大数据项目之电商数仓-业务数据仓库
Posted _TIM_
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据项目之电商数仓-业务数据仓库相关的知识,希望对你有一定的参考价值。
电商业务流程简介

电商术语
- SKU,库存量单位,即库存进出计量的基本单元,可以是以件,盒,托盘等为单位。SKU这是对于大型连锁超市DC(配送中心)物流管理的一个必要的方法。现在已经被引申为产品统一编号的简称,每种产品均对应有唯一的SKU号。
- SPU,标准化产品单元。是商品信息聚合的最小单位,是一组可复用、易检索的标准化信息的集合,该集合描述了一个产品的特性。
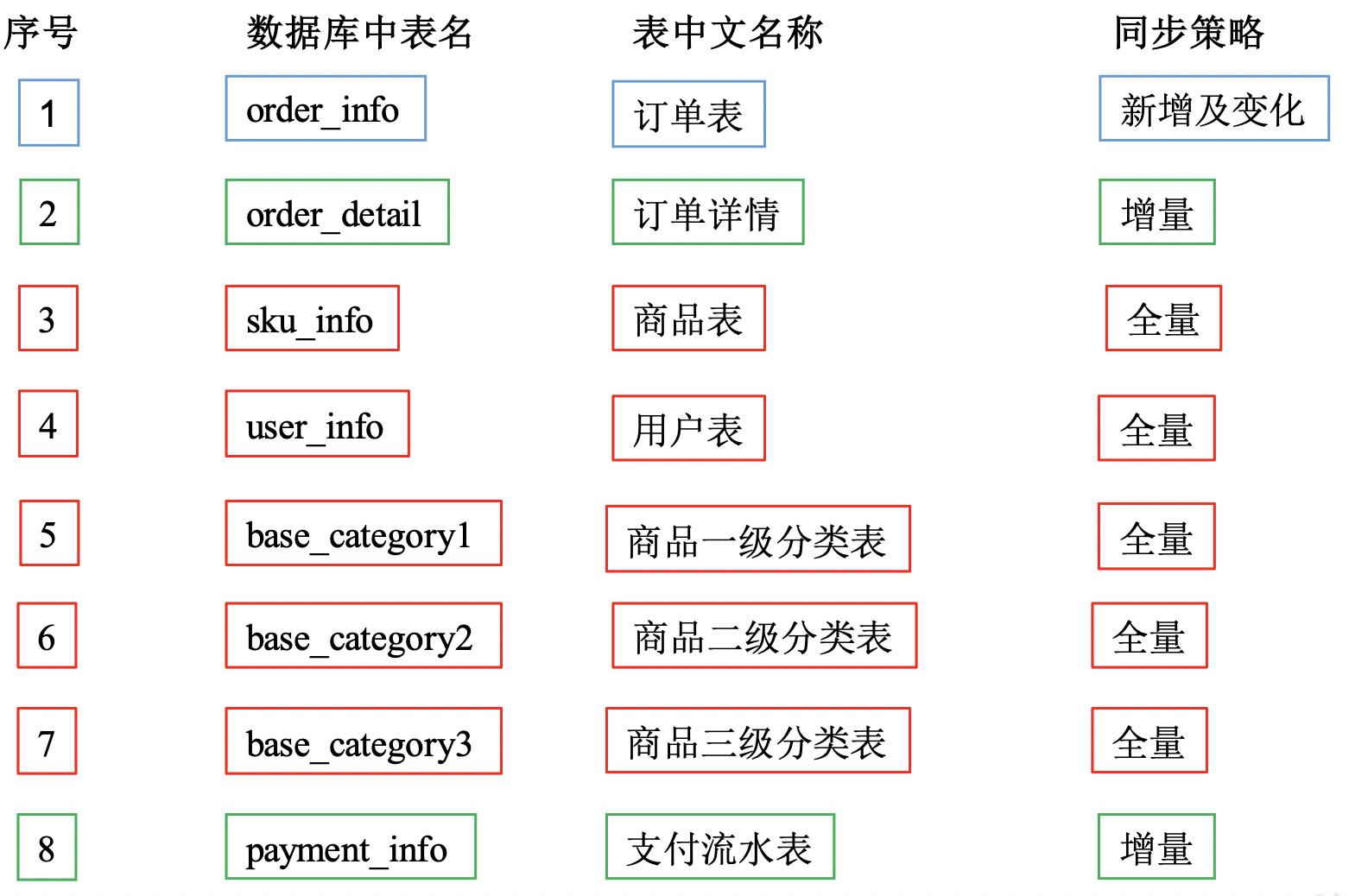
常用的表:订单表、订单详情表、商品表、用户表、商品一级分类表、商品二级分类表、商品三级分类、支付流水表
数仓理论:表的分类
实体表:实体表,一般是指一个现实存在的业务对象,比如用户,商品,商家,销售员等等
维度表:维度表,一般是指对应一些业务状态,代码的解释表。也可以称之为码表。比如地区表,订单状态,支付方式,审批状态,商品分类等等。
事务型事实表:事务型事实表,一般指随着业务发生不断产生的数据。特点是一旦发生不会再变化。一般比如,交易流水,操作日志,出库入库记录等等。
周期型事实表:周期型事实表,一般指随着业务发生不断产生的数据。与事务型不同的是,数据会随着业务周期性的推进而变化。比如订单,其中订单状态会周期性变化。再比如,请假、贷款申请,随着批复状态在周期性变化。
同步策略
数据同步策略的类型包括:全量表、增量表、新增及变化表、拉链表
- 全量表:存储完整的数据。
- 增量表:存储新增加的数据。
- 新增及变化表:存储新增加的数据和变化的数据。
- 拉链表:对新增及变化表做定期合并。
实体表同步策略
实体表:比如用户,商品,商家,销售员等
实体表数据量比较小,通常可以做每日全量,就是每天存一份完整数据。即每日全量。
维度表同步策略
维度表:比如订单状态,审批状态,商品分类
维度表数据量比较小:通常可以做每日全量,就是每天存一份完整数据。即每日全量。
说明:
- 针对可能会有变化的状态数据可以存储每日全量。
- 没变化的客观世界的维度(比如性别,地区,民族,政治成分,鞋子尺码)可以就存一份固定值。
事务型事实表同步策略
事务型事实表: 比如,交易流水,操作日志,出库入库记录等。因为数据不会变化,而且数据量巨大,所以每天只同步新增数据即可,所以可以做成每日增量表,即每日创建一个分区存储。
周期型事实表同步策略
周期型事实表: 比如,订单、请假、贷款申请等
这类表从数据量的角度,存每日全量的话,数据量太大,冗余也太大。如果用每日增量的话无法反应数据变化。每日新增及变化量可以用,包括了当日的新增和修改。一般来说这个表,足够计算大部分当日数据的。但是这种依然无法解决能够得到某一个历史时间点(时间切片)的切片数据。 所以要用利用每日新增和变化表,制作一张拉链表,以方便的取到某个时间切片的快照数据。所以我们需要得到每日新增及变化量。
关系建模与维度建模
关系模型主要应用与OLTP系统中,为了保证数据的一致性以及避免冗余,所以大部分业务系统的表都是遵循第三范式的。维度模型主要应用于OLAP系统中,因为关系模型虽然冗余少,但是在大规模数据,跨表分析统计查询过程中,会造成多表关联,这会大大降低执行效率。所以把相关各种表整理成两种:事实表和维度表两种。所有维度表围绕着事实表进行解释。在维度建模的基础上又分为三种模型:
- 星型模型: 雪花模型和星型模型的区别主要在维度的层级,标准的星型维度只有一层,而雪花模型可能会涉及多级
- 雪花模型: 雪花模型介于关系模型和星座模型之间,比较靠近3NF,但是没法完全遵守,因为性能成本过高
- 星座模型: 星座模型和前两种情况的区别是事实表数量,星座模型是基于多个事实表。基本上是很多数仓的常态,因为很多数仓都是多个事实表,因为星座不星座只反映是否有多个事实表,是否共享一些维度,所以不和前俩模型冲突
星座和雪花的选择取决于性能优先还是灵活性优先,目前开发中不会选择一种而是灵活的组合,甚至并存,整体看来还是更倾向于选择维度更少的星型模型,尤其是Hadoop体系,减少join就是减少shuffle,性能差距大
数仓搭建
业务数据生成(业务流程中产生的登录、订单、用户、商品、支付等相关数据)-> 业务数据导入(Sqoop)-> ODS层(完全仿照业务数据库的表字段,一模一样创建ODS层对应表)-> DWD层(积压ODS层对数据进行判空过滤。对商品分类表进行维度退化(降维)) ->DWS层(用户行为宽表:把每个用户单日的行为聚合起来组成一张多列宽表,以便之后关联用户维度信息后进行,不同角度的统计分析)
拉链表
拉链表记录每条信息的生命周期为单位,一旦记录的生命周期结束,就重新开始一条新的记录,并把当前日期放入生效开始日期,如果当前信息至今有效,在生效结束日期中填入一个极大值。
为什么要做拉链表
- 需要查看某些业务信息的某一时间点当日的信息
- 数据会发生变化,但大部分是不变的,比如订单信息从下单、支付、发货前手等状态经历了一周,大部分时间是不变的
- 数据有一定的规模,无法按照每日全量的方式保存
拉链表的形成过程
- 首先获得某一天的订单全量表最初的订单表作为初始拉链表
- 获取第二天的订单全量表
- 根据订单表创建时间和操作时间,得到订单变化表,并追加有效开始日期和有效结束日期
- 订单变化表和之前的拉链表合并的到最后的拉链表
通过 某个日期<=生效开始日期且某个日期>=生效结束日期,就能获得某个时间点的数据全量切片
拉链表制作流程
订单当日全部数据和mysql中每天变化的数据拼接在一起,形成一个新的临时拉链表数据,用临时拉链表数据覆盖久的拉链表数据
以上是关于大数据项目之电商数仓-业务数据仓库的主要内容,如果未能解决你的问题,请参考以下文章