。文章使用一个不同步(out-of-sync)的滑动窗口以满足不同的向量大小,同时保持相同的slice数。
假设有一个汉字,其字符向量定义为
c
−
v
∈
c_- v \\in
c−v∈
R
d
c
\\mathbbR^d^c
Rdc其字形向量为
g
−
v
∈
R
d
g
g_- v \\in \\mathbbR^d^g
g−v∈Rdg,其中
d
c
d^c
dc和
d
g
d^g
dg分别表示字符向量和字形向量的维度。为确保这两个向量在通过滑动窗口后保持相同数量的slice数,滑动窗口的设置需要满足以下限制:
n
=
d
c
−
k
c
s
c
+
1
=
d
g
−
k
g
s
g
+
1
,
n
∈
N
∗
n=\\fracd^c-k^cs^c+1=\\fracd^g-k^gs^g+1, n \\in \\mathrmN^*
n=scdc−kc+1=sgdg−kg+1,n∈N∗
其中
n
n
n是一个正整数,代表两个向量的slice数;
k
c
k^c
kc和
s
c
s^c
sc分别表示字符向量的滑动窗口大小和stride的大小。
k
g
k^g
kg和
s
g
s^g
sg分别表示字形向量的滑动窗口大小和跨度stride的大小。为满足上述限制文章使用的策略是限制滑动窗口的超参数,使
d
c
d^c
dc,
k
c
k^c
kc,
s
c
s^c
sc分别是
d
g
d^g
dg,
k
g
k^g
kg,
s
g
s^g
sg的整数倍。为了得到slice pairs,首先计算每一步(即一个stride)滑动窗口的左边界索引位置:
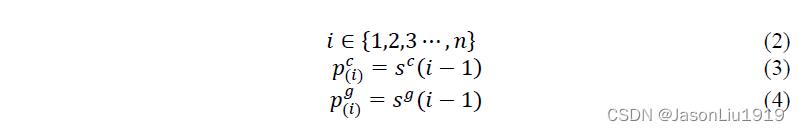
其中 p ( i ) c p_(i)^c p(i)c和 p ( i ) g p_(i)^g p(i)g分别代表字符和字形向量在第 i i i步的滑动窗口的边界索引位置。可以通过以下公式获得每个slice:
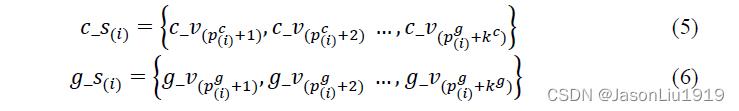
其中为 c − s ( i ) c_- s_(i) c−s(i)和 g − s ( i ) g_- s_(i) g−s(i)分别表示两个向量中的第 i i i个slice。 c − v ( p ( i ) c + 1 ) c_- v_(p_(i)^c+1) c−v(p(i)c+1)表示 c − v c_- v c−v在第 ( p ( i ) c + 1 ) (p_(i)^c+1) (p(i)c+1)个维度的值。为了从局部角度融合两个slice,采用外积法来生成一个交互式张量,如公式所示:
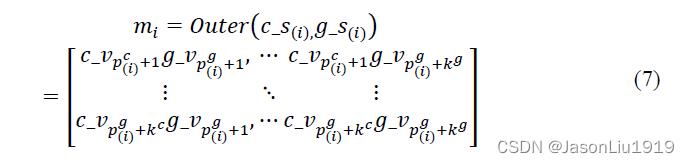
其中 m i m_i mi 表示第 i i i 个slice pair的融合张量, c − v ( p ( i ) c + 1 ) g − v ( p ( i ) g + 1 ) c_- v_(p_(i)^c+1) g_- v_(p_(i)^g+1) c−v(p(i)c+1)g−v(p(i)g+1)表示两者相乘。
再将 m i m_i mi 拉平为 m i ′ ∈ R d c d g m_i^\\prime \\in \\mathbbR^d^c d^g mi′∈Rdcdg。每个字符的 slices 表征可以表示为:
m ′ = m 1 ′ , m 2 ′ , … m n − 1 ′ , m n ′ , m ′ ∈ R n × ( k c c g ) m^\\prime=\\left\\m_1^\\prime, m_2^\\prime, \\ldots m_n-1^\\prime, m_n^\\prime\\right\\, m^\\prime \\in \\mathbbR^n \\times\\left(k^c c^g\\right) m′=m1′,m2′,…mn−1′,mn′,m′∈Rn×(kccg)
其中 m ′ m^\\prime m′ 包含 n n n个slice pairs的融合结果向量,每个向量的维度大小是 k c k g k^c k^g kck