大数据项目之电商数仓-用户行为数据采集
Posted _TIM_
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据项目之电商数仓-用户行为数据采集相关的知识,希望对你有一定的参考价值。
数据仓库简介
数据仓库是为企业所有决策制定过程,提供所有系统数据支持的战略集合,通过数据仓库中的数据的分析,可以帮助企业改进业务流程、控制成本、提高产品质量等。
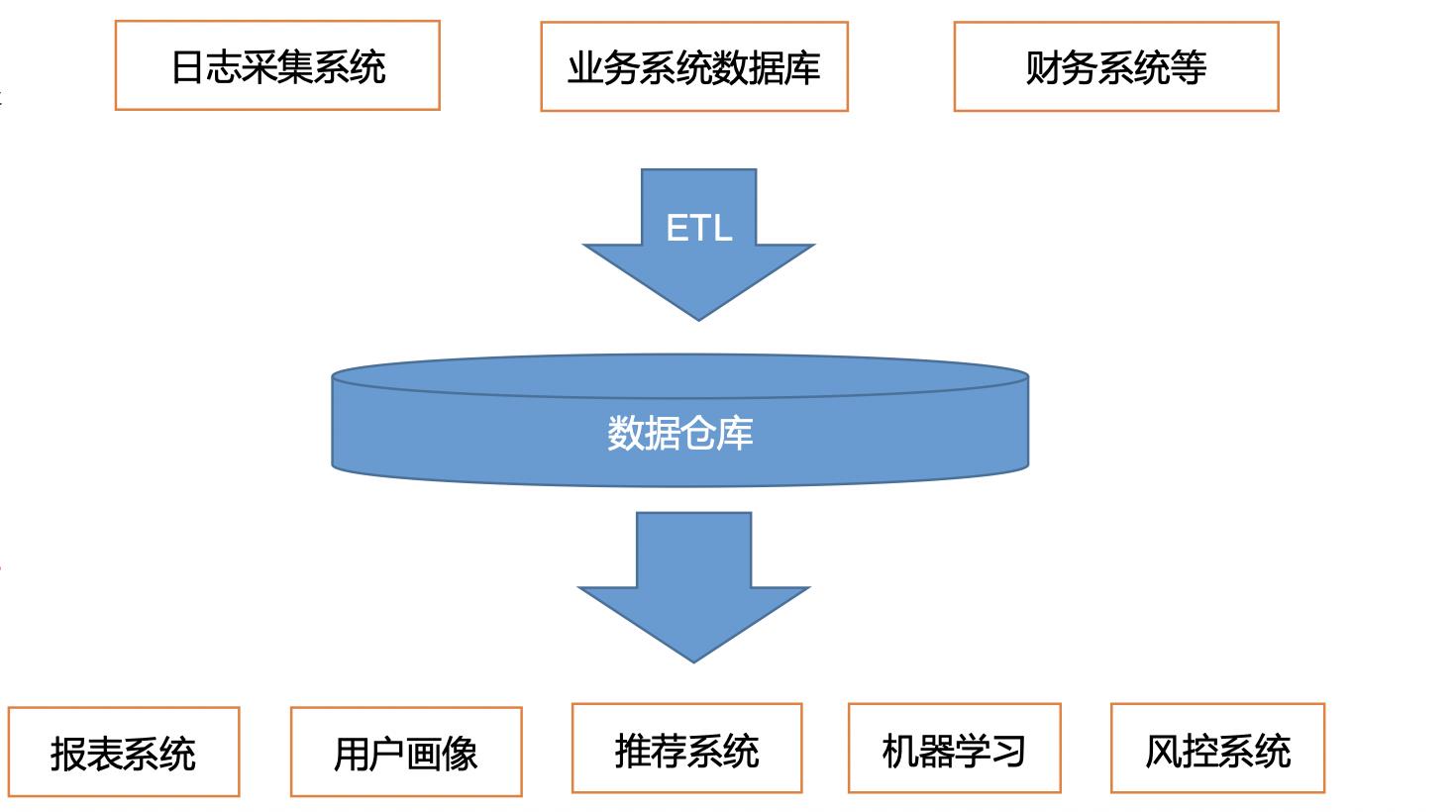
项目需求
- 实时采集买点的用户行为数据
- 实现数据仓库的分层搭建
- 每天定时导入业务数据
- 根据数据仓库中的数据进行报表分析
技术选型角度: 数据采集传输、数据存储、数据计算、数据查询
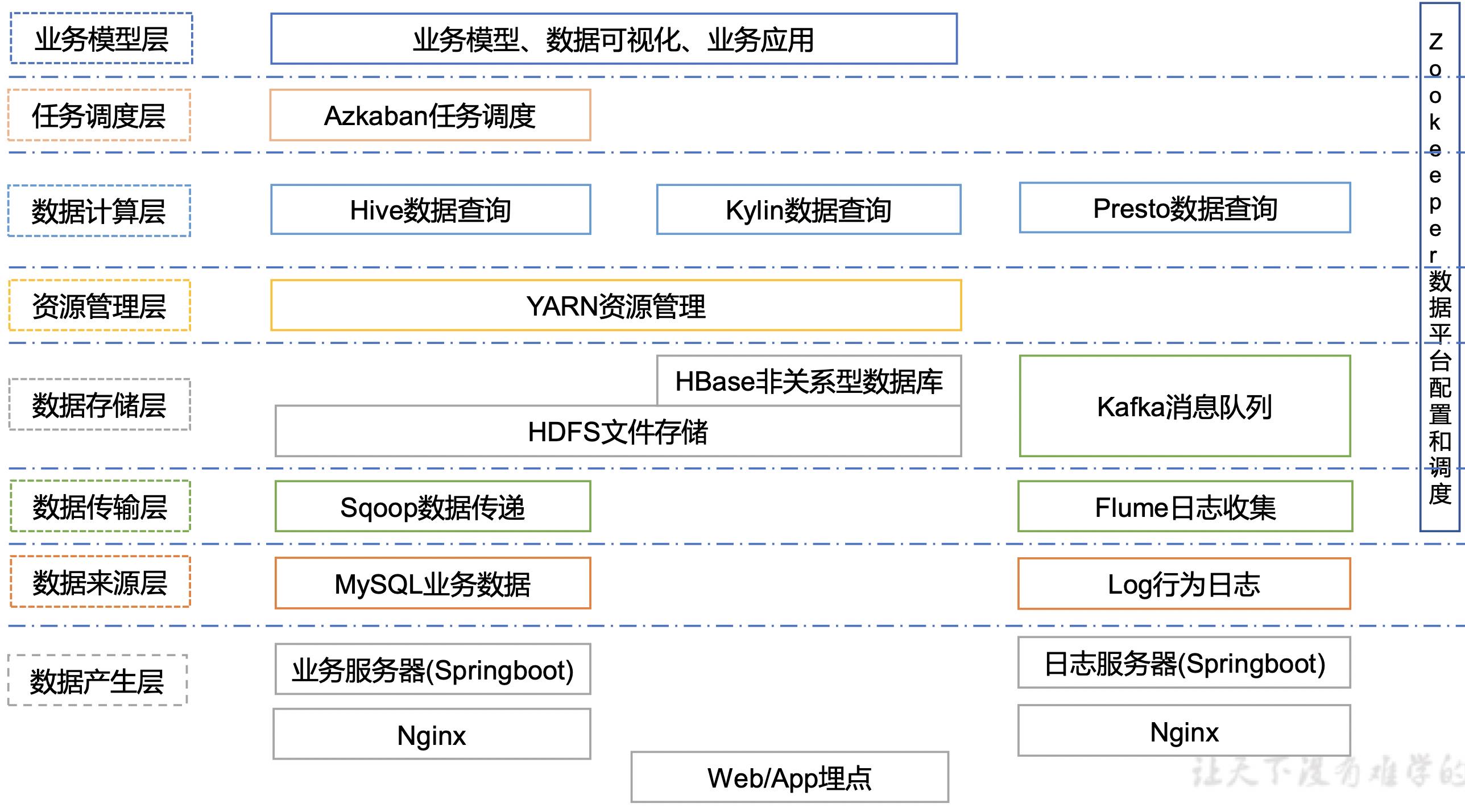
系统架构图设计
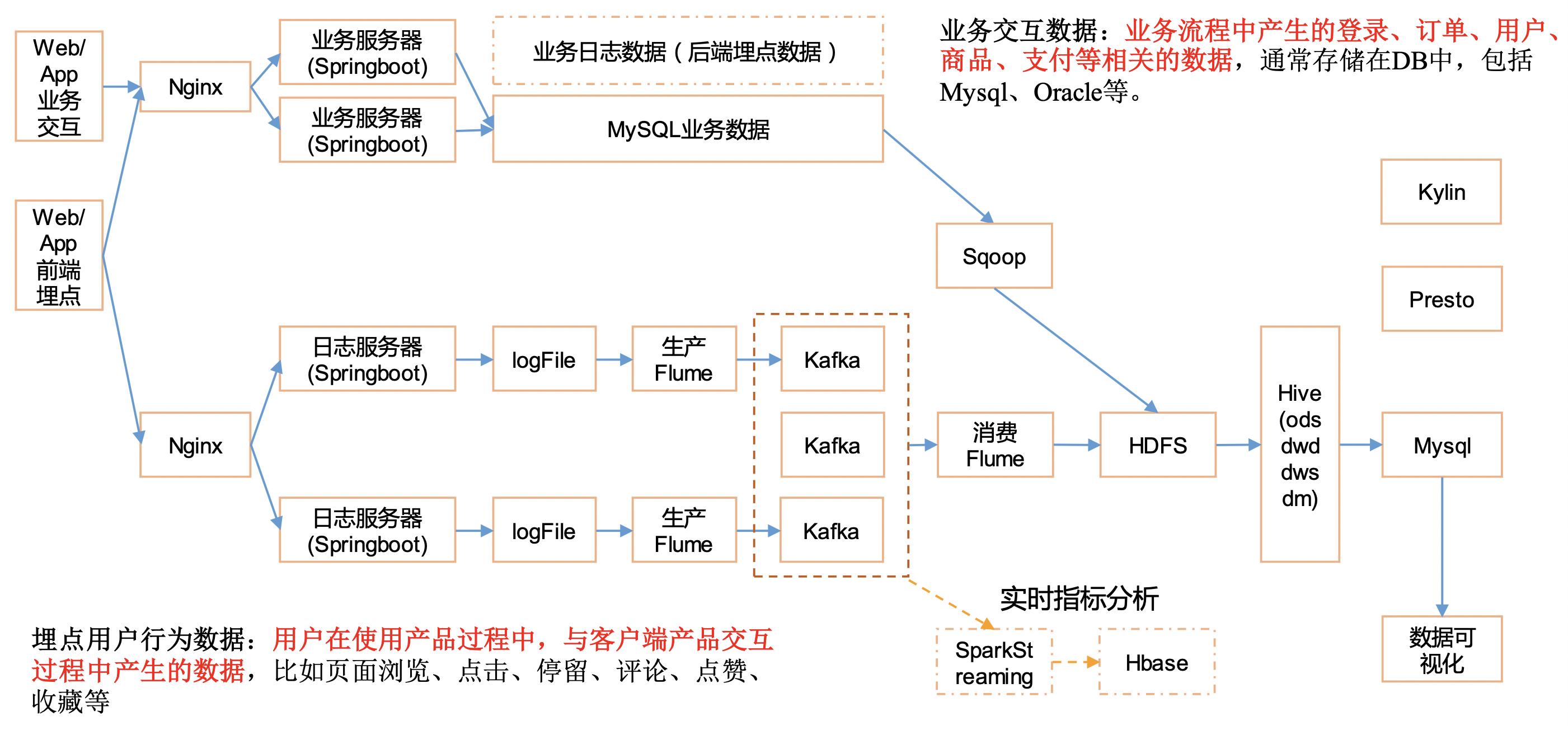
系统数据流程设计
集群资源规划设计
| 服务器一 | 服务器二 | 服务器三 | |
|---|---|---|---|
| HDFS | NameNode、DataNode | DataNode | DataNode |
| Yarn | NodeManager | ResourcemManager、NodeManager | NodeManager |
| Zookeeper | Zookeeper | Zookeeper | Zookeeper |
| Flume(采集日志) | Flume | Flume | |
| Kafka | Kafka | Kafka | Kafka |
| Flume(消费Kafka) | |||
| Hive | HIve | ||
| mysql | MySQL |
买点数据的基本格式
{
"ap":"xxxxx",//产品字段 app key
"cm": { //公共字段
"mid": "", // (String) 设备唯一标识
"uid": "", // (String) 用户标识
"vc": "1", // (String) versionCode,程序版本号
"vn": "1.0", // (String) versionName,程序版本名
"l": "zh", // (String) 系统语言
"sr": "", // (String) 渠道号,应用从哪个渠道来的。
"os": "7.1.1", // (String) android系统版本
"ar": "CN", // (String) 区域
"md": "BBB100-1", // (String) 手机型号
"ba": "blackberry", // (String) 手机品牌
"sv": "V2.2.1", // (String) sdkVersion
"g": "", // (String) gmail
"hw": "1620x1080", // (String) heightXwidth,屏幕宽高
"t": "1506047606608", // (String) 客户端日志产生时的时间
"nw": "WIFI", // (String) 网络模式
"ln": 0, // (double) lng经度
"la": 0 // (double) lat 纬度
},
"et": [ //事件
{
"ett": "1506047605364", //客户端事件产生时间
"en": "request", //事件名称
"kv": { //事件结果,以key-value形式自行定义
"your key1": "your value1",
"your key2": "your value2",
"your key n": "your value n"
}
}
]
}
Flume日志采集
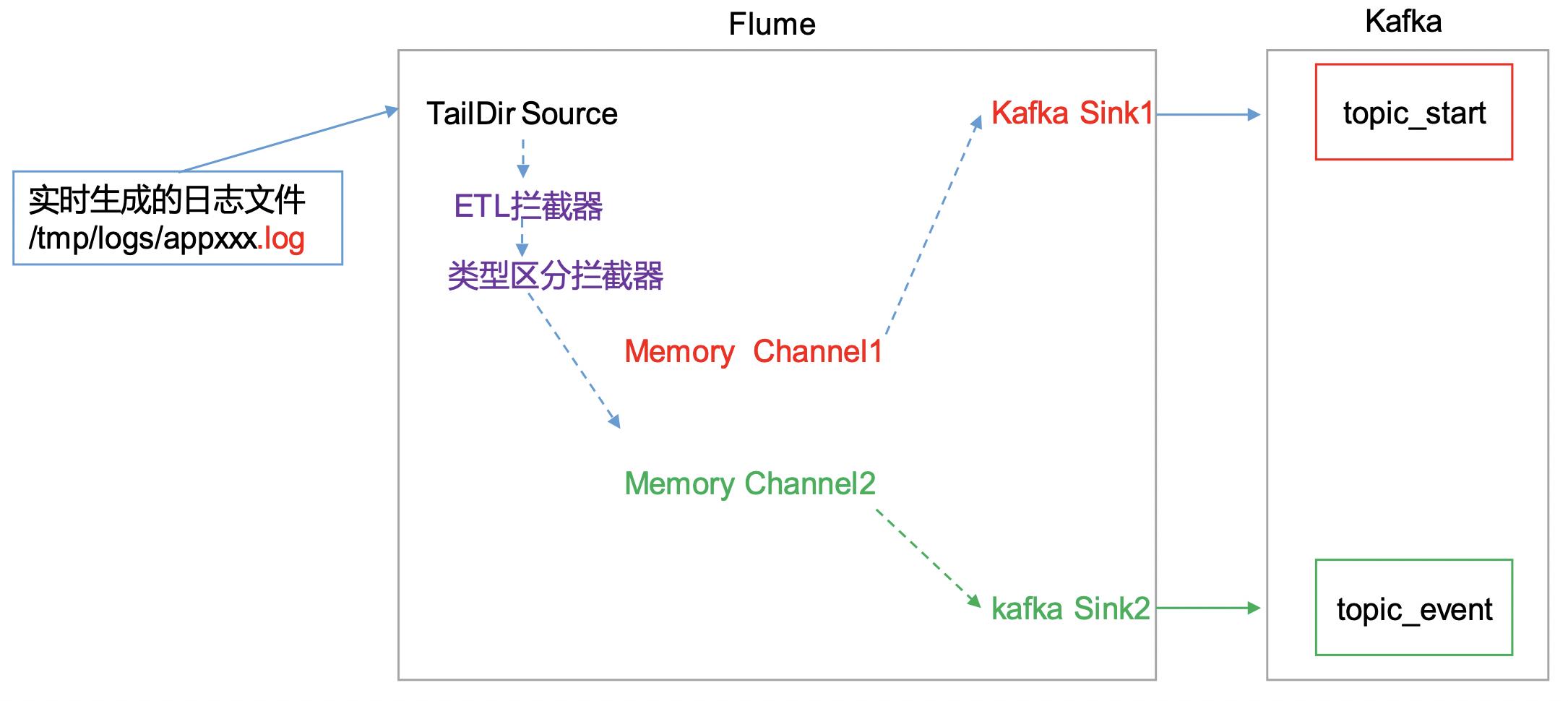
Flume一般都是部署在服务器上,由运维统一配置部署。此处直接读log日志的数据,log日志的格式是app-yyyy-mm-dd.log,可以直接读取。本项目中自定义了两个拦截器,分别是:ETL拦截器、日志类型区分拦截器。
ETL拦截器主要用于,过滤时间戳不合法和json数据不完整的日志。日志类型区分拦截器主要用于,将错误日志、启动日志和事件日志区分开来,方便发往kafka的不同topic。
Flume采集系统组件解析
- Taildir Source
在Flume1.7之前如果想要监控一个文件新增的内容,我们一般采用的source为exec tail,但是这会有一个弊端,就是当你的服务器宕机重启后,此时数据读取还是从头开始,这显然不是我们想看到的! 在Flume1.7没有出来之前我们一般的解决思路为:当读取一条记录后,就把当前的记录的行号记录到一个文件中,宕机重启时,我们可以先从文件中获取到最后一次读取文件的行数,然后继续监控读取下去。保证数据不丢失、不重复。在Flume1.7时新增了一个source的类型为taildir,它可以监控一个目录下的多个文件,并且实现了实时读取记录保存的断点续传功能。但是中如果文件重命名,那么会被当成新文件而被重新采集。
- Channel
- Memory Channel
它把Event保存在内存队列中,该队列能保存的Event数量有最大值上限。由于Event数据都保存在内存中,Memory Channel有最好的性能,不过也有数据可能会丢失的风险,如果Flume崩溃或者重启,那么保存在Channel中的Event都会丢失。同时由于内存容量有限,当Event数量达到最大值或者内存达到容量上限,Memory Channel会有数据丢失。 - File Channel
File Channel把Event保存在本地硬盘中,比Memory Channel提供更好的可靠性和可恢复性,不过要操作本地文件,性能要差一些。 - Kafka Channel
Kafka Channel把Event保存在Kafka集群中,能提供比File Channel更好的性能和比Memory Channel更高的可靠性。
- Memory Channel
- Sink
- Avro Sink
Avro Sink是Flume的分层收集机制的重要组成部分。 发送到此接收器的Flume事件变为Avro事件,并发送到配置指定的主机名/端口对。事件将从配置的通道中按照批量配置的批量大小取出。 - Kafka Sink
Kafka Sink将会使用FlumeEvent header中的topic和key属性来将event发送给Kafka。如果FlumeEvent的header中有topic属性,那么此event将会发送到header的topic属性指定的topic中。如果FlumeEvent的header中有key属性,此属性将会被用来对此event中的数据指定分区,具有相同key的event将会被划分到相同的分区中,如果key属性null,那么event将会被发送到随机的分区中。
- Avro Sink
如何设计kafka集群的大小
Kafka的机器数量
先要预估一天大概有多少数据量,算出峰值是多少数据的速度。然后再去用压测的标准计算一天能承受多少的负载。在上面乘以一个n倍(考虑写一份,存在n倍的同时冗余,ISR,如果我们的冗余是2,那么就是2),就是大概的数据量。数据量我们都是算多少M每秒。一般我们压只压一下写的速度,不让数据在业务层积压。比如我压测测出写入的速度是100M/s一台,峰值的业务数据的速度是200M/s,如果我们追求实时性,那么我们需要(200*2/100=4,然后需要2n+1台,就是9台,能达到实时性)。参数说明:200是峰值速率;2是副本个数,100是经验值。2n+1是经验值Kafka的硬盘大小
Kafka的硬盘大小设置成能至少存一周的数据就可以满足了Kafka的日志留存设置
Kafka的日志留存一般有两种,一种是时间,一种是大小。我们设置至少保留3天的数据量,取中间的最大值。大小和性能并无太大关系,都是O(1) ,所以越大越好。Kafka监控
公司自带的agent部署在每台服务器上面,出现程序奔溃则会报警。负载过高也会报警(磁盘,cpu,内存等)Kakfa分区数
分区数并不是越多越好,一般分区数不要超过集群机器数量。分区数越多占用内存越大(ISR等),一个节点集中的分区也就越多,当它宕机的时候,对系统的影响也就越大。- 分区数和冗余数的设定?
冗余数一般我们设置成2个。根据ISR,分区数的话一般是3个。
日志消费Flume配置
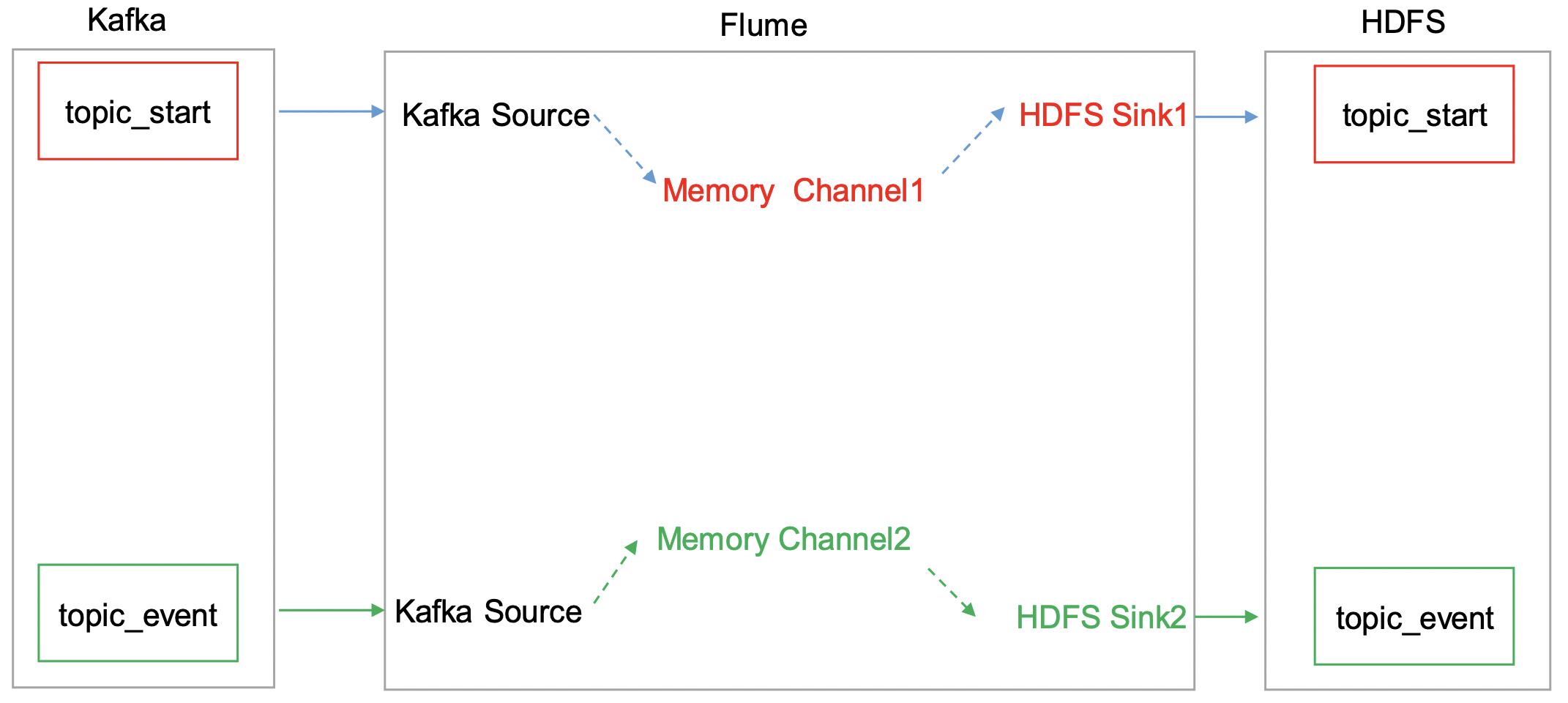
以上是关于大数据项目之电商数仓-用户行为数据采集的主要内容,如果未能解决你的问题,请参考以下文章