AI解数学题,答案是对的过程却是错的?DeepMind新研究改进谷歌思维链方法
Posted QbitAl
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了AI解数学题,答案是对的过程却是错的?DeepMind新研究改进谷歌思维链方法相关的知识,希望对你有一定的参考价值。
羿阁 发自 凹非寺
量子位 | 公众号 QbitAI
AI做数学题的成绩又又又被刷新了!
众所周知,随着谷歌思维链(chain of thought)概念的提出,AI做题时已经能像人类一样生成解题步骤。
这次,来自DeepMind的科学家提出了一个切实的问题:如何确保解题步骤和答案的双重正确率?

为此,他们在GSM8K数据集上全面对比了基于过程和基于结果的监督方法,并结合二者优势训练出一个最佳模型。
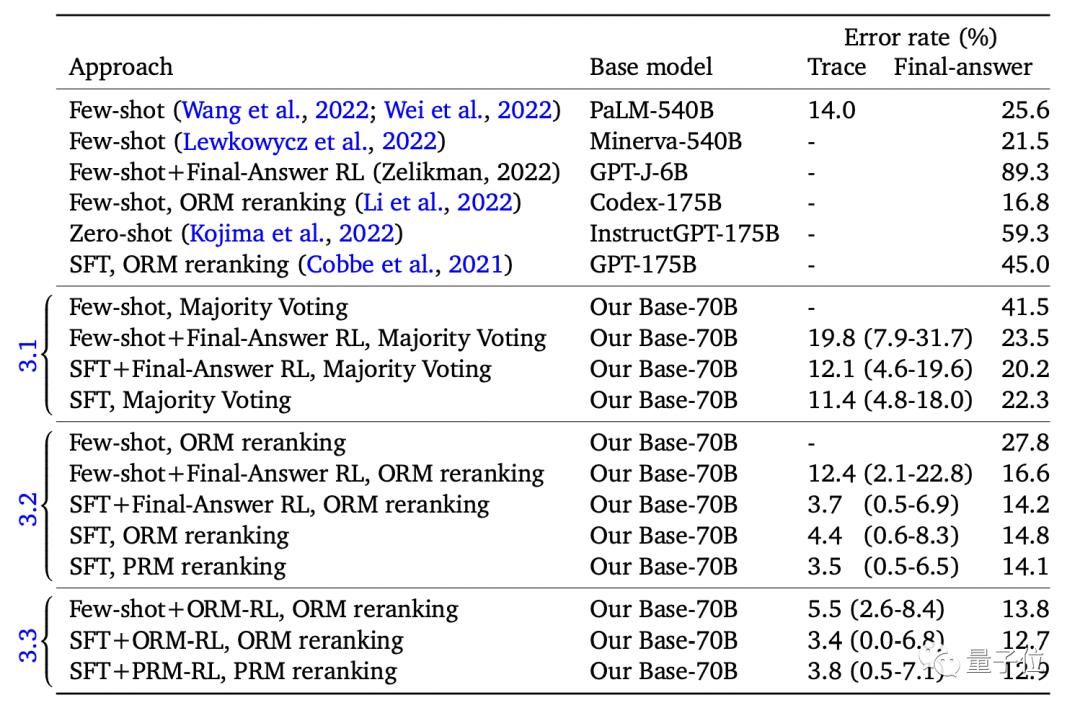
结果表明,新模型的答案错误率从16.8%降低到12.7%,解题步骤的错误率也从14.0%降低到了3.4%。
步骤+答案双重保障
在介绍新研究前,不得不先提到谷歌今年1月在论文中提出的思维链概念。
简单来说,思维链提示就是一种特殊的上下文学习,不同于标准提示只是给出输入-输出对的示例,思维链提示还会额外增加一段推理的过程。

该方法在LaMDA-137B、GPT-3 175B、PaLM-540B三个大型语言模型上都得到了验证:对比标准提示,新方法在一系列算术推理等任务上的准确率都有了明显的提高。
但该方法存在的一个问题是,在某些情况下,AI能生成正确答案,但推理过程却是错误的。
现在,来自DeepMind的研究人员,针对这一点做出了改进:不仅只关注最终结果,也注重推理过程的准确性。
为此,他们对自然语言处理任务中基于过程和结果的方法进行了首次全面比较。
具体来说,包括以下不同场景:少样本提示、有监督的微调、通过专家迭代的强化学习以及重排序和强化学习的奖励模型。

而之所以选择GSM8K数据集,一来因为它是由小学数学应用题组成,答案都是整数解,方便准确性统计;
二是GSM8K数据集具有对推理步骤的离线监督,以及在线人工标注。
从结果上看,第一,基于过程和基于结果的方法在最终答案错误率上近乎一致。这也意味着,仅靠结果监督就足以实现较低的答案错误率。
第二,推理步骤准确率的提升则需要过程监督或模仿它的奖励模型。尽管最终答案错误率相似,但从下图可以看出,结果监督(19.8%)比过程监督(11.4%)的推理错误率明显要高。

除此之外,研究人员还结合二者优势,训练出一个最佳模型,即将监督学习与基于奖励模型的强化学习相结合。
新模型的答案错误率从以前的最佳水平16.8%降低到12.7%,并且,答案正确、推理过程却错误的情况也从14.0%降低到了3.4%。
当允许模型对30%的问题进行回避时,最终答案的错误率甚至能达到2.7%。
研究团队
本篇论文的研究团队来自DeepMind,共同一作有三位:Jonathan Uesato、Nate Kushman、Ramana Kumar。

12月3日,Nate Kushman将会就本篇论文在NeurIPS 2022举办的第二届MATH-AI研讨会上做报告,感兴趣的小伙伴可以蹲守一下~
论文链接:
https://arxiv.org/pdf/2211.14275.pdf
以上是关于AI解数学题,答案是对的过程却是错的?DeepMind新研究改进谷歌思维链方法的主要内容,如果未能解决你的问题,请参考以下文章
在QT中用 QSqlQuery query;查询, 第一次 query.exec();结果是对的,可是第二次执行的时候读的数据是错的